Thanks everyone for this very practical and useful thread so far.
@ramesh and I set up and deployed a minimalist web app demonstrating predictions by an object detection pytorch model trained with the Fast.ai library. We used Flask to set up the app with a /predict API endpoint, Nginx & Gunicorn to manage the app/requests, and Paperspace’s c2 CPU-only instance for hosting.
Here is the demo app for “CocoNet”, the coconut tree aerial object detection model adapted from lesson 9 (pascal-multi):
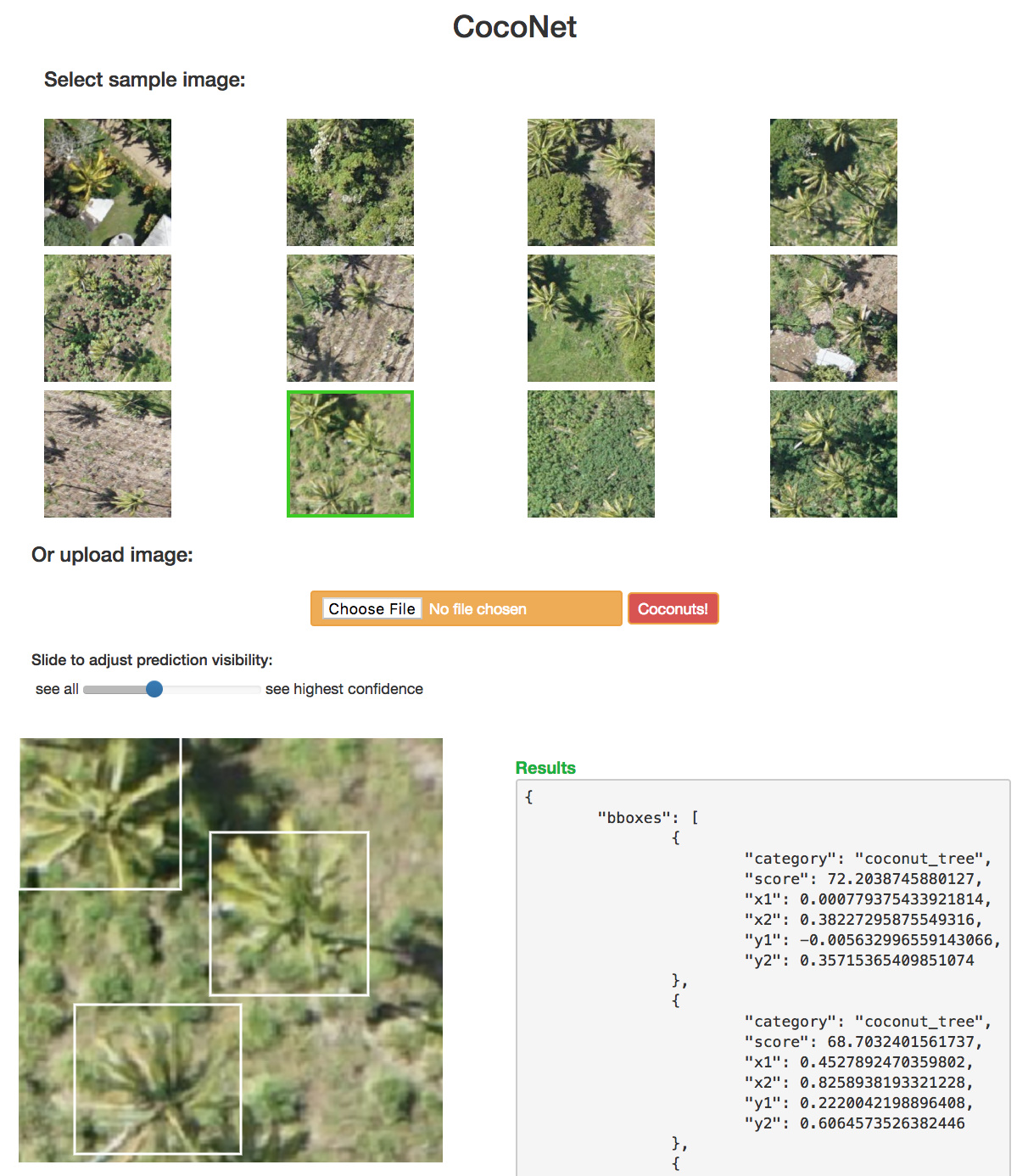
github: https://github.com/daveluo/cocoapp
@ramesh deserves all the credit for setting up flask, conda env requirements, and the very cool idea of drawing prediction bounding boxes using Canvas elements. Canvas lets us avoid generating any SVGs or JPGs. POSTing a sample or uploaded image to /predict returns all of our predictions (class, confidence scores, and bounding box coordinates) in json (seen in the “Results” box) and then we can dynamically draw none, some, or all of the bounding boxes based on a prediction confidence score threshold by adjusting the slider.
We tried to minimize package dependencies so we copied over just the parts we needed from fastai (like functions for val_tfms and model definition) instead of importing the entire library or modules although that is also do-able. Please also note that we haven’t extensively tried all available deployment options or optimized much in any way. We tried to get to a working implementation as quickly as possible and this is the first approach that worked so I’m sure we have much room to learn and tweak!
Here is an overview and some notes about our approach:
-
Train and optimize model using fast.ai library to our liking and/or max performance in jupyter notebook as usual for the class.
- Separate discussion thread about model training
-
Since we’ll be deploying on a CPU-only machine, duplicate and run a CPU-only version of our training notebook to make sure our model and functions needed for prediction don’t have any GPU/cuda requirements. We don’t need to retrain model; just make sure we can load a previously trained and saved model (from
learn.save(),learn.load()) and get the same predictions on a test image with CPU only.- Forum thread on creating a CPU-only conda environment
-
Create a .py module to hold the classes, functions, and variables that define our model by copying over the relevant code cells from our CPU-tested notebook.
- Example: cocomodel.py
-
Test that our model definition .py has everything we need within our CPU-only notebook: use
from cocomodel import *in place of running the copied notebook cells and confirm we are still predicting correctly. -
Repeat the same approach for other needed image processing and utility functions: copy or rewrite code cells from notebook as functions into new .py module -> import module into notebook -> re-run prediction of image using only functions from the imported module.
- Key functions include those to open and transform an image into the pytorch tensor format needed by our model, defining anchor boxes (which could also go into the model definition .py file), non-max suppression of predictions if we want to use it, etc.
- Example: util.py
-
Once we’ve copied our prediction-dependent code to their respective .py modules and tested that imports work correctly, save our model in the notebook as a pytorch .pt file using
torch.save(model, 'filename.pt')andmodel = torch.load('filename.pt')(pytorch doc). Test again that everything works by importing the modules we created, creating a new model loaded from our saved .pt file and making a prediction on a loaded image:
from cocomodel import *
from util import *
learn2 = torch.load('cocomodel_0502.pt')
test_img = open_image(IMG_PATH/'01.jpg')
p_img = preproc_img(test_img)
pr_cl, pr_bb = learn2(p_img)
print(pr_bb)
Variable containing:
( 0 ,.,.) =
1.2554e-01 -1.8171e-02 -3.9333e-02 1.0551e-01
9.2975e-02 4.5186e-02 8.8762e-02 -1.2309e-01
-1.5383e-01 1.9479e-01 -1.3443e-01 1.8663e-01
⋮
1.9889e-01 8.4555e-02 -5.8950e-02 -2.2468e-02
-7.0903e-02 -6.7226e-01 -7.7523e-02 -1.2740e+00
-2.7304e-01 5.3554e-03 -1.1811e+00 -1.4910e-02
[torch.FloatTensor of size 1x9441x4]
- Create
get_prediction()(and associated functions) inutil.pythat flask will need to pass an image from the /predict endpoint, convert it into pytorch format, run prediction through our model, and then convert the predicted outputs back to a display-ready format that flask expects. We want to get back a json-able dict with class, score, and bbox coordinates that are (0,1) relative to image dimensions and (left x, top y, right x, bottom y) so that looks like:
def pred2dict(bb_np,score,cat_str):
# convert to top left x,y bottom right x,y
return {"x1": bb_np[1],
"x2": bb_np[3],
"y1": bb_np[0],
"y2": bb_np[2],
"score": score,
"category": cat_str}
def get_predictions(img, nms=True):
img_t = preproc_img(img)
model = load_model()
#make predictions
p_cl, p_bb = model(img_t)
#convert bb and clas
a_ic = actn_to_bb(p_bb[0], anchors, grid_sizes)
clas_pr, clas_ids = p_cl[0].max(1)
clas_pr = clas_pr.sigmoid()
clas_ids = to_np(clas_ids)
#non max suppression (optional)
if nms: a_ic, clas_pr, clas_ids = nms_preds(a_ic, p_cl, 1)
preds = []
for i,a in enumerate(a_ic):
cat_str = 'bg' if clas_ids[i]==len(id2cat) else id2cat[clas_ids[i]]
score = to_np(clas_pr[i])[0].astype('float64')*100
bb_np = to_np(a).astype('float64')
preds.append(pred2dict(bb_np,score,cat_str))
return {
"bboxes": preds
}
-
Create our flask app. There’s too much to describe it all in detail here so we suggest looking through our repo, tutorials on using Flask to deploy ML models as APIs, and minding these pointers and pitfalls we ran into:
-
torch.save()serializes by default with pickle and has some quirkiness about how module namespaces are saved and needing to explicitly import your model class definitions when unpickling usingtorch.load(). If we didn’t do it right, we would run intoAttributeError: Can't get attribute 'SOME_ATTRIBUTE_NAME' on <module '__main__'>. There are pytorch forum/StackOverflow discussions where the overall recommendation is to usetorch.save(the_model.state_dict(), PATH)instead of saving and loading the whole model. We didn’t do this because we were careful with how we import our modules (thus avoiding the problem) but we will probably try the recommended approach in the future/when refactoring. - If changes you made to flask don’t seem to be appearing when you run the app, check that your browser cache is cleared or disabled. I’ve been frustrated quite a few times with why things weren’t working until I remembered the cache :).
- Here are other lightweight pytorch + flask deployments we looked at for reference:
-
-
At this point, we are able to test our Flask app locally by executing
python run.pyin the terminal and browsing to localhost:5000 (or whichever port you’ve config’ed to). -
To set up the correct package dependencies when deploying outside of our local machine, we relied on Anaconda and .yml files to build a new environment with
conda env create -f environment.yml.- The quickest way to create a .yml file is to activate a conda environment locally where we have our flask app working and export by running
conda env export > NAME_OF_ENVFILE.yml. - However, depending on what else we’re doing with our env, this may end up creating more dependencies than we need to run our app. Another way is that we can create a new env (
conda create -n myenv python=3.6),conda installthe bare minimum packages we know we need (like flask, pip, pytorch), attempt to run the flask app, check which missing package errors pop up, and iteratively install packages until no more errors appear and the app runs successfully. This way, we create an env file that only has what the app needs and no more:
- The quickest way to create a .yml file is to activate a conda environment locally where we have our flask app working and export by running
name: coco-app
channels:
- pytorch
- defaults
dependencies:
- python>=3.6
- pip
- cython>=0.28
- pyyaml
- flask==0.12.2
- torchvision=0.2
- pytorch=0.3.1
- pip:
- opencv-python>=3.4
- gunicorn>=19.8
- To deploy remotely, pick a host of choice. We used Paperspace c2 instance out of familarity but AWS, DigitalOcean, etc should all work. We selected an Ubuntu 16.04 template, installed Anaconda, uploaded our .yml file we created in the last step,
conda env create, waited for everything to download, activate dthe env,python run.py, browsed to the public ip and the correct port, and that’s it, at least for local testing purposes.- We first tried to deploy on Heroku but we couldn’t find a way to get around the slug size limit of 500MB when the pytorch package alone is ~500MB. In retrospect, the free tier of Heroku wouldn’t have worked anyways because it only has 512MB of RAM when we need between 512MB-1GB. So the morale of this story I guess is don’t use Heroku?
- We also needed to install a few random system packages and open up port 5000 in the firewall:
sudo ufw allow 5000
- For more stable deployment, we added Gunicorn and Nginx to handle the Flask app. Here is a great tutorial which we followed without any issue: https://www.digitalocean.com/community/tutorials/how-to-serve-flask-applications-with-gunicorn-and-nginx-on-ubuntu-16-04
So that’s the 12 step plan! Speaking for myself as a newbie, this was my first time using many of these tools (flask, gunicorn, nginx) so I was happy to discover how lightweight and straightforward the deployment process can be. And take another opportunity to restate that this is NOT an exemplar of elegance or efficiency  Thanks again to @ramesh for his expertise, intellectual generosity, and admirable patience in answering every back-to-basics question I had.
Thanks again to @ramesh for his expertise, intellectual generosity, and admirable patience in answering every back-to-basics question I had.
We were surprised there aren’t better online tutorials detailing the pytorch-flask deployment process end-to-end so we plan to write up a blog post (or a series if it gets too unwieldy). Please feel free to ask questions or suggest ways we could have executed or explained something better. I’m sure we forgot to mention crucial details or assumptions at the least. All feedback is helpful and welcomed!