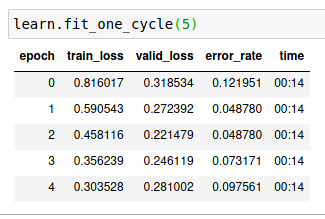
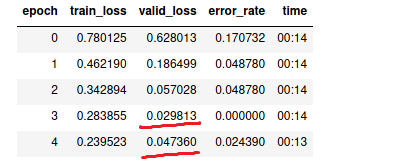
The Lesson 2 video says that training loss should NEVER be higher than validation loss. However, my error loss is at zero. A screenshot of my fit_one_cycle() results is there. Does this indicate some other issue that may exist or should I not be worried?
This is my first notebook, I went ahead and pushed it to GitHub. It detects whether or not someone is wearing a face mask or not.
Loving fast.ai, its very accessible and looking forward to completing all the lessons.
Have you tried running it again? Usually every time you run you get a different result due to randomization. Find out if this is a consistent occurrence or just a one off.
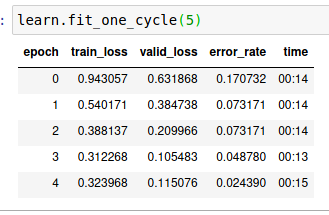
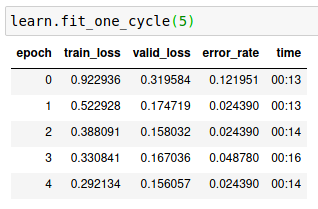
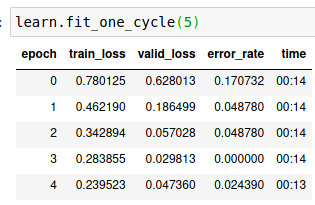
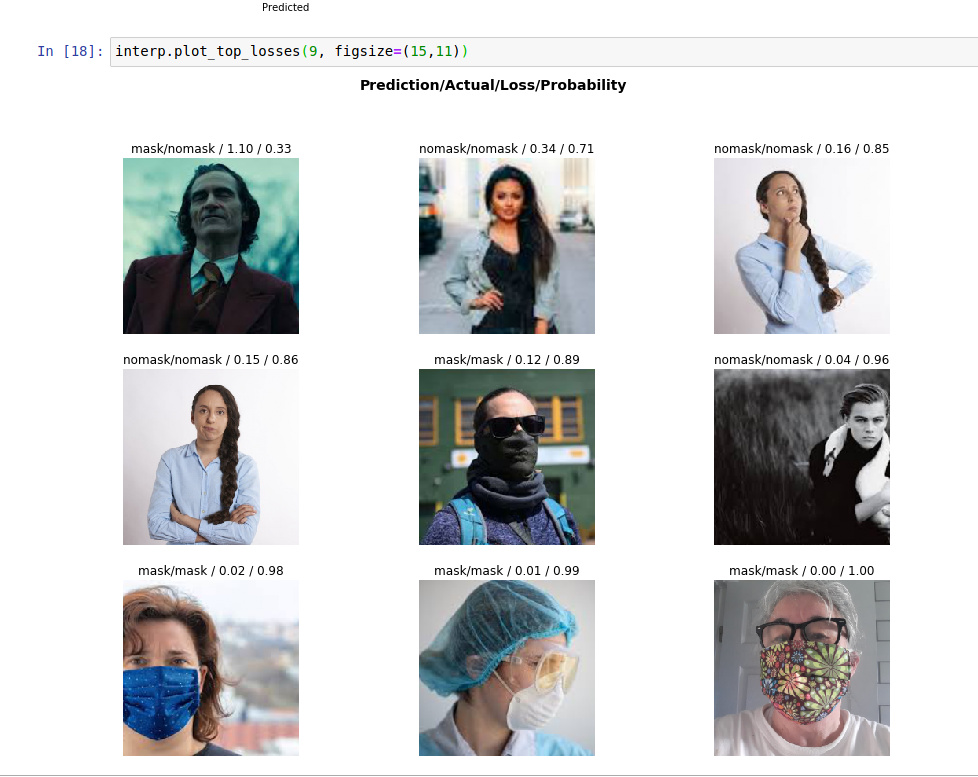
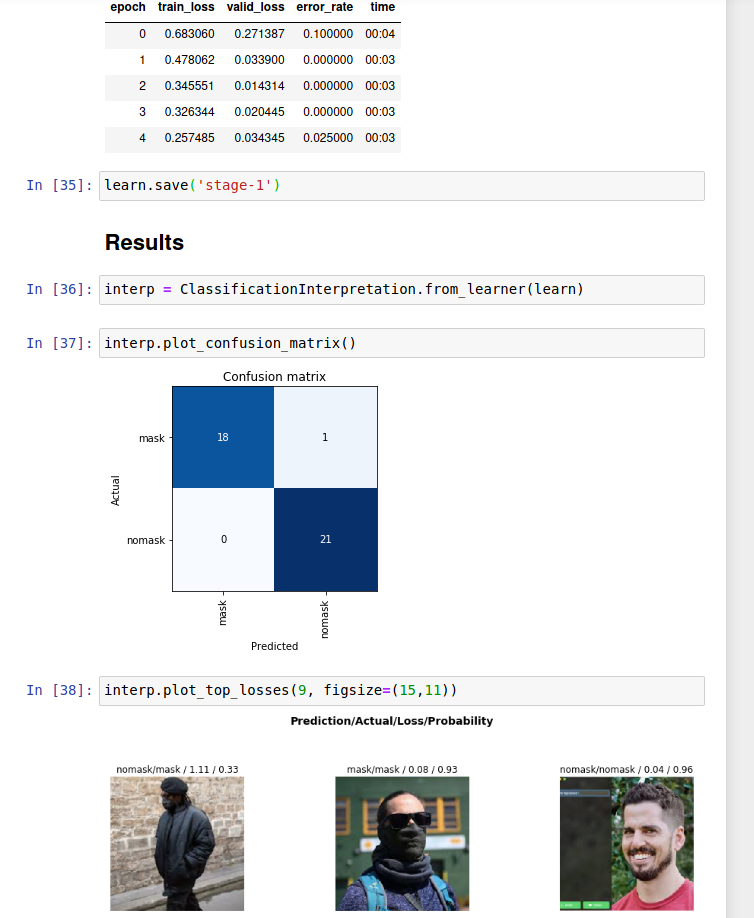
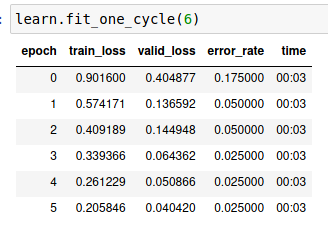
Here is 4 more runs. You can see the last one got to zero error rate as well, but didn’t stay there. Curious as to why the results here aren’t more consistent? Although, three of these below all ended at 0.024390 error, that’s good. There is one image in particular ( row 1 col 2 in the last screenshot below) that seems to always be present in the top loss list. After writing this and the screenshots I noticed 7 duplicates in my nomask label.
Actually, I had some bad labels. One was in there as a mask but the person had no mask. Also I had a photo with two people (no mask) that were kissing (which Im sure confused it). With that cleaned up and the dupes removed I get very consistent results now. And you can see with the first one in the top losses that I probably need even more labels, the mask is so dark and his skin (plus the angle/distance) that it needs a larger training set.
Changing the seed helps surface some issues. I found another one with a mask where the persons hand is over the front of the mask. Interesting though, kind of like a passport photo, there needs to be rules.
However, the original question is still there, the train loss is still higher than the valid loss.
Yes I am very confused by that as well. It would be a bit hard, but possible to modify the function so you can see the losses prior to 1st epoch (prior to any training). If the validation is not somehow biased the losses should be close to one another.
This was happening to me as well in a tabular model a few days ago. Different groups of people with different random splittings in the same dataset were consistently seeing a valid_loss lower than the train_loss. It’s hard for me to find an intuition of why that is happening, aside from a bias in the splits.
Just a little suggestion,
I see the valid_loss got doubled. Do you mind to post the loss.plot to see the graph of both training loss and valid loss?
Maybe you dataset to too small or overfitting little bit.