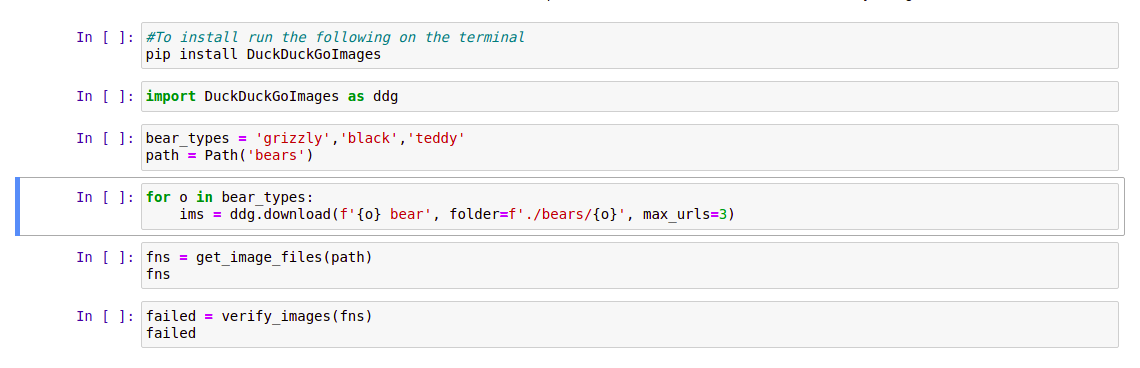
Sorry to ask such a banal question, but I cannot get the Duck Duck Go code to work in Colab. Per this page, the following code should work on Colab:
!pip install -Uqq fastbook
import fastbook
fastbook.setup_book()
from fastbook import *
urls = search_images_ddg('grizzly bear', max_images=100)
This throws the following error
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-2-1f02cd6eb038> in <module>()
4 from fastbook import *
5
----> 6 urls = search_images_ddg('grizzly bear', max_images=100)
7 len(urls),urls[0]
/usr/local/lib/python3.6/dist-packages/fastbook/__init__.py in search_images_ddg(term, max_images)
55 assert max_images<1000
56 url = 'https://duckduckgo.com/'
---> 57 res = urlread(url,data={'q':term}).decode()
58 searchObj = re.search(r'vqd=([\d-]+)\&', res)
59 assert searchObj
AttributeError: 'str' object has no attribute 'decode'
I see in the fastai docs that
they do not have an official API, so the function we’ll show here relies on the particular structure of their web interface, which may change.
Perhaps the API changed. Can anyone get this to work?


{kind=link}