Hello everyone,
I’ve just started with the course.
After watching lesson 2, I was trying to come up with a model for classifying any given image as Volleyball, Beach Volleyball or Tennis based on which sport is being played in the image.
I tried out a few things things with learning rate, number of epochs and the model being used and observed a few things.
Following are my questions:
-
I ran
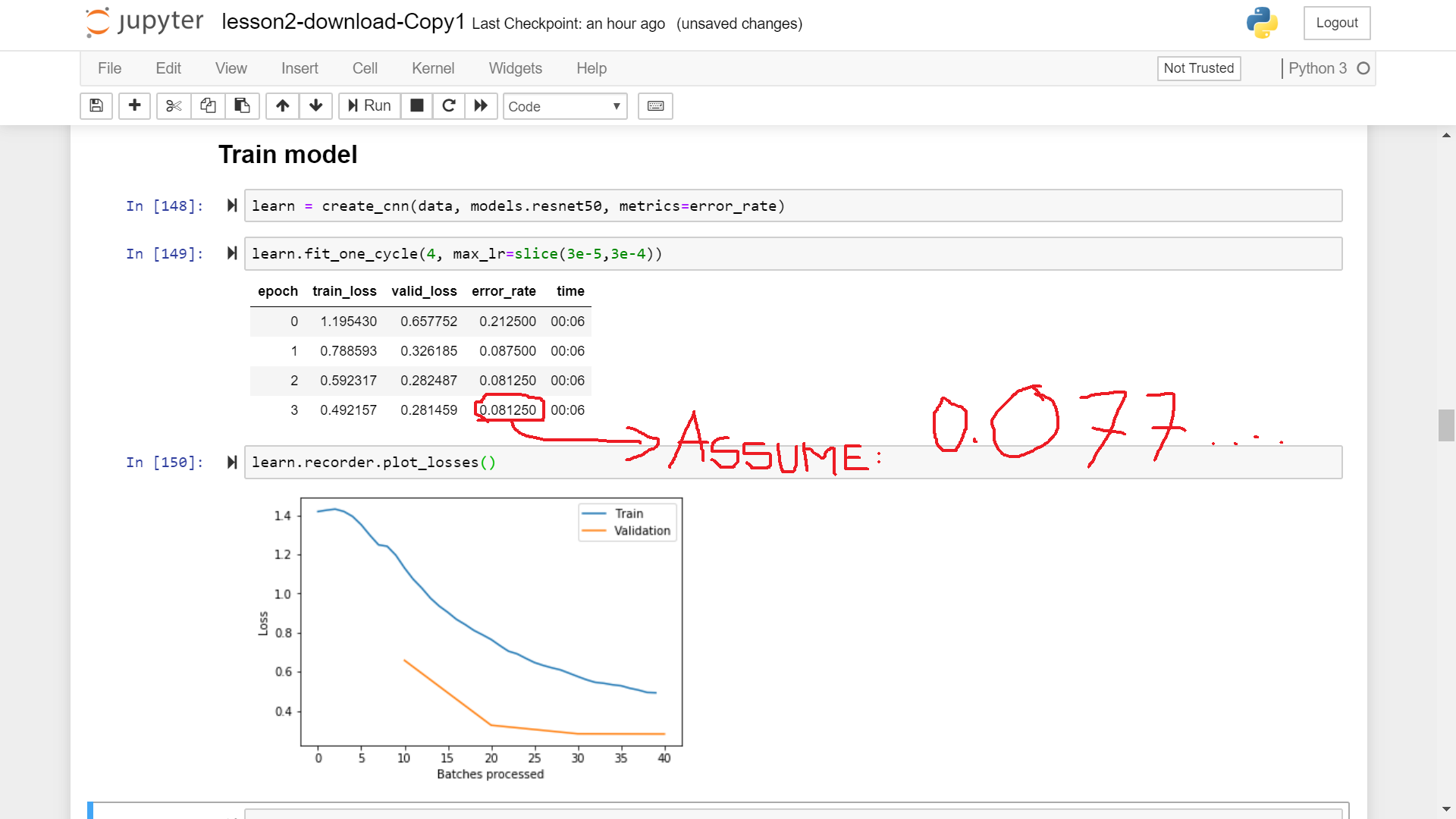
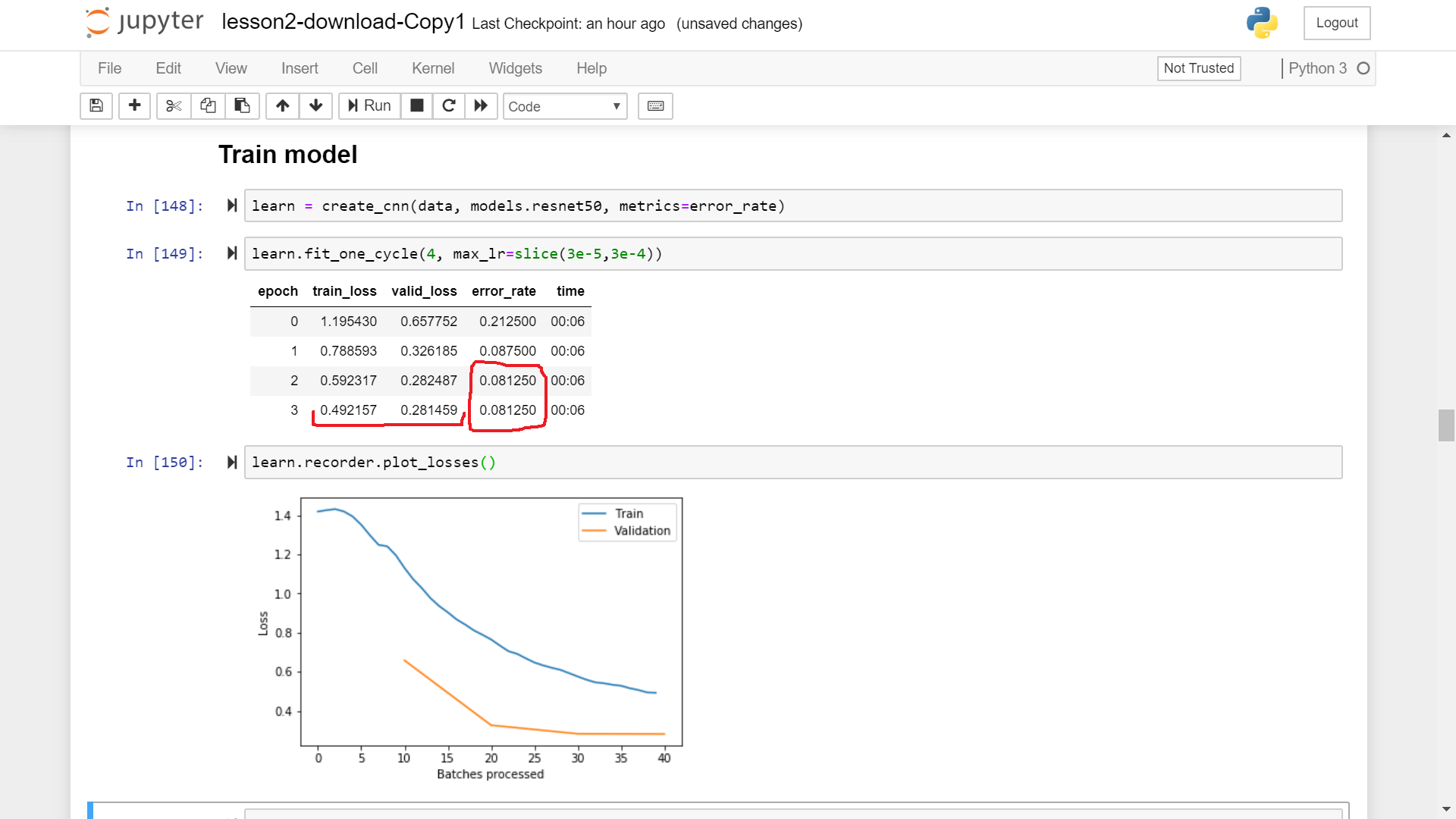
learn.fit_one_cycle(4)and after completion of 4 epochs I observed that the training loss is still much higher than the validation loss and the error_rate kept monotonically decreasing in all the 4 epochs. Does it always implies that I didn’t train my model enough and should I increase the number of epochs?
(As in the image below, with my assumption)
-
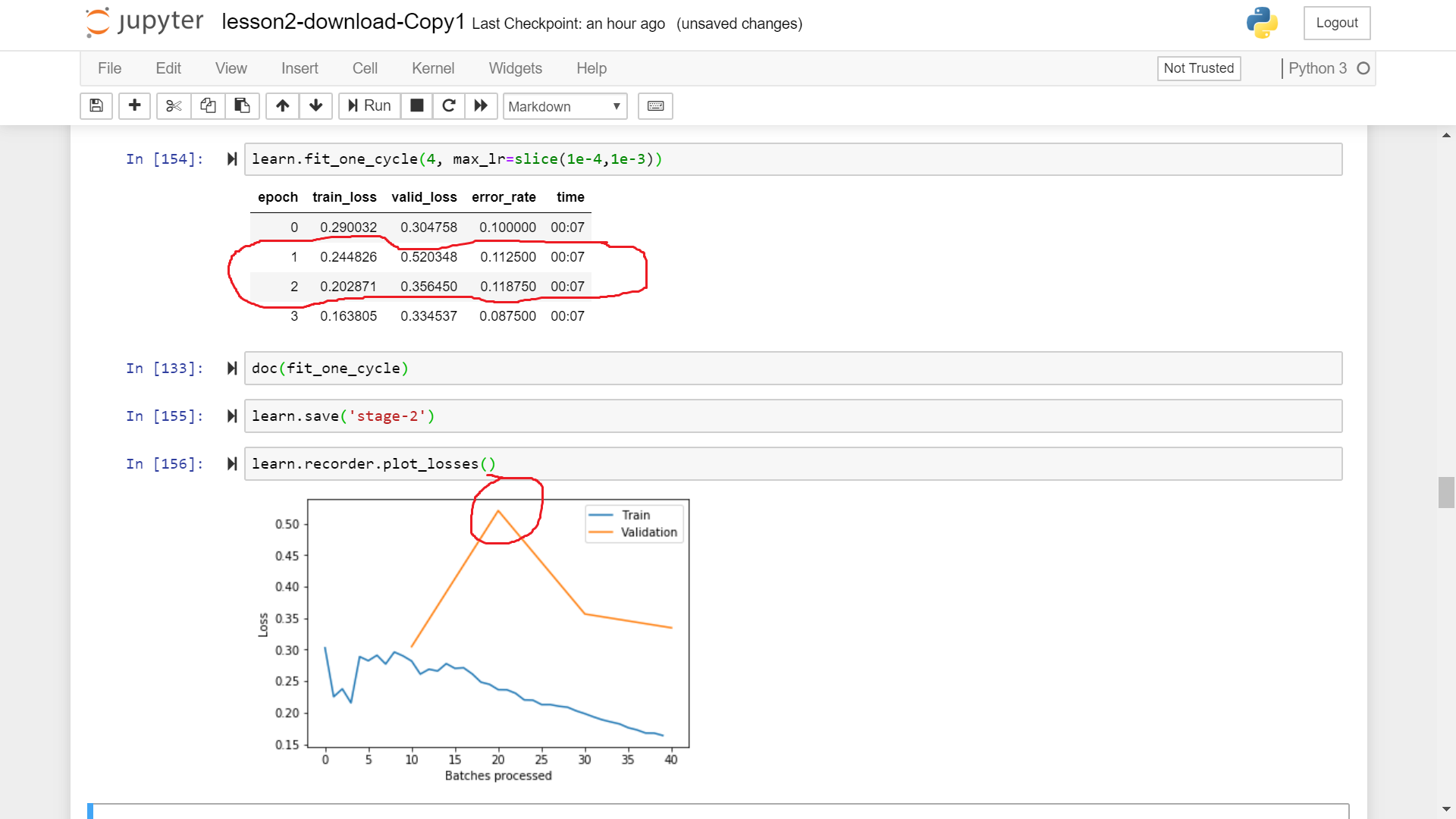
I observed spikes in the Validation loss and error_rate during training.(Image below)
What does it implies? It might not be the case that during that particular epoch in SGD the model came across a particularly difficult batch of data as even in SGD we scan all the data points in every epoch. Then what could be the reason for the spike?
Is it the case that global optimization across all the epochs does not always ensures local optimization among any sequence of epochs?
-
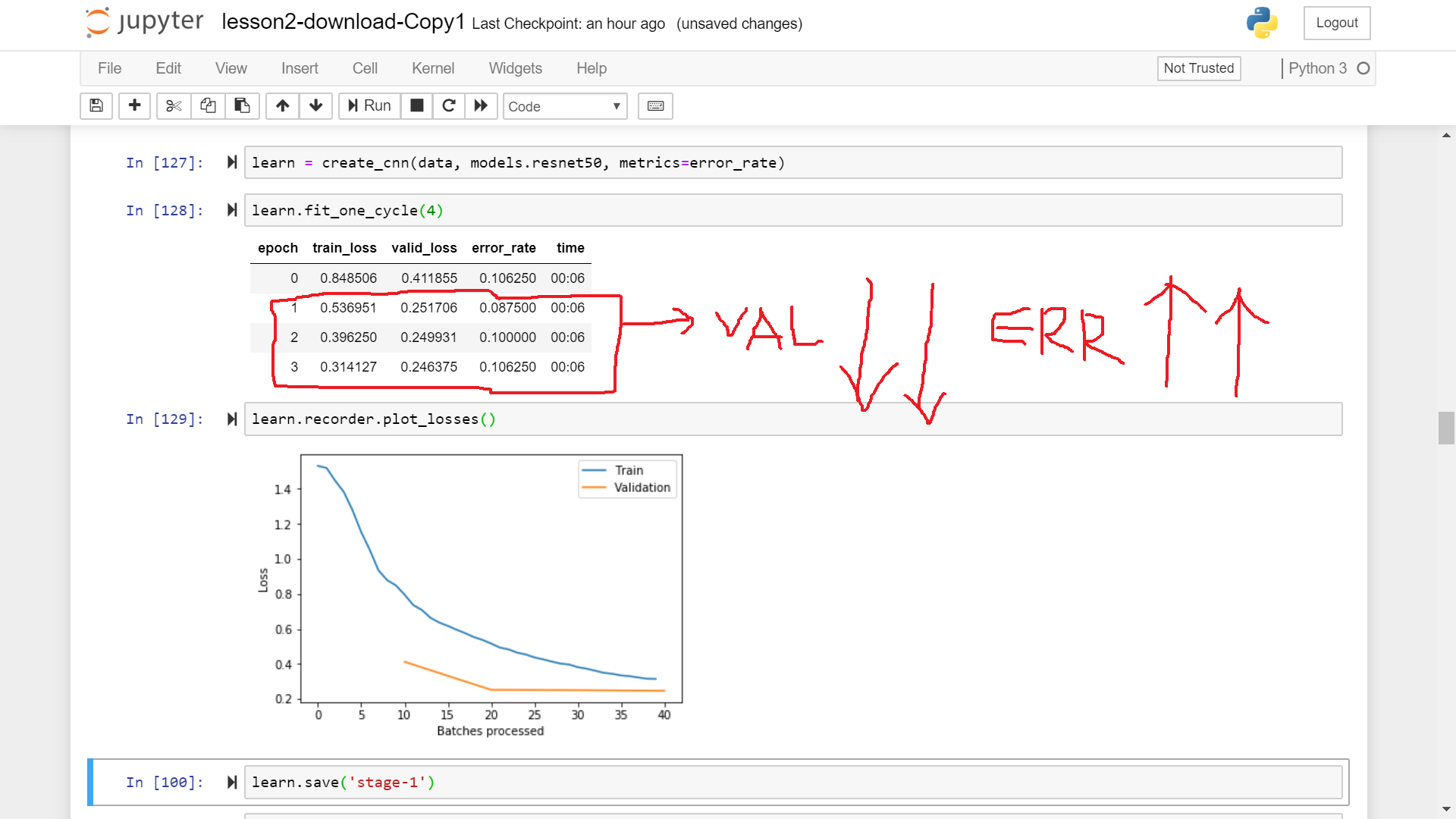
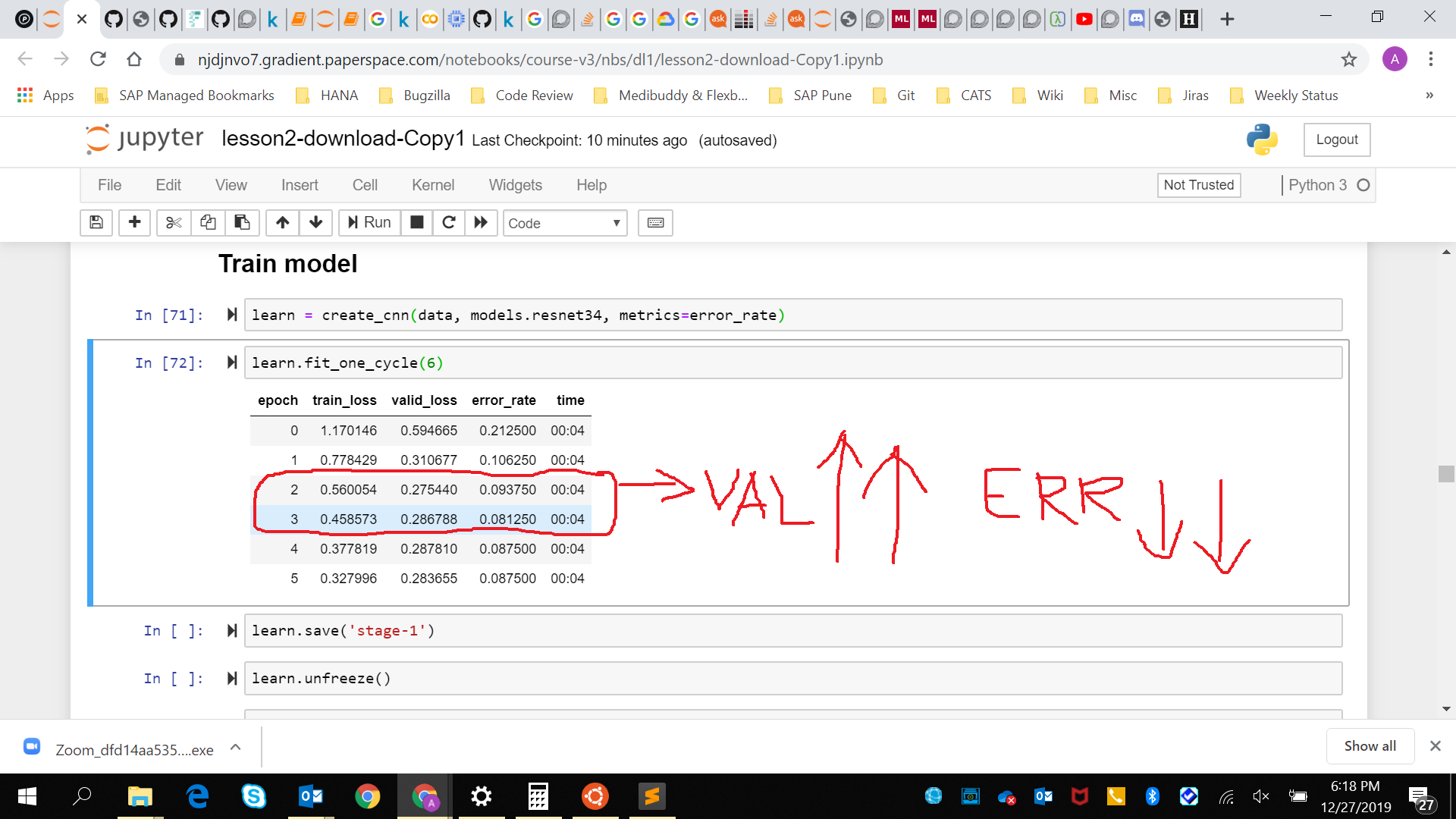
In general, changes in validation loss and error_rate during training should go hand in hand, right? I mean, if error_rate is decreasing between two epochs then validation loss should also decrease and vice-versa. However, I encountered cases where validation loss was increasing while error_rate was decreasing and where validation loss was decreasing while error rate was increasing
If the validation loss is increasing in the subsequent epochs and error_rate is decreasing then what does it implies?(Images below)
Does it means, in the case when validation loss increase while error_rate decrease, that our model is making less number of mistakes currently but the mistakes it is making are worse than the one it was making previously? That is are we going from larger number of tiny mistakes to smaller number of blunders? If yes, then is it a matter of concern and what should be the way forward?
-
In most of the training cases, I observed that the initial training loss is much higher than the validation loss. As we normalize both the losses with number of data points in training and validation sets respectively, and validation set is chosen randomly, should not the initial losses be same for both?
-
If the error rate gets stable but the training loss is still much higher than validation loss. What does it implies? Does it implies lack of training data?
Thanks
