I am following the exact code given in the course-v3 notebook lesson3-planet.
%reload_ext autoreload
%autoreload 2
%matplotlib inline
import fastai
from fastai.vision import *
The Verison of FastAI libarary I am using is 1.0.38
fastai.__version__
'1.0.38'
path = Path("/home/anukoolpurohit/Documents/AnukoolPurohit/Datasets/Planet")
df = pd.read_csv(path/'train_v2.csv')
df.head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
|
image_name |
tags |
| 0 |
train_0 |
haze primary |
| 1 |
train_1 |
agriculture clear primary water |
| 2 |
train_2 |
clear primary |
| 3 |
train_3 |
clear primary |
| 4 |
train_4 |
agriculture clear habitation primary road |
tfms = get_transforms(flip_vert=True, max_lighting=0.1, max_zoom=1.05, max_warp=0.)
np.random.seed(42)
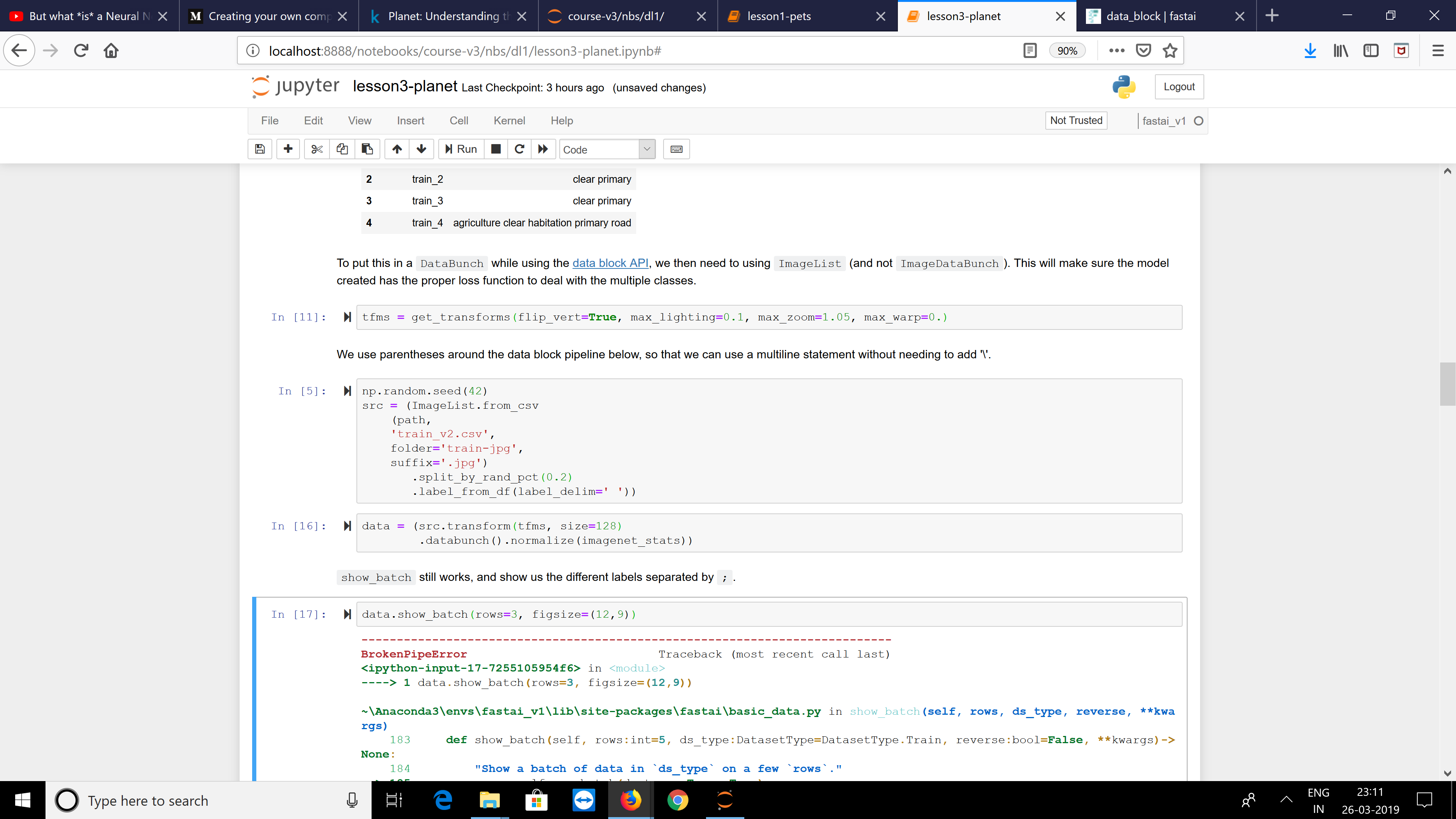
When I use the code provided in the notebook to generate an ImageItemList. I get the folowing Error:
Your validation data contains a label that isn’t present in the training set, please fix your data.
src = (ImageItemList.from_csv(path, 'train_v2.csv', folder='train-jpg', suffix='.jpg')
.random_split_by_pct(0.2)
.label_from_df(label_delim=' '))
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
~/anaconda3/envs/Torch10cuda/lib/python3.7/site-packages/fastai/data_block.py in process_one(self, item)
277 def process_one(self,item):
--> 278 try: return self.c2i[item] if item is not None else None
279 except:
KeyError: 'artisinal_mine clear primary selective_logging'
During handling of the above exception, another exception occurred:
Exception Traceback (most recent call last)
<ipython-input-145-4105ecc93aff> in <module>
1 src = (ImageItemList.from_csv(path, 'train_v2.csv', folder='train-jpg', suffix='.jpg')
2 .random_split_by_pct(0.2)
----> 3 .label_from_df(label_delim=' '))
~/anaconda3/envs/Torch10cuda/lib/python3.7/site-packages/fastai/data_block.py in _inner(*args, **kwargs)
391 self.valid = fv(*args, **kwargs)
392 self.__class__ = LabelLists
--> 393 self.process()
394 return self
395 return _inner
~/anaconda3/envs/Torch10cuda/lib/python3.7/site-packages/fastai/data_block.py in process(self)
438 "Process the inner datasets."
439 xp,yp = self.get_processors()
--> 440 for i,ds in enumerate(self.lists): ds.process(xp, yp, filter_missing_y=i==0)
441 return self
442
~/anaconda3/envs/Torch10cuda/lib/python3.7/site-packages/fastai/data_block.py in process(self, xp, yp, filter_missing_y)
563 def process(self, xp=None, yp=None, filter_missing_y:bool=False):
564 "Launch the processing on `self.x` and `self.y` with `xp` and `yp`."
--> 565 self.y.process(yp)
566 if filter_missing_y and (getattr(self.x, 'filter_missing_y', None)):
567 filt = array([o is None for o in self.y])
~/anaconda3/envs/Torch10cuda/lib/python3.7/site-packages/fastai/data_block.py in process(self, processor)
66 if processor is not None: self.processor = processor
67 self.processor = listify(self.processor)
---> 68 for p in self.processor: p.process(self)
69 return self
70
~/anaconda3/envs/Torch10cuda/lib/python3.7/site-packages/fastai/data_block.py in process(self, ds)
284 ds.classes = self.classes
285 ds.c2i = self.c2i
--> 286 super().process(ds)
287
288 def __getstate__(self): return {'classes':self.classes}
~/anaconda3/envs/Torch10cuda/lib/python3.7/site-packages/fastai/data_block.py in process(self, ds)
36 def __init__(self, ds:Collection=None): self.ref_ds = ds
37 def process_one(self, item:Any): return item
---> 38 def process(self, ds:Collection): ds.items = array([self.process_one(item) for item in ds.items])
39
40 class ItemList():
~/anaconda3/envs/Torch10cuda/lib/python3.7/site-packages/fastai/data_block.py in <listcomp>(.0)
36 def __init__(self, ds:Collection=None): self.ref_ds = ds
37 def process_one(self, item:Any): return item
---> 38 def process(self, ds:Collection): ds.items = array([self.process_one(item) for item in ds.items])
39
40 class ItemList():
~/anaconda3/envs/Torch10cuda/lib/python3.7/site-packages/fastai/data_block.py in process_one(self, item)
278 try: return self.c2i[item] if item is not None else None
279 except:
--> 280 raise Exception("Your validation data contains a label that isn't present in the training set, please fix your data.")
281
282 def process(self, ds):
Exception: Your validation data contains a label that isn't present in the training set, please fix your data.
So I wrote a function which will also randomly spilt the file into a validation and training set using the same logic as mentioned in the fastai source code. And then simply get the labels from the dataframe. I find that not only both validation and training set have same categories.
src1 = (ImageItemList.from_csv(path, 'train_v2.csv', folder='train-jpg', suffix='.jpg'))
def valid_gen(Images, valid_pct:float=0.2):
rand_indx = np.random.permutation(range_of(Images))
cut = int(valid_pct * len(Images))
df = Images.xtra
valid_indx = rand_indx[:cut]
train_indx = rand_indx[cut:]
valid_labels_set = set()
train_labels_set = set()
labels = [0]*len(rand_indx)
for idx in train_indx:
labels[idx] = df['tags'].iloc[idx].split(' ')
[train_labels_set.add(tag) for tag in df['tags'].iloc[idx].split(' ')]
for idx in valid_indx:
labels[idx] = df['tags'].iloc[idx].split(' ')
[valid_labels_set.add(tag) for tag in df['tags'].iloc[idx].split(' ')]
valid_labels = [labels[i] for i in valid_indx]
train_labels = [labels[i] for i in train_indx]
# Checking if the categories are the same in both sets
print(train_labels_set == valid_labels_set)
tup_labels = (train_labels, valid_labels)
tup_indexs = (train_indx, valid_indx)
return tup_labels, tup_indexs
labels, indx = valid_gen(src1)
True
But also that the labels get accepted by the funciton labels_from_lists
src2 = src1.split_by_idxs(indx[0],indx[1]).label_from_lists(train_labels=labels[0], valid_labels=labels[1])
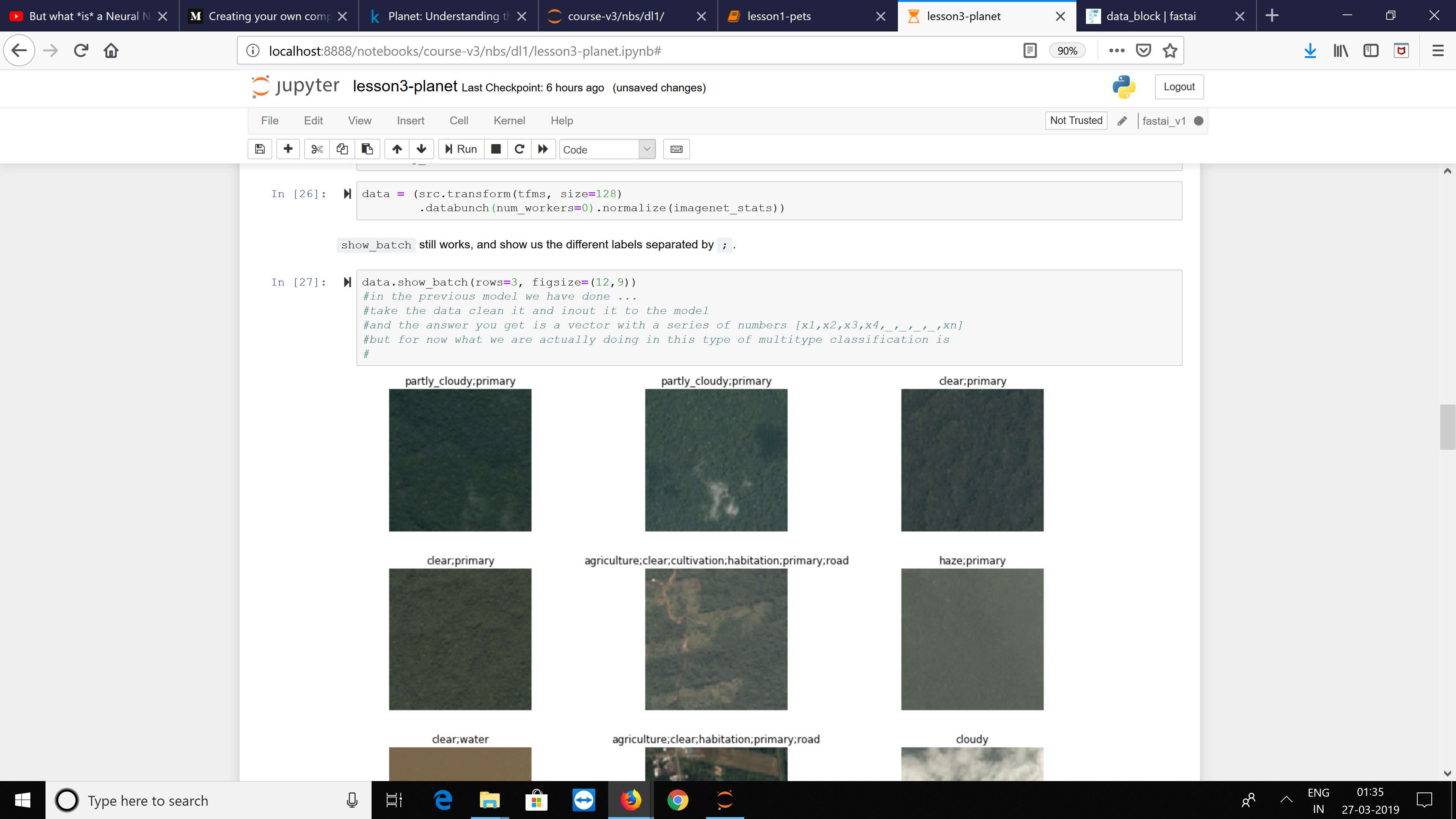
data = (src2.transform(tfms, size=128,)
.databunch().normalize(imagenet_stats))
data.show_batch(rows=3, figsize=(12,9))
![png]()
The Model seesms to be working with the data now.
arch = models.resnet50
acc_02 = partial(accuracy_thresh, thresh=0.2)
fscore = partial(fbeta, thresh=0.2)
learn = create_cnn(data, arch, metrics=[acc_02, fscore])
learn.lr_find()
LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.
learn.recorder.plot()
![png]()
lr = 0.01
learn.fit_one_cycle(5, slice(lr))
Total time: 04:33
| epoch |
train_loss |
valid_loss |
accuracy_thresh |
fbeta |
| 1 |
0.125079 |
0.108500 |
0.943233 |
0.902233 |
| 2 |
0.111805 |
0.096825 |
0.947876 |
0.911082 |
| 3 |
0.100525 |
0.093286 |
0.954634 |
0.917938 |
| 4 |
0.094361 |
0.088019 |
0.957156 |
0.923029 |
| 5 |
0.093210 |
0.085858 |
0.956000 |
0.925485 |
Why am I getting the error in when I use label_from_df? Is there is something wrong with my code? or Version? Or the function has been changed in some way?