I followed chapter 4 to understand how to build a handwritten digit classifier.
Using a CNN model i was able to train it and get ~100% accuracy.
However, i tried fetching a picture of handwriting digits from Google and test my model on it, and it failed miserably (100% of the times)
Here is my model
features_to_track = 3
model = torch.nn.Sequential(
# first cnn layer with a 3x3 filter, thus it outputs a tensor of size 26.
# since the image is grayscale, the in_channels is 1.
torch.nn.Conv2d(in_channels=1, out_channels=features_to_track,kernel_size=3,stride=1),
torch.nn.ReLU(),
# max poolin with stride of 2, therefor it downsample by x2 each dim of the image
torch.nn.MaxPool2d(2,2),
torch.nn.Conv2d(in_channels=features_to_track, out_channels=2,kernel_size=3,stride=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=2, out_channels=1,kernel_size=3,stride=1),
torch.nn.ReLU(),
torch.nn.Flatten(),
torch.nn.Linear(in_features=81, out_features=20),
torch.nn.ReLU(),
torch.nn.Linear(in_features=20, out_features=10),
torch.nn.Sigmoid(),
)
loss_fn= torch.nn.CrossEntropyLoss()
optim = torch.optim.SGD(params=model.parameters(), lr=0.001)
epochs = 50
for _ in range(epochs):
for train_img_batch, train_label_batch in train_loader:
# predict
predictions = model(train_img_batch)
# loss
loss = loss_fn(predictions, train_label_batch)
# backward
optim.zero_grad()
loss.backward()
# step (update params)
optim.step()
I’m testing my model with this image, where i cropped each digit, and build this function:
import cv2 as cv
from skimage import io
from google.colab.patches import cv2_imshow
url = 'https://user-images.githubusercontent.com/40036314/48663507-57567a00-eab7-11e8-822e-ac80eace819b.jpg'
image = io.imread(url)
image_2 = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
digits = [
image_2[208:340, 560:660],
image_2[170:320, 120:230],
image_2[200:340, 454:550],
image_2[180:320, 225:360]
]
resized = [cv.resize(d, (28,28)) for d in digits]
tensors = [torch.tensor(d).unsqueeze(0)/255 for d in resized]
fig = plt.figure()
for i, t in enumerate(tensors):
plt.subplot(1,4,i+1)
plt.imshow(t.squeeze(), cmap='gray', interpolation='none')
plt.title(predict(t))
plt.xticks([])
plt.yticks([])
fig
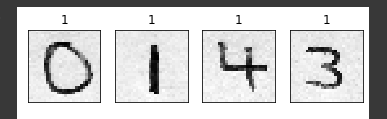
(the number above the digit pic is what my model predicted it’ll be)
if i change the number of epochs, then nothing changes here, except the prediction, but always it predicts the same thing for all digits.
Any idea what’s wrong with my model? how can i debug those things?

 )
)
{kind=link}