After months of development and debugging, I finally successfully train a model from scratch and replicate the official results.
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
by Kevin Clark. Minh-Thang Luong. Quoc V. Le. Christopher D. Manning
![]() Code: electra_pytorch
Code: electra_pytorch
-
AFAIK, the closest reimplementation to the original one, taking care of many easily overlooked details (described below).
-
AFAIK, the only one successfully validate itself by replicating the results in the paper.
-
Comes with jupyter notebooks, which you can explore the code and inspect the processed data.
-
You don’t need to download and preprocess anything by yourself, all you need is running the training script.
Replicated Results
I pretrain ELECTRA-small from scratch and have successfully replicated the paper’s results on GLUE.
| Model | CoLA | SST | MRPC | STS | QQP | MNLI | QNLI | RTE | Avg. of Avg. |
|---|---|---|---|---|---|---|---|---|---|
| ELECTRA-Small-OWT | 56.8 | 88.3 | 87.4 | 86.8 | 88.3 | 78.9 | 87.9 | 68.5 | 80.36 |
| ELECTRA-Small-OWT (my) | 58.72 | 88.03 | 86.04 | 86.16 | 88.63 | 80.4 | 87.45 | 67.46 | 80.36 |
Table 1: Results on GLUE dev set. The official result comes from expected results. Scores are the average scores finetuned from the same checkpoint. (See this issue) My result comes from pretraining a model from scratch and thens taking average from 10 finetuning runs for each task. Both results are trained on OpenWebText corpus
| Model | CoLA | SST | MRPC | STS | QQP | MNLI | QNLI | RTE | Avg. |
|---|---|---|---|---|---|---|---|---|---|
| ELECTRA-Small++ | 55.6 | 91.1 | 84.9 | 84.6 | 88.0 | 81.6 | 88.3 | 6.36 | 79.7 |
| ELECTRA-Small++ (my) | 54.8 | 91.6 | 84.6 | 84.2 | 88.5 | 82 | 89 | 64.7 | 79.92 |
Table 2: Results on GLUE test set. My result finetunes the pretrained checkpoint loaded from huggingface.
| Official training loss curve | My training loss curve |
|---|---|
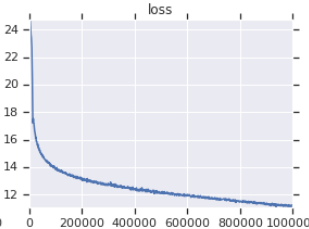 |
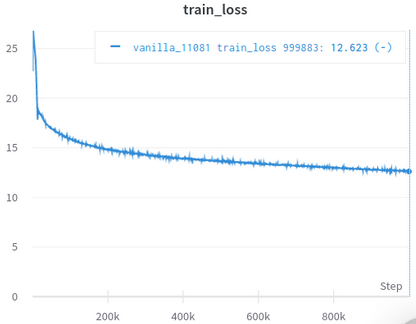 |
Table 3: Both are small models trained on OpenWebText. The official one is from here. You should take the value of training loss with a grain of salt since it doesn’t reflect the performance of downstream tasks.
More results
How stable is ELECTRA pretraining?
| Mean | Std | Max | Min | #models |
|---|---|---|---|---|
| 81.38 | 0.57 | 82.23 | 80.42 | 14 |
Tabel 4: Statistics of GLUE devset results for small models. Every model is pretrained from scratch with different seeds and finetuned for 10 random runs for each GLUE task. Score of a model is the average of the best of 10 for each task. (The process is as same as the one described in the paper) As we can see, although ELECTRA is mocking adeversarial training, it has a good training stability.
How stable is ELECTRA finetuing on GLUE ?
| Model | CoLA | SST | MRPC | STS | QQP | MNLI | QNLI | RTE |
|---|---|---|---|---|---|---|---|---|
| ELECTRA-Small-OWT (my) | 1.30 | 0.49 | 0.7 | 0.29 | 0.1 | 0.15 | 0.33 | 1.93 |
Table 5: Standard deviation for each task. This is the same model as Table 1, which finetunes 10 runs for each task.
Advanced details  (Skip it if you want)
(Skip it if you want)
elow lists the details of the original implementation/paper that are easy to be overlooked and I have taken care of. I found these details are indispensable to successfully replicate the results of the paper.
Optimization
- Using Adam optimizer without bias correction (bias correction is default for Adam optimizer in Pytorch and fastai)
- There is a bug of decaying learning rates through layers in the official implementation , so that when finetuing, lr decays more than the stated in the paper. See _get_layer_lrs. Also see this issue.
- Using clip gradient
- using 0 weight decay when finetuning on GLUE
- It didn’t do warmup and then do linear decay but do them together, which means the learning rate warmups and decays at the same time during the warming up phase. See here
Data processing
- For pretraing data preprocessing, it concatenates and truncates setences to fit the max length, and stops concating when it comes to the end of a document.
- For pretraing data preprocessing, it by chance splits the text into sentence A and sentence B, and also by chance changes the max length
- For finetuning data preprocessing, it follow BERT’s way to truncate the longest one of sentence A and B to fit the max length
Trick
- For MRPC and STS tasks, it augments training data by add the same training data but with swapped sentence A and B. This is called “double_unordered” in the official implementation.
- It didn’t mask sentence like BERT, within the mask probability (15% or other value) of tokens, a token has 85% chance to be replaced with [MASK] and 15% remains the same but no chance to be replaced with a random token.
Tying parameter
- Input and output word embeddings of generator, and input word embeddings of discriminator. The three are tied together.
- It tie not only word/pos/token type embeddings but also layer norm in the embedding layers of both generator and discriminator.
Other
- The output layer is initialized by Tensorflow v1’s default initialization (i.e. xavier uniform)
- Using gumbel softmax to sample generations from geneartor as input of discriminator
- It use a dropout and a linear layer in the output layer for GLUE finetuning, not what
ElectraClassificationHeaduses. - All public model of ELECTRA checkpoints are actually ++ model. See this issue
- It downscales generator by hidden_size, number of attention heads, and intermediate size, but not number of layers.
Need your help 
Please consider help us on the problems listed below, or tag someone else you think might help.
-
Haven’t success to replicate results of WNLI trick for ELECTRA-Large described in the paper.
-
When I finetune on GLUE (using
finetune.py), GPU-util is only about 30-40%. I suspect the reason to be small batch and model size (forward pass only takes 1ms) or slow cpu speed ?
About more
The updates of this reimplementation and other tools I created will be tweeted on my Twitter Richard Wang.
Also my personal research based on ELECTRA is underway, hope I can share some good results on Twitter then.