This is the error thrown:
cannot identify image file <_io.BufferedReader name=‘data/bears/teddies/00000035.jpg’>
Is this normal?
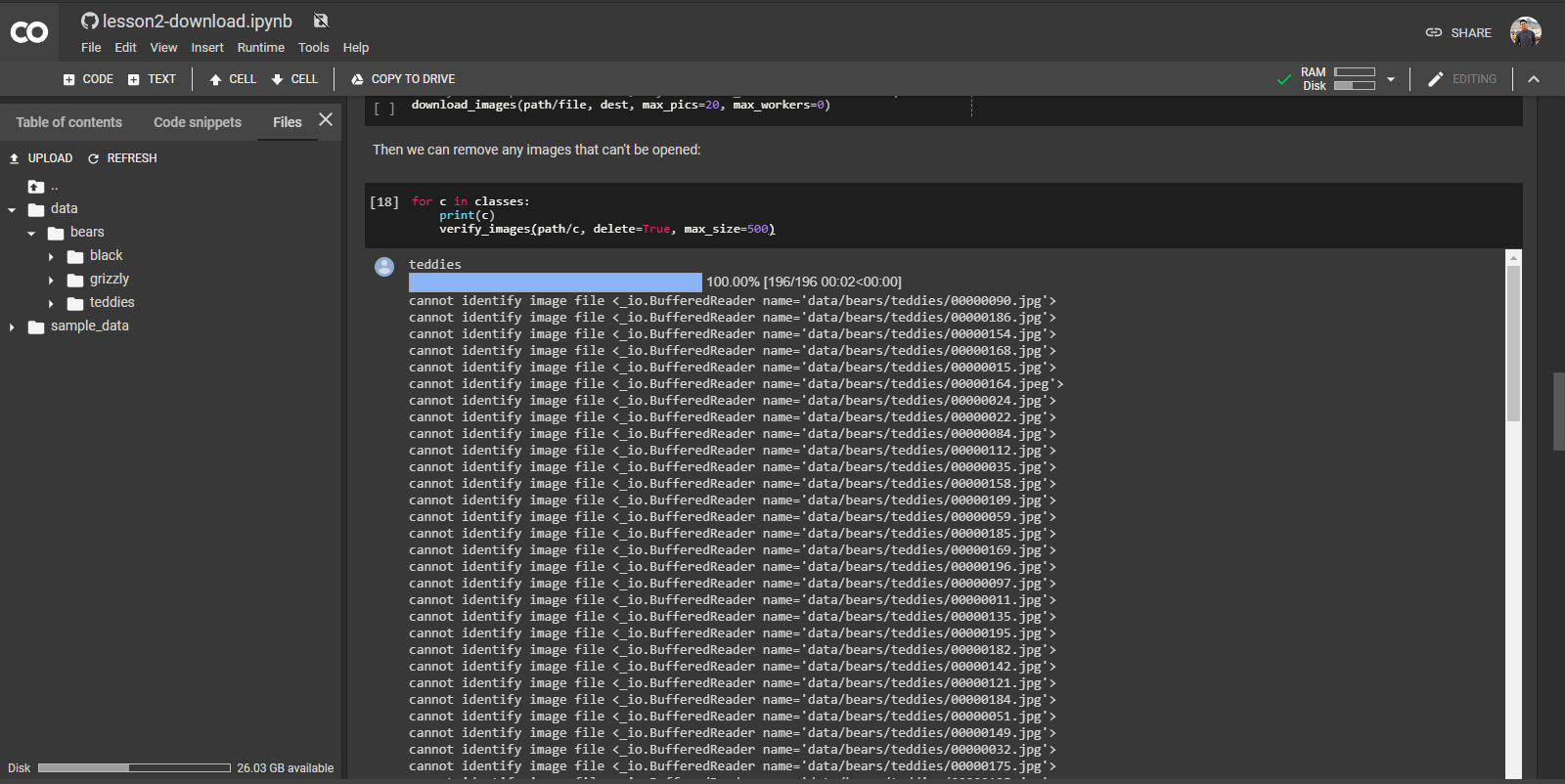
I’ve had trouble with images (from google for example) that have either unexpected formats or corrupted. Here are a couple of tools to consider using:
-
Python Module - imghdr. ‘imghdr.what(f)’ returns the image format.
-
JPEG Library- jpeginfo - jpeginfo. Install on Ubuntu with ‘apt-get install jpeginfo’ This allows for in-place identification and/or filtering of files.
Both tools are very easy to use at CLI or in scripts.
There are probably other approaches, but this is what I have used.
1 Like
I used Excel to convert the .txt file to .csv. It works but about 10-15% of the urls are always discarded because they are either corrupted/of unexpected format. Thank you for your suggestions. I’ll give those a try.