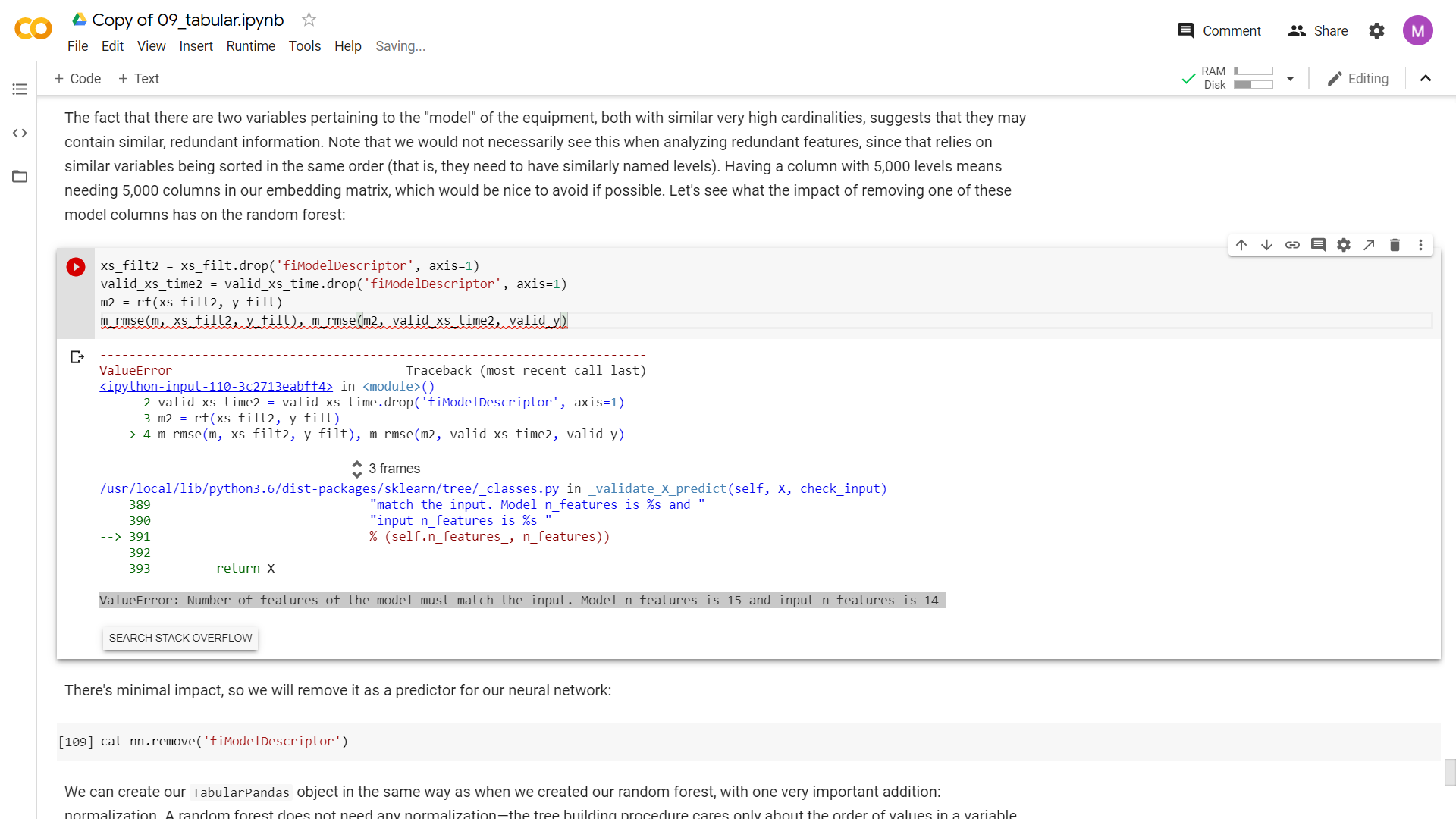
I run all codes of the chapters in collab,
In lesson 7, chapter 9 notebook has just one error.
I searched in stack overflow to fix it, but I couldn’t fix it
and I rerun all code, but there is the same error
Did anyone see this error in this chapter?
xs_filt2 = xs_filt.drop('fiModelDescriptor', axis=1)
valid_xs_time2 = valid_xs_time.drop('fiModelDescriptor', axis=1)
m2 = rf(xs_filt2, y_filt)
m_rmse(m, xs_filt2, y_filt), m_rmse(m2, valid_xs_time2, valid_y)
Returns
ValueError Traceback (most recent call last)
<ipython-input-110-3c2713eabff4> in <module>()
2 valid_xs_time2 = valid_xs_time.drop('fiModelDescriptor', axis=1)
3 m2 = rf(xs_filt2, y_filt)
----> 4 m_rmse(m, xs_filt2, y_filt), m_rmse(m2, valid_xs_time2, valid_y)
-----------------------------------------------------------------------------------------------
/usr/local/lib/python3.6/dist-packages/sklearn/tree/_classes.py in _validate_X_predict(self, X, check_input)
389 "match the input. Model n_features is %s and "
390 "input n_features is %s "
--> 391 % (self.n_features_, n_features))
392
393 return X
ValueError: Number of features of the model must match the input. Model n_features is 15 and input n_features is 14