Really interesting idea. I’m going to try this out on my own model. It’s using structured data and only 2 fully connected layers. I’ll report back results when i get it working.
Thanks for the interest. Let me know if you get any results or insights.
I’ve also experimented with changing ps in the midst of training, but didn’t get any positive results.
For the dog breeds with resnext101_64, picking the right dropout rate, rather than just 0.5, seemed to make a significant difference in the final result.
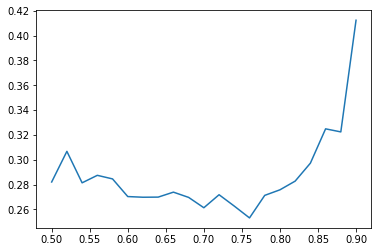
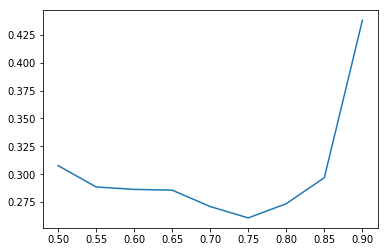
Has anyone tried using a dynamic dropout rate? I’m thinking of a system similar to the learning rate finder. You would start with a dropout-keep of 1 (i.e. no dropout) and gradually go to 0. The loss vs dropout plot should also have a U shape. It could potentially help find the best dropout.
Hey that’s a good idea. Might also want to try going the other way (high drop out to no drop out) and see what works best. There is a risk of initially overfitting if you start with no drop out.
Nice work here! Just to make sure I understand – will the precomputed activations work for any trained model weights? In my limited usage, I’ve found increasing dropout to be helpful only after I’ve started overfitting.
Over-fitting should not be an issue if you keep the number of training steps low. With learning rate finder I increase the learning rate after each gradient step and do less than 10k steps (~ 1 epoch of my dataset).
Going from high dropout to no dropout may be less interpretable because the plot would just go down.
The dog breeds data is a bit special as the upper layers don’t need to be retrained. I’ve found that I could overfit even in the precompute=true phase.