I’ve been ensembling some fast.AI TabularModels for a while now, and have been doing so by taking the mean across models of the post-softmax probabilities. However, I’ve also heard of people taking the mean across models of the pre-softmax logits, and then performing the softmax on that.
Is one preferred to the other? Are their pro’s/con’s to each approach?
One issue I have found with doing the mean of the probabilities is that It is more difficult to calculate the loss of such an ensemble, since the CrossEntropy loss function my models use expects logits instead of probabilities. I suppose I could just use a loss function that is expecting the incoming predictions to be post-softmax, but it just feels odd to me to use a different loss function.
I personally haven’t tried the other, though it would be an interesting concept because it’s more “raw”. You’d have to watch out for the scale of the pre-softmax’d features and see if there is some potential model bias (more than what we could expect when everything is scaled the same)
You’d have to watch out for the scale of the pre-softmax’d features and see if there is some potential model bias (more than what we could expect when everything is scaled the same)
What do you mean by pre-softmax’d features? As in the inputs of the final nodes of the model or the input features to the first nodes in the model (like the actual features)? I’m normalizing the features so they should all have fairly similar scales.
But if you mean the inputs to the final nodes, yeah that’s an interesting point. If they have different scales it would essentially end up being more like a weighted average when you take the mean of the logits from each model, where it’s weighted more towards models that have larger logits scales. Is that what you’re saying?
FWIW, so far anecdotally they seem to produce fairly similar results (averaging by logits vs averaging by probabilities)
Updating here with my findings. This is pretty verbose, so TL;DR - I’m deciding to go with ensembling probabilities, but it may be worth running some tests on your own data sets and models, as my experiments were inconclusive but showed little difference between the two methods.
This paper on ensembling suggests that ensembling probabilities is experimentally slightly favorable. They provide the same intuition for this as you did @muellerzr, namely
It is more reasonable to average after the softmax transformation, as the scores might have
varying scales of magnitude across the base learners, as the score output from different network
might be in different magnitude.
Nice call!
I ran my own experiments to see the effects on model loss when ensembling probabilities vs. ensembling logits. I did the following on 4 different (albeit similar) tabular data sets that I use at work:
trained 100 models with a typical train-val-test split.
got the outputs (logits) for each of these 100 models.
converted these logits into probabilities (probs) using softmax.
created 10 ensembles each of varying sizes from these 100 prediction sets. So the first 10 ensembles have 1 model in them (not really an ensemble), the second 10 ensembles have 2 models in them, … the last 10 ensembles have 10 models in them.
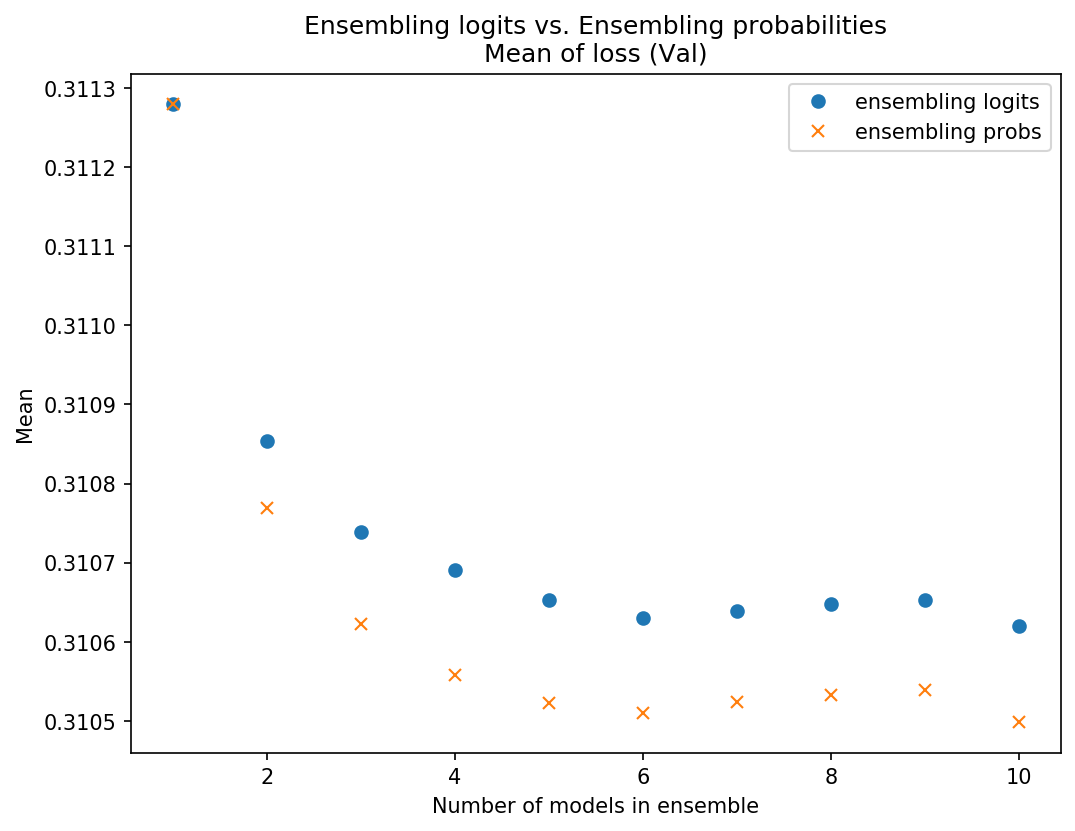
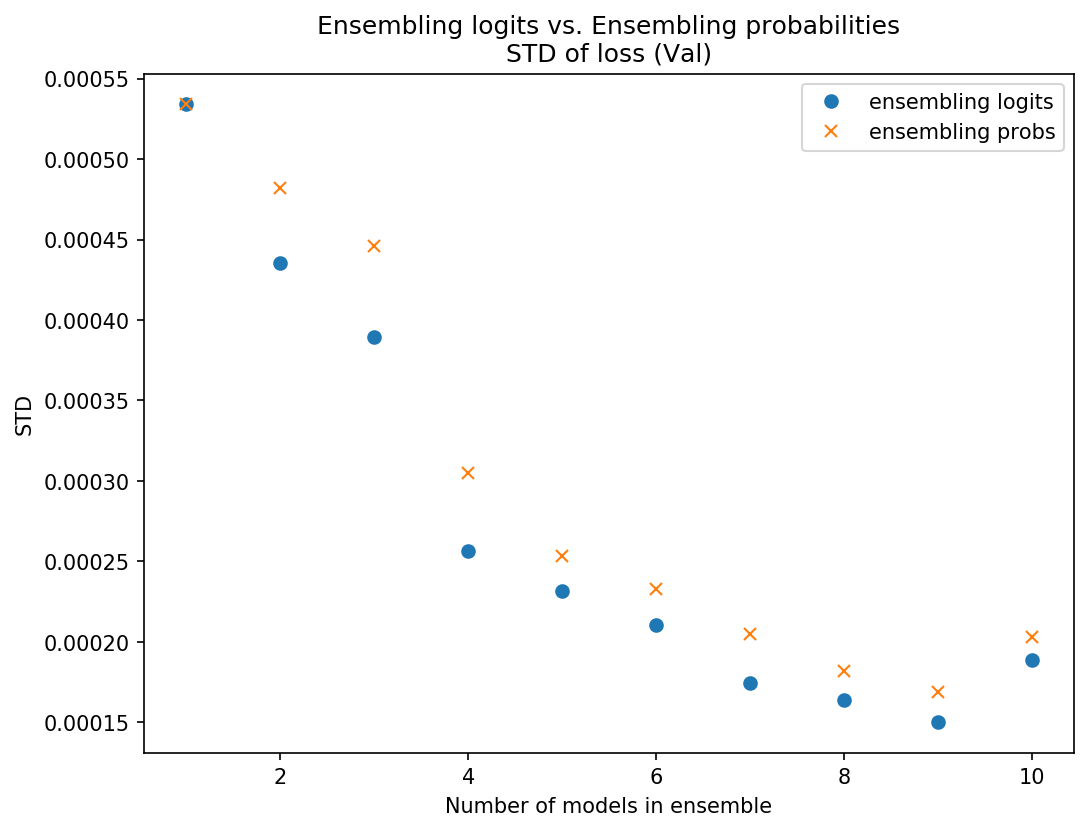
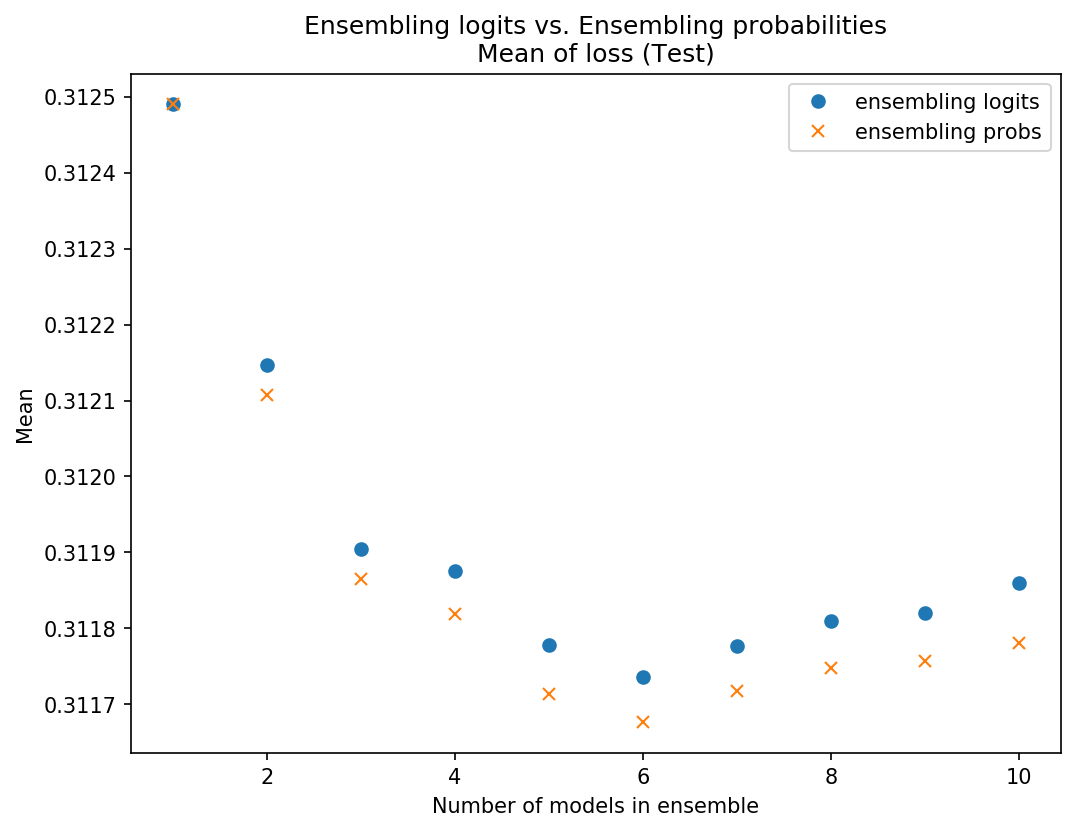
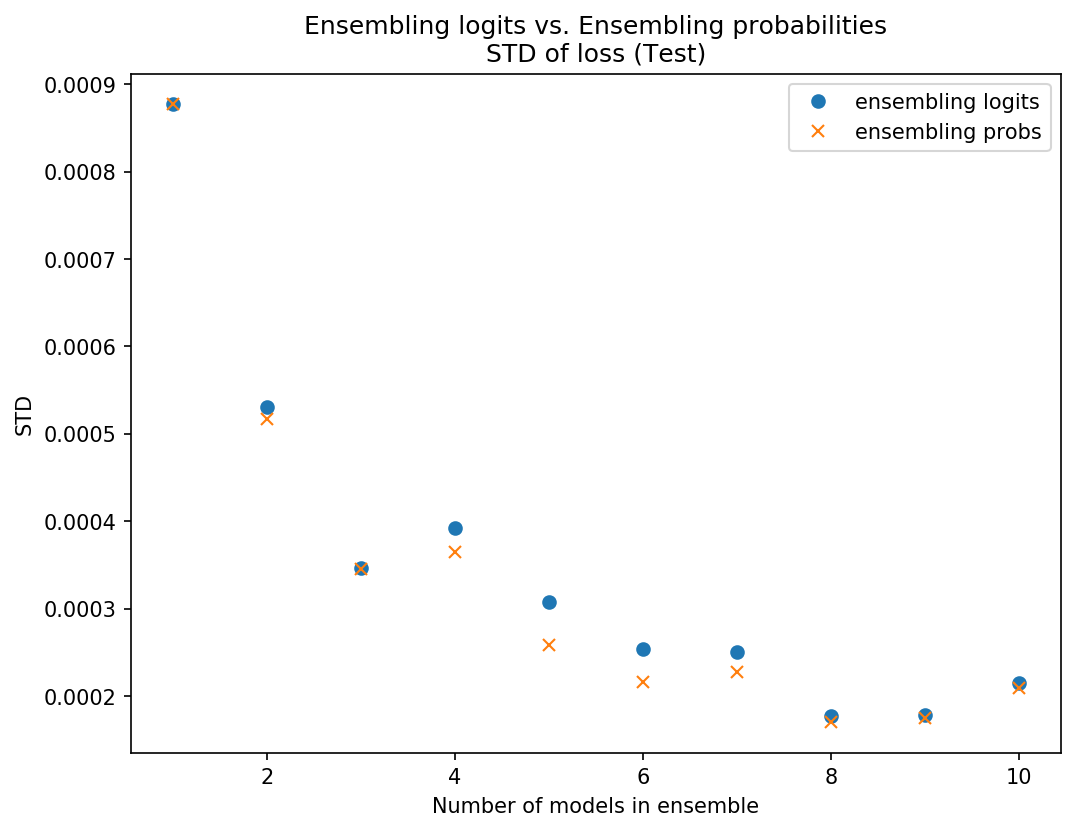
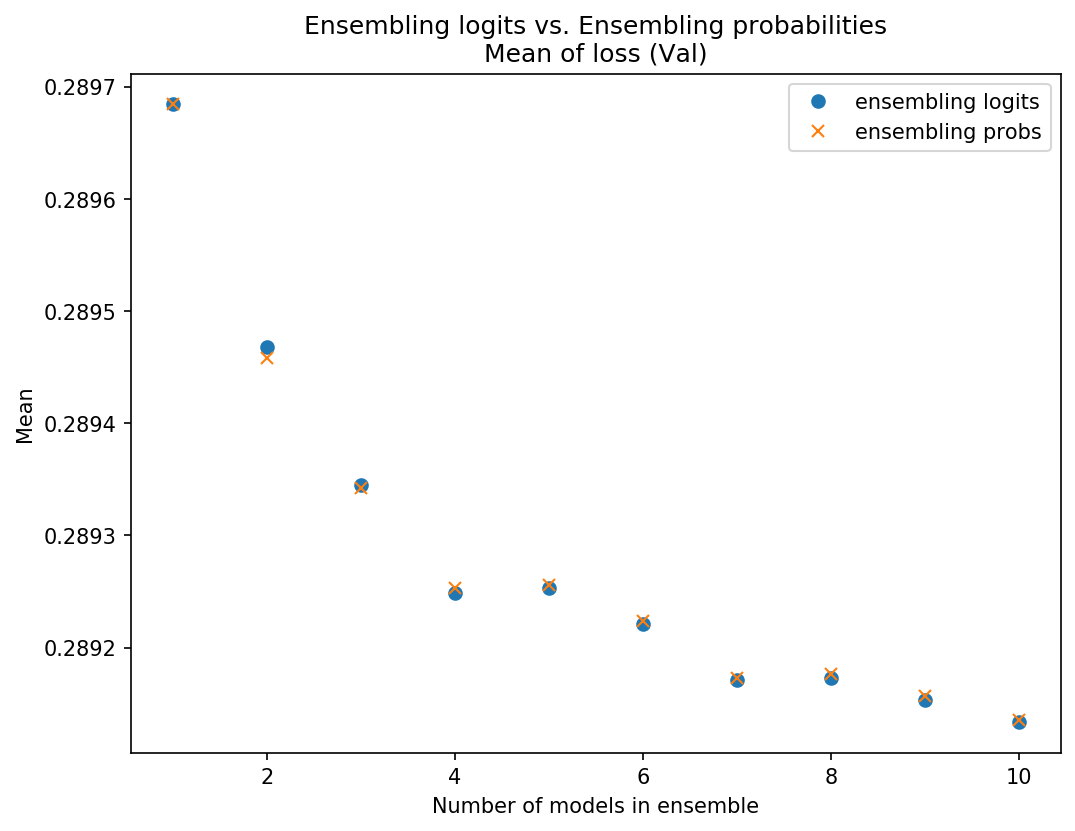
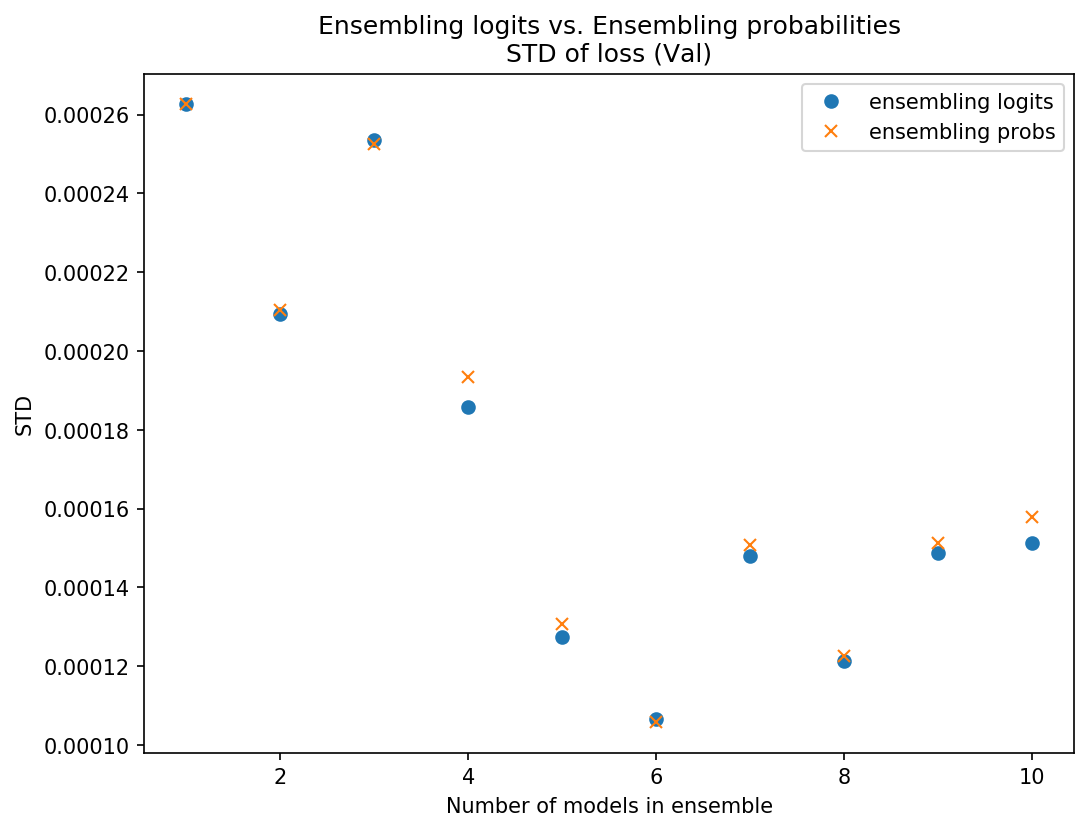
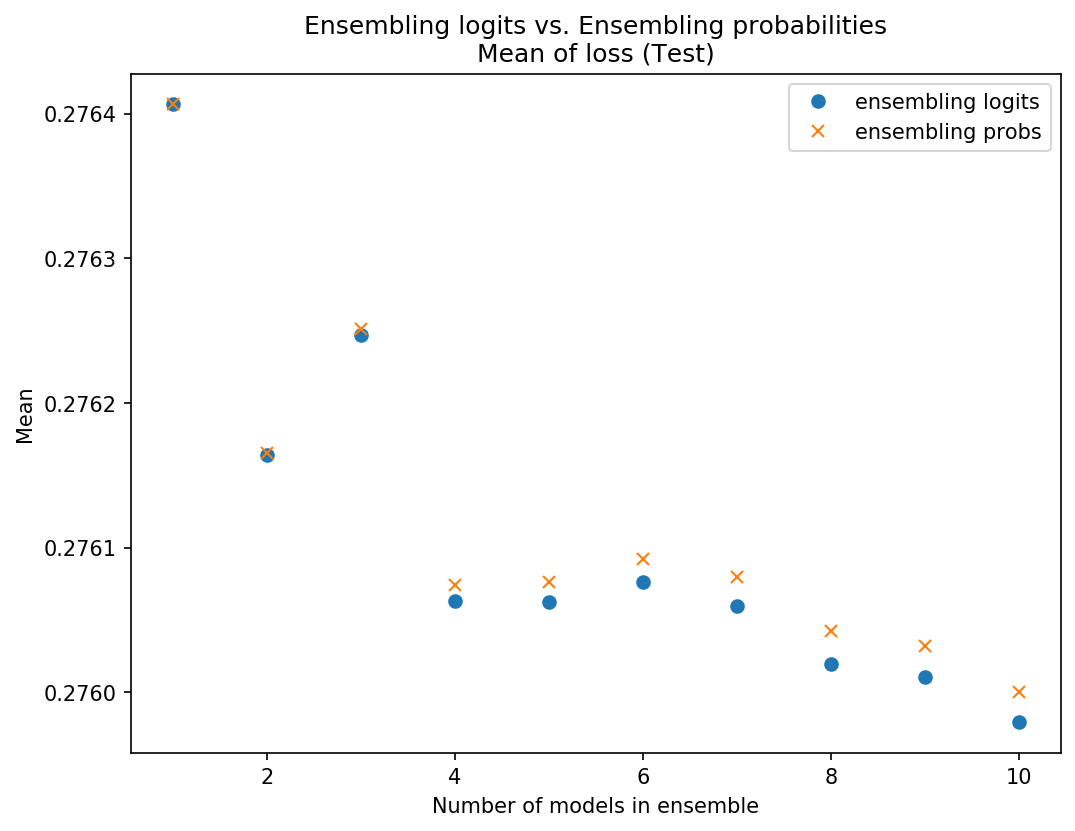
I got the ensemble predictions by averaging logits and compared the loss to ensembling predictions by averaging probs. I compared the mean and STD of the sets of 10 ensembles.
My results were fairly inconclusive - on some data sets averaging the probs was slightly better (slightly lower mean loss and/or STD), on some data sets averaging logits was slightly better, and sometimes it just varied. Below are some plots of some of these results so you can see what I mean:
Data set 1 - Using probs was better on test and on mean in val, logits better STD on val
I won’t post any more charts but I think you get the picture. They’re really pretty close, and neither was consistently better. Because of the theoretical/intuitive concern about scaling issues, I’m going with ensembling the probs since there may be less risk there.