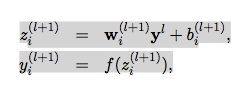Hi all. I am trying to use Dropout correctly. I understand that a Dropout layer can be placed between each layer (generally after the activation function). And that it is not used just before output.
But is there ever a reason to use Dropout on the input itself, at the start of the first layer? It seems that the reasoning for using Dropout would apply to that layer too. I have not seen this done in practice.
Yes, you can use dropout with the input as well, It will be considered as noise in the input. This can be used in denoising autoencoders. I would refer you to the original dropout paper, its very easy to read and understand as well. They mention the use of dropout after the input layer. Although I should mention that I have never seen anyone using dropout directly on input.
Using dropout on the input layer should be a good way to regularize. It is reminiscent of the bootstrap sampling technique for decision tree models where some of the samples get left out.
I understood 80% of the Dropout paper in one reading. What a pleasure to find a machine learning paper with such clear writing and lucid explanations!
I have a few questions left over after reading the paper. I realize that responding takes your time and attention, and would very much appreciate your replies.
First, an easy(?) one. Section 4 first says, “Let z(l) denote the vector of inputs into layer l,…”. Below that the equations are:
To me, it looks like z(l) is not the vector of inputs to layer l, but the intermediate activations for layer l, calculated before they are passed to that layer’s activation function. Or maybe I’m misinterpreting the notation.
Next, Section A.1 suggests increasing the number of units to n/p for layers where dropout is applied. How exactly is this done in practice, say for a Linear(m,n) layer with Dropout applied after its activation function? Would you increase the units by using Linear(m,n/p) instead?
Finally, Section B.1 describes applying dropout p=.8 to the input layer for MNIST. Does this mean literally setting a random selection of the input pixels to zero?
My problem with that is that a zero pixel means something wrt the image, for example that the pixel is positively black or white or gray. It does not mean merely that the pixel is missing. The same applies to hidden layers - a zero activation of a channel may affirmatively mean “there’s no edges here”.
So is there a valid distinction to be made between “dropped information” and “wrong information”? Or am I barking up a missing (or wrong) tree here?
Great question, I hadn’t “thought through” what actually happens when you drop an input pixel! Since the pixel has a place in a 2D structure (the image), you can’t just drop it.
What one could do is either
replace the pixel value with the median of all the other pixel values, or
replace the pixel value with a randomly generated integer between 0 and 256.
IF dropout p=0.1, this would be done to 10% of the input pixels. Which pixels are selected is determined by choosing a random value on the interval [0,1] for each pixel, and testing if it’s less than 0.1.