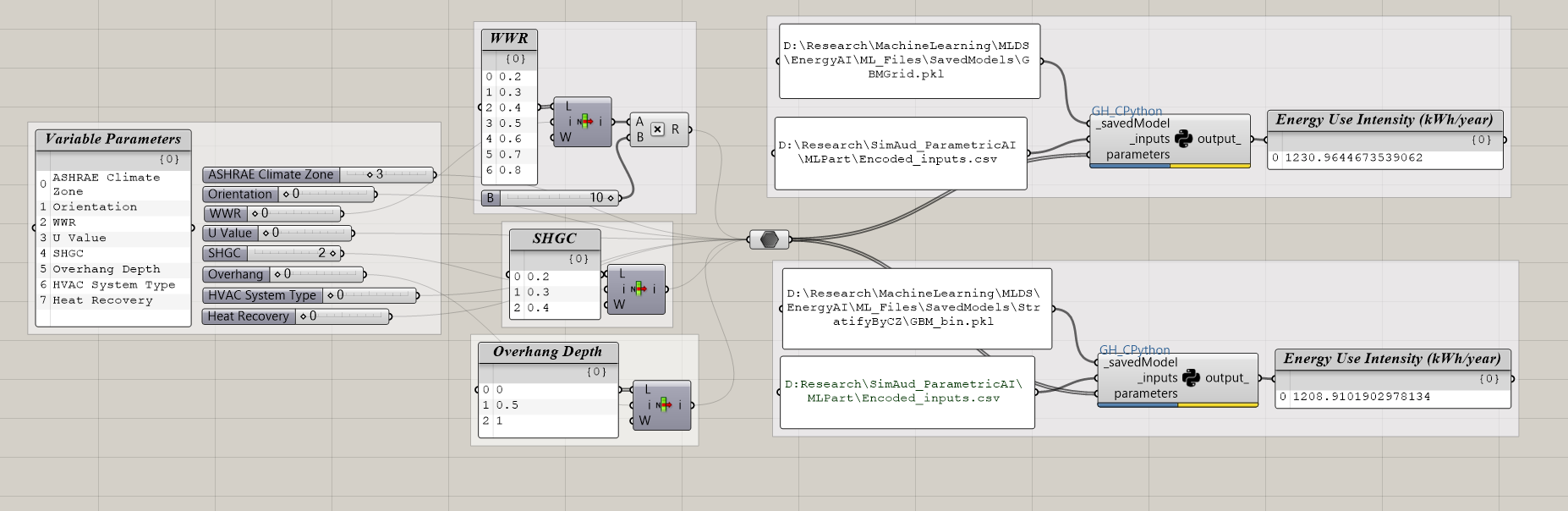
Hi @jm0077,
The Can't pickle local object error you see is related to pickle not being able to serialize the resnext_50_32x4d model creation function (from here) somewhere along the line (probably wherever it’s being called as a lambda function). The middle of this article describes this limitation of pickle: https://medium.com/@jwnx/multiprocessing-serialization-in-python-with-pickle-9844f6fa1812
What did seem to work is using dill instead of pickle to serialize (torch.save enables this through the pickle_module= attribute). Thanks to @ramesh for the offline suggestion to try dill. I did a quick test saving a ConvLearner.pretrained() model with arch=resnext50 using dill and it seemed to save the entire model, load it successfully after restarting the kernel and generate predictions correctly and consistently:
import dill as dill
torch.save(learn.model,'test_resnext50.pt', pickle_module=dill)
I haven’t extensively tested using dill though so can’t promise there won’t be other issues down the line.
If you want to use the 2nd method of saving and loading the weights only, you need to re-initialize your model in the same way you originally defined and created your model when you saved the weights. You have to make sure the variables, classes, functions that go into creating your model are available, whether through module imports or directly within the same script/file.
In the example from my original gist, this looks like:
# model definition stuff
from fastai.conv_learner import *
PATH = Path("data/cifar10/")
stats = (np.array([ 0.4914 , 0.48216, 0.44653]), np.array([ 0.24703, 0.24349, 0.26159]))
bs=256
sz=32
tfms = tfms_from_stats(stats, sz, aug_tfms=[RandomFlip()], pad=sz//8)
data = ImageClassifierData.from_paths(PATH, val_name='test', tfms=tfms, bs=bs)
def conv_layer(ni, nf, ks=3, stride=1):
return nn.Sequential(
nn.Conv2d(ni, nf, kernel_size=ks, bias=False, stride=stride, padding=ks//2),
nn.BatchNorm2d(nf, momentum=0.01),
nn.LeakyReLU(negative_slope=0.1, inplace=True))
class ResLayer(nn.Module):
def __init__(self, ni):
super().__init__()
self.conv1=conv_layer(ni, ni//2, ks=1)
self.conv2=conv_layer(ni//2, ni, ks=3)
def forward(self, x): return x.add(self.conv2(self.conv1(x)))
class Darknet(nn.Module):
def make_group_layer(self, ch_in, num_blocks, stride=1):
return [conv_layer(ch_in, ch_in*2,stride=stride)
] + [(ResLayer(ch_in*2)) for i in range(num_blocks)]
def __init__(self, num_blocks, num_classes, nf=32):
super().__init__()
layers = [conv_layer(3, nf, ks=3, stride=1)]
for i,nb in enumerate(num_blocks):
layers += self.make_group_layer(nf, nb, stride=2-(i==1))
nf *= 2
layers += [nn.AdaptiveAvgPool2d(1), Flatten(), nn.Linear(nf, num_classes)]
self.layers = nn.Sequential(*layers)
def forward(self, x): return self.layers(x)
# initialize model
m = Darknet([1, 2, 4, 6, 3], num_classes=10, nf=32)
learn3 = ConvLearner.from_model_data(m, data)
# load weights
learn3.model.load_state_dict(torch.load('cf10dn_cpuweights.pt'))
In your case, you would create a new learn = ConvLearner.pretrained(...) and load weights with learn.model.load_state_dict().

 Thanks again to
Thanks again to