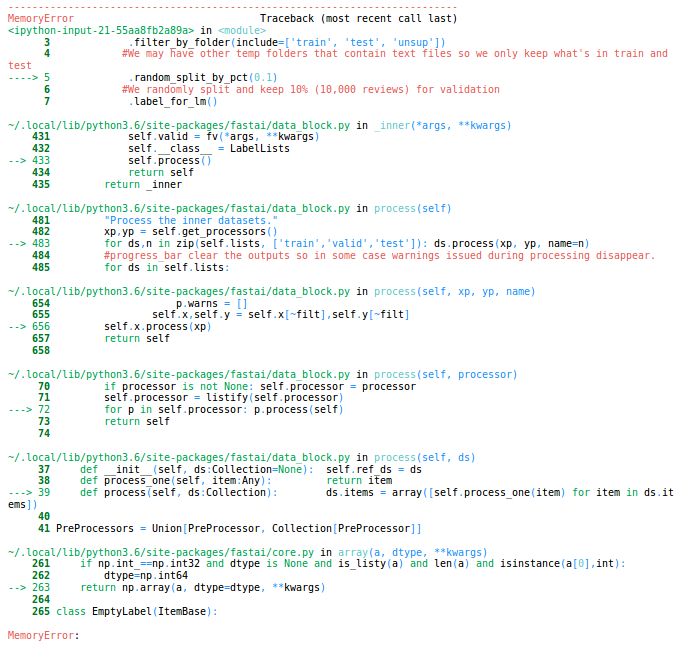
Hi, I’m a newbie using fastai v1. When I run the official guide, there seems an error occurred.
when I ran the code:
from fastai import *
from fastai.text import *
path = untar_data(URLs.IMDB_SAMPLE)
data_lm = TextLMDataBunch.from_csv(path, 'texts.csv')
Then I got the error message:
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-49-9c2ead2e8bda> in <module>()
----> 1 data_lm = TextLMDataBunch.from_csv(path,'texts.csv')
/opt/software/anaconda3/lib/python3.6/site-packages/fastai/text/data.py in from_csv(cls, path, tokenizer, train, valid, test, vocab, **kwargs)
330 "Create a `TextDataBunch` from texts in csv files."
331 header = 'infer' if 'txt_cols' in kwargs else None
--> 332 train_df = pd.read_csv(os.path.join(path, train+'.csv'), header=header)
333 valid_df = pd.read_csv(os.path.join(path, valid+'.csv'), header=header)
334 test_df = None if test is None else pd.read_csv(os.path.join(path, test+'.csv'), header=header)
/opt/software/anaconda3/lib/python3.6/site-packages/pandas/io/parsers.py in parser_f(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, escapechar, comment, encoding, dialect, tupleize_cols, error_bad_lines, warn_bad_lines, skipfooter, skip_footer, doublequote, delim_whitespace, as_recarray, compact_ints, use_unsigned, low_memory, buffer_lines, memory_map, float_precision)
703 skip_blank_lines=skip_blank_lines)
704
--> 705 return _read(filepath_or_buffer, kwds)
706
707 parser_f.__name__ = name
/opt/software/anaconda3/lib/python3.6/site-packages/pandas/io/parsers.py in _read(filepath_or_buffer, kwds)
443
444 # Create the parser.
--> 445 parser = TextFileReader(filepath_or_buffer, **kwds)
446
447 if chunksize or iterator:
/opt/software/anaconda3/lib/python3.6/site-packages/pandas/io/parsers.py in __init__(self, f, engine, **kwds)
812 self.options['has_index_names'] = kwds['has_index_names']
813
--> 814 self._make_engine(self.engine)
815
816 def close(self):
/opt/software/anaconda3/lib/python3.6/site-packages/pandas/io/parsers.py in _make_engine(self, engine)
1043 def _make_engine(self, engine='c'):
1044 if engine == 'c':
-> 1045 self._engine = CParserWrapper(self.f, **self.options)
1046 else:
1047 if engine == 'python':
/opt/software/anaconda3/lib/python3.6/site-packages/pandas/io/parsers.py in __init__(self, src, **kwds)
1682 kwds['allow_leading_cols'] = self.index_col is not False
1683
-> 1684 self._reader = parsers.TextReader(src, **kwds)
1685
1686 # XXX
pandas/_libs/parsers.pyx in pandas._libs.parsers.TextReader.__cinit__()
pandas/_libs/parsers.pyx in pandas._libs.parsers.TextReader._setup_parser_source()
FileNotFoundError: File b'/home/jiangtao/.fastai/data/imdb_sample/train.csv' does not exist
Can anyone tell me what’s going on and how to fix it?