It was very discouraging for me as well to ‘delete’ samples without knowing the category. As I found later, downloading images from google/baidu/etc will provide you with a big amount of garbage, and that has to be cleaned up manually.
I went away looking for other deduplicators but eventually came back in an attempt to stick to the tools provided by the course.
I found something interesting. It is not the intended use, but in my opinion it works much better.
If you do:
ds, idxs = DatasetFormatter().from_similars(learn_cln)
ImageCleaner(ds, idxs, path, duplicates=True)
Then you get something like
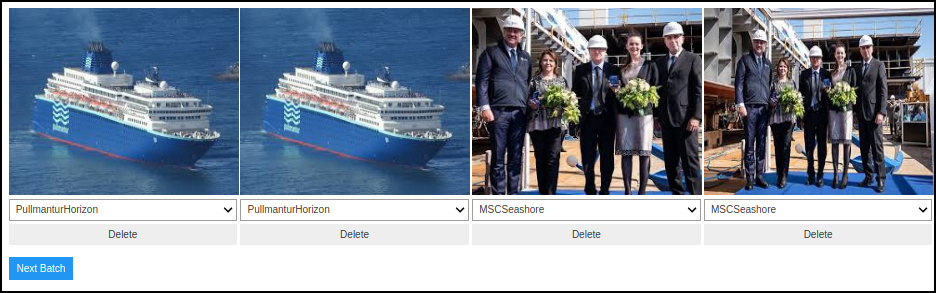
But!! If you do:
ds, idxs = DatasetFormatter().from_similars(learn_cln)
ImageCleaner(ds, idxs, path, duplicates=False)
Then you get
This allows to SEE the categories and perform a faster cleaning of the dataset.
Because… rather than
- Do top_losses
- re-categorize N out of M clones (multiple times)
- Reload the csv
- Then do from_similars
- delete N out of M clones (multiple times)
I do:
- Do from_similars
- delete N out of M clones and re-categorize the image left (multiple times)
Then you can focus on top_losses knowing that all the duplicates are out of the game.
================
This has nothing to do with the tool but is a VERY NICE trick.
If you get an image that you are unsure of (you simply don’t know the category it belongs to).
Then right click on it (only on Chrome, sorry) and click on “Search google for image”.
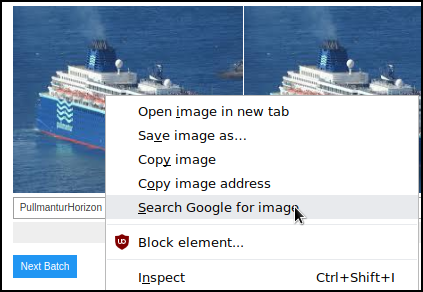
On the heading you may find your answer
If not, find a large picture on the results to open, or look at the titles of webpages containing the photo.
In other words, use Google’s power to find out the answer.