In the 10_nlp notebook I run into an error when predicting on the language model which has been fit_one_cycle for 1 epoch:
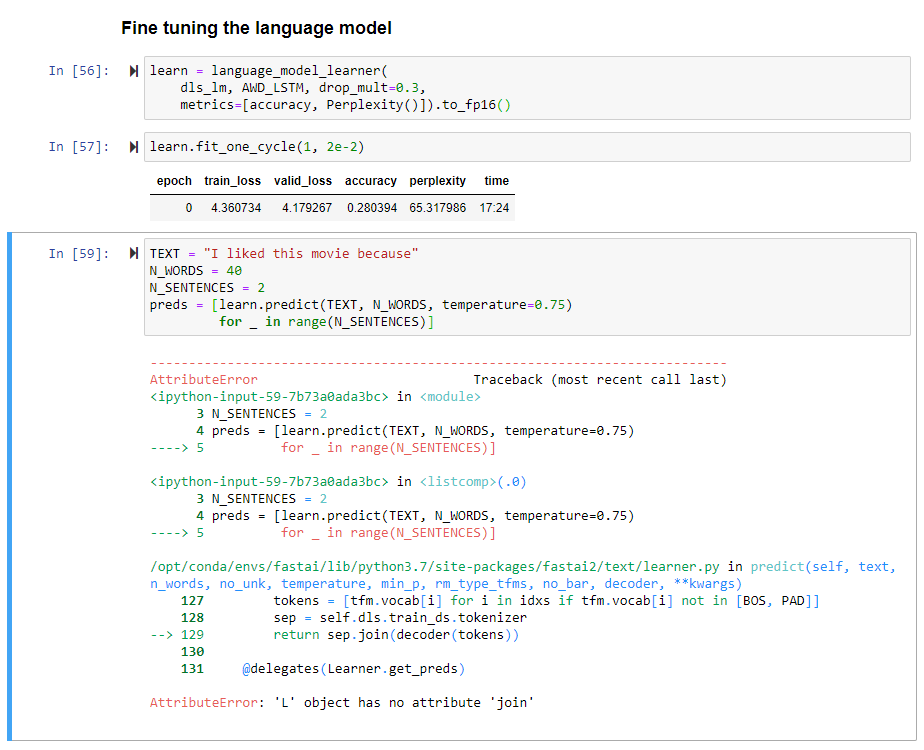
(Compared to the original notebook I moved the prediction cell up to save some time, but that shouldn’t have an effect.)
When checking the type of learn.dls.train_ds.tokenizer it is a L consisting of a fastai2.text.core.SpacyTokenizer and fastai2.text.core.Tokenizer, so in fact does not support .join
Any ideas where this might be going wrong?
EDIT:
I checked the source code and it seems the source has changed to:
sep = self.dls.train_ds.tokenizer[-1].sep
return sep.join(decoder(tokens))
where self.dls.train_ds.tokenizer[-1].sep indeed gives a string.
I am working on Paperspace, any idea why this change hasn’t been propagated there?