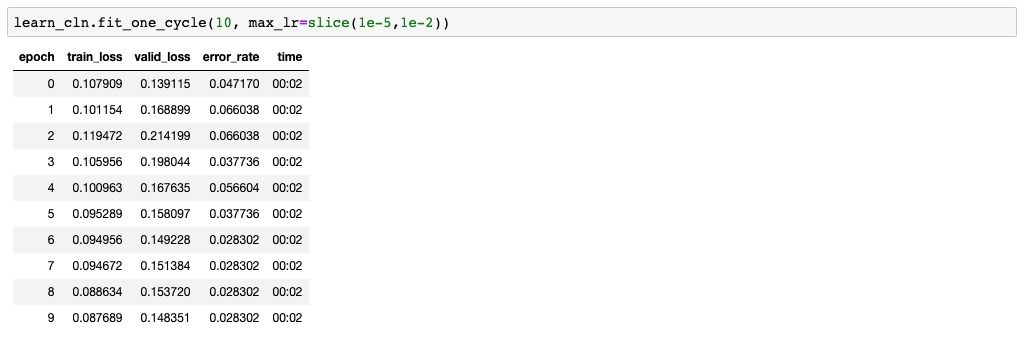
I’m following lesson 1 and working on the lesson-2 notebook. I successfully trained a model on my own image dataset and everything seems to be working fine. After loading a cleaned dataset from a csv
I also tried removeing the learn rate limits without any change. If necessary, I can post my file / folder structure. I am running the notebook on AWS via SSH. Is anybody able to help me with this? Thanks a lot in advance!
Thanks a lot @bwarner! That makes sense! However, I’m not quite sure what we would achieve with that. I understand that this is used to clean out incorrect images and then saves that resulting list in a csv file. However, wouldn’t it be good to see how the “cleaned” dataset performs in comparison to the original dataset?
I tried removing .split_none() and now I get the error message
Exception: Your data isn’t split, if you don’t want a validation set, please use split_none.
Which also makes sense. I dug a bit in the docs and found the parameter valid_pct. Trying to create a databunch with
the validation set is used to choose between models (for instance, does a random forest or a neural net work better for your problem? do you want a random forest with 40 trees or 50 trees?)
the test set tells you how you’ve done. If you’ve tried out a lot of different models, you may get one that does well on your validation set just by chance, and having a test set helps make sure that is not the case.
The documentation you linked to is for ImageDataBunch while you are using the datablock api. So you will want to use one of these methods.
@bwarner Thanks a lot for your detailed response again!
I knew about the necessity of train and validation set, but I’ll make sure to read through the article. I thought passing valid_pct=0.2 to ImageList.from_csv() would split the dataset into 80% train set and 20% validation set. The hint that I’m actually dealing with a datablock and not ImageDataBunch solved the issue