I have included in the ImageCleaner widget a duplicate finding functionality. Basically users can scan the most similar pairs of images in their dataset and chose to delete them if necessary. The only differences in usage are calling from_similars() method in DatasetFormatter and specifying duplicates=True when calling ImageCleaner.
6 Likes
@lesscomfortable I’m trying to use the .from_similars and I’m running into a weird problem:
I build the databunch strictly adhering to the docs:
db =(ImageItemList.from_folder(PATH)
.no_split()
.label_from_folder()
.transform(no_tfms, size = 122)
.databunch(bs = 16))
The databunch has the correct number of images:
db.train_ds.x
-> ImageItemList (273 items)
But when I use DatasetFormatter().from_similars(learn), I end up with a list of id’s thats twice as long as the dataset and just matching each image with itself:
ds, idxs = DatasetFormatter().from_similars(learn)
len(idxs)
-> 546
idxs[:8]
-> [223, 223, 133, 133, 79, 79, 191, 191]
Am I implementing this incorrectly or misunderstanding how it’s supposed to be used?
Thanks for the help.
Hey! This is not expected, I’m going to check it myself in a few minutes. It seems it is comaparing images with themselves (not the correct behavior). Are you using the last version of the library?
Yes, I upgraded yesterday morning so I’m on the latest version.
1 Like
I found the bug. Will submit a PR now, please replace the last line in comb_similarity by these two:
t = torch.mm(t1, t2.t()) / (w1 * w2.t()).clamp(min=1e-8)
return torch.tril(t, diagonal=-1)
2 Likes
Works great, thanks!
1 Like
Hello @lesscomfortable. I just tested your ImageCleaner widget (I used ImageDataBunch.from_folder() to create my batches). Great widget!
My questions:
1) How to get validation images in the widget?
I started with DatasetFormatter().from_toplosses(learn) (code below). It created the file cleaned.csv with the list of my training images.
ds, idxs = DatasetFormatter().from_toplosses(learn)
ImageCleaner(ds, idxs, path)
Then, I added the argument ds_type=DatasetType.Valid as coded below, but it gave me again images from my training dataset.
ds, idxs = DatasetFormatter().from_toplosses(learn, ds_type=DatasetType.Valid)
ImageCleaner(ds, idxs, path)
2) How to end?
It looks like the ImageCleaner widget never ends. It displays again and again the same images. How to deal with that ?
3) Call from_similars() delete cleaned.csv and create a new one (gloups  )
)
After, I ran the following code that replaced my cleaned.csv. How to avoid that?
ds, idxs = DatasetFormatter().from_similars(learn)
ImageCleaner(ds, idxs, path, duplicates=True)
4) How to display the labels?
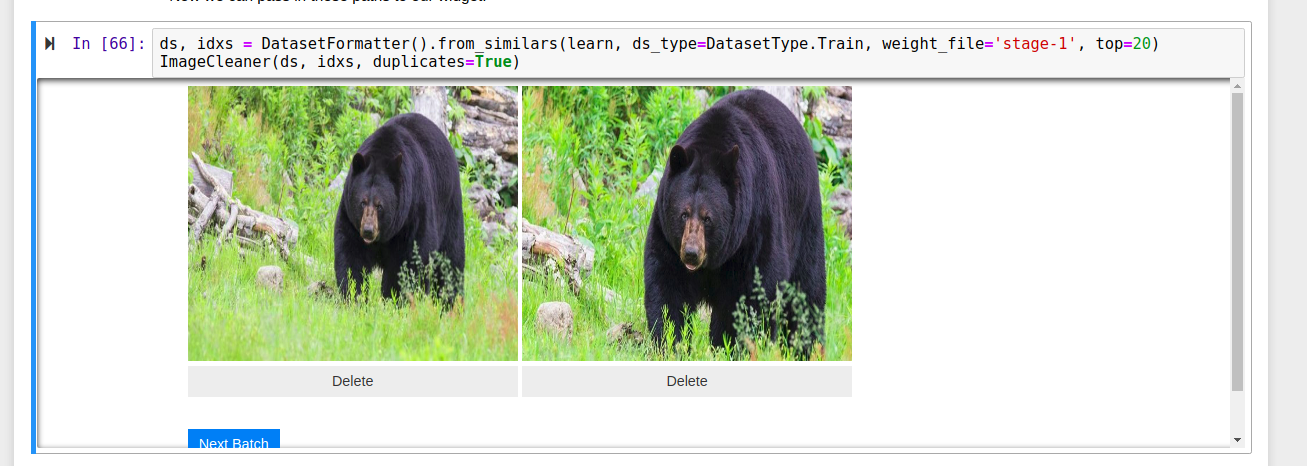
It would be great to see the labels in order to decide which image to delete (screenshot below).

3 Likes
Pierre, thanks for the feedback! Let me answer your questions one by one:
-
You need to create your databunch using
no_split()like this:db = (ImageItemList.from_folder(path)
.no_split()
.label_from_folder()
.databunch())
If you do it like this, all your dataset will be considered when running the widget.
-
You don’t need to end it. It recreates the csv every time you click on
next batch. Just stop when you are done. -
That’s fine, but you should run from_similars loading from the previous csv. This way the csv created when running
from_similarswill include the changes made using the first widget and the second widget. -
There is no way yet to display the labels (I didn’t think it was useful since you have from_toplosses to change labels). However now that you mention it, I understand that it might be useful. I am a bit tight on time but if I find some time I’ll include it. You are welcome to submit a PR if you want to do it yourself too.
5 Likes
Great. The idea is indeed to have all data in training. Thanks.
But I want to end it ![]() Once I made a choice for an image, I do not want to see it again.
Once I made a choice for an image, I do not want to see it again.
That’s what I want but it is not working like that. When I run from_similars, it creates a new cleaned.csv (ie, it destroys the existing one).
Yes, it is definitively important as I can not make any decision without knowing the label of the image (for example, how to choose the one to delete when there are 2 identical images?).
Great if you can solve these 3 points (when you have time and if you agree on them of course):
- do not show 2 times the same image
- do not delete cleaned.csv when it exists
- display labels
I also wanted to clean the (training + validation) datasets.
By following @lesscomfortable’s recommendation, what i did is:
db = (ImageItemList.from_folder(path)
.no_split()
.label_from_folder()
.databunch())
learn = create_cnn(db, models.resnet34, metrics=error_rate)
learn.load('stage-2')
ds, idxs = DatasetFormatter().from_toplosses(learn)
But it ended up with error as below:
RuntimeError Traceback (most recent call last)
<ipython-input-20-59787071ac27> in <module>
6 learn = create_cnn(db, models.resnet34, metrics=error_rate)
7 learn.load('stage-2')
----> 8 ds, idxs = DatasetFormatter().from_toplosses(learn)
/opt/anaconda3/lib/python3.7/site-packages/fastai/widgets/image_cleaner.py in from_toplosses(cls, learn, n_imgs, **kwargs)
17 def from_toplosses(cls, learn, n_imgs=None, **kwargs):
18 "Gets indices with top losses."
---> 19 train_ds, train_idxs = cls.get_toplosses_idxs(learn, n_imgs, **kwargs)
20 return train_ds, train_idxs
21
/opt/anaconda3/lib/python3.7/site-packages/fastai/widgets/image_cleaner.py in get_toplosses_idxs(cls, learn, n_imgs, **kwargs)
25 dl = learn.data.fix_dl
26 if not n_imgs: n_imgs = len(dl.dataset)
---> 27 _,_,top_losses = learn.get_preds(ds_type=DatasetType.Fix, with_loss=True)
28 idxs = torch.topk(top_losses, n_imgs)[1]
29 return cls.padded_ds(dl.dataset, **kwargs), idxs
/opt/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in get_preds(self, ds_type, with_loss, n_batch, pbar)
253 lf = self.loss_func if with_loss else None
254 return get_preds(self.model, self.dl(ds_type), cb_handler=CallbackHandler(self.callbacks),
--> 255 activ=_loss_func2activ(self.loss_func), loss_func=lf, n_batch=n_batch, pbar=pbar)
256
257 def pred_batch(self, ds_type:DatasetType=DatasetType.Valid, batch:Tuple=None, reconstruct:bool=False) -> List[Tensor]:
/opt/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in get_preds(model, dl, pbar, cb_handler, activ, loss_func, n_batch)
38 "Tuple of predictions and targets, and optional losses (if `loss_func`) using `dl`, max batches `n_batch`."
39 res = [torch.cat(o).cpu() for o in
---> 40 zip(*validate(model, dl, cb_handler=cb_handler, pbar=pbar, average=False, n_batch=n_batch))]
41 if loss_func is not None: res.append(calc_loss(res[0], res[1], loss_func))
42 if activ is not None: res[0] = activ(res[0])
/opt/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in validate(model, dl, loss_func, cb_handler, pbar, average, n_batch)
50 val_losses,nums = [],[]
51 if cb_handler: cb_handler.set_dl(dl)
---> 52 for xb,yb in progress_bar(dl, parent=pbar, leave=(pbar is not None)):
53 if cb_handler: xb, yb = cb_handler.on_batch_begin(xb, yb, train=False)
54 val_losses.append(loss_batch(model, xb, yb, loss_func, cb_handler=cb_handler))
/opt/anaconda3/lib/python3.7/site-packages/fastprogress/fastprogress.py in __iter__(self)
63 self.update(0)
64 try:
---> 65 for i,o in enumerate(self._gen):
66 yield o
67 if self.auto_update: self.update(i+1)
/opt/anaconda3/lib/python3.7/site-packages/fastai/basic_data.py in __iter__(self)
69 def __iter__(self):
70 "Process and returns items from `DataLoader`."
---> 71 for b in self.dl: yield self.proc_batch(b)
72
73 @classmethod
/opt/anaconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py in __next__(self)
635 self.reorder_dict[idx] = batch
636 continue
--> 637 return self._process_next_batch(batch)
638
639 next = __next__ # Python 2 compatibility
/opt/anaconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py in _process_next_batch(self, batch)
656 self._put_indices()
657 if isinstance(batch, ExceptionWrapper):
--> 658 raise batch.exc_type(batch.exc_msg)
659 return batch
660
RuntimeError: Traceback (most recent call last):
File "/opt/anaconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 138, in _worker_loop
samples = collate_fn([dataset[i] for i in batch_indices])
File "/opt/anaconda3/lib/python3.7/site-packages/fastai/torch_core.py", line 110, in data_collate
return torch.utils.data.dataloader.default_collate(to_data(batch))
File "/opt/anaconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 232, in default_collate
return [default_collate(samples) for samples in transposed]
File "/opt/anaconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 232, in <listcomp>
return [default_collate(samples) for samples in transposed]
File "/opt/anaconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 209, in default_collate
return torch.stack(batch, 0, out=out)
RuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 0. Got 333 and 282 in dimension 2 at /opt/conda/conda-bld/pytorch_1544202130060/work/aten/src/TH/generic/THTensorMoreMath.cpp:1333
look like it is looking for the losses when calling DatasetFormatter().from_toplosses(learn), but actually I don’t have it because I only load the model’s weights, i didn’t run fit_one_cycle().
Can you please help here.
You won’t! The widget does not show deleted images.
Yes, this is expected. It includes both the old changes and the new changes in a brand new csv. Is this ok for you?
My assumption was that once you run the relabeler widget, it doesn’t make a difference which to delete because they should be well labeled. However, if you run the duplicate detector without running the relabeler first, what you say makes sense.
I think this has to do with the images being of different dimensions. Try transforming them to have the same dimensions before loading them into the model. See here for help on how to do this.
As .no_split() will create an DataBunch with no validation set, then there won’t be any valid_loss or error_rate shown if we fit on that data (as expected). So how do we add the validation set back in?
Thanks.
@lesscomfortable is there any way that DatasetFormatter.from_top_losses could honor the dataset type like it used to? It seems like ds_type was hardcoded to be Test at some point before being changed to Fix. This was a huge source of confusion for me while running through lesson 2. Ideally I would think that from_top_losses should look at the entire dataset(not just Test/Validation) separately.
It seems kind of hacky to require users to create a new databunch without a validation set in order to be able to achieve the standard use-case functionality. I’d be happy to work on a PR for this if you think it would be helpful.
Incidentally, what is the Fix DatasetType?
1 Like
I am having exactly the same problem. I upgraded to latest version.
The Fix DatasetType is the train dataset without shuffling. Since we built the databunch using no_split, the train dataset contains all the images in the dataset. By specifying .Fix we get the whole dataset without shuffling, which is what we want.
If you can write a PR that removes the need to create a new databunch for the widget, that would be great!
1 Like
This bug is solved, are you sure you are using the last version?
I upgraded yes but still the same problem. I am working in a Kaggle Kernel so maybe I cannot upgrade the fastai package myself within my kernel.
Yeah, it would be worth to try in a Jupyter Notebook running locally or in a server so you can understand where the problem is coming from.