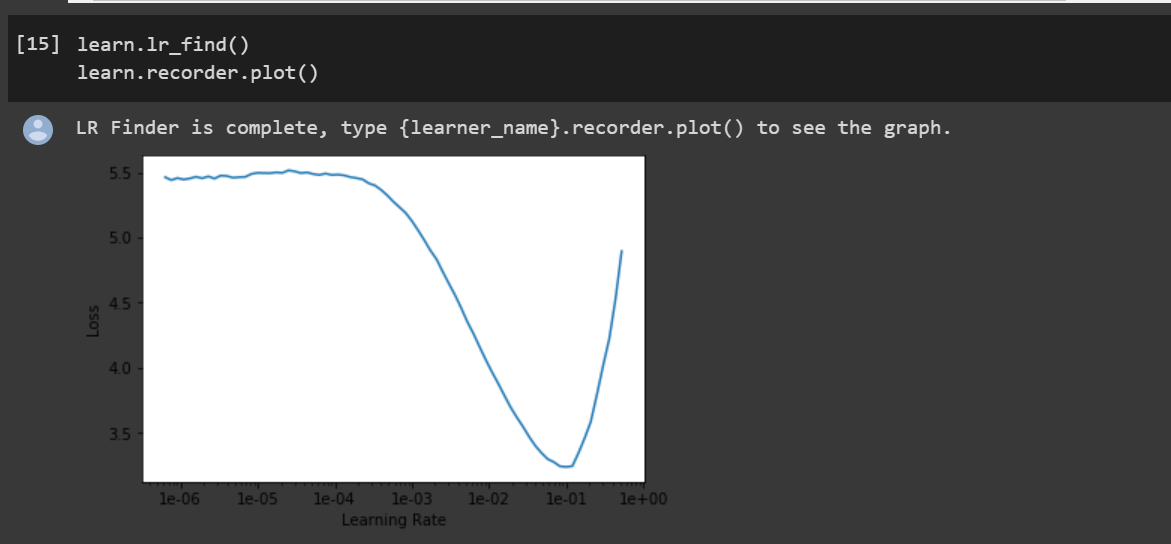
I am trying to understand the logic behind choosing learning rates for the given lr_find plot.Apparently choosing the slicing range around 1e-01 (corresponding to the lowest loss) blows the validation loss out of proportions, while slice(1e-06,1e-04) has high losses but works just fine.
I was under the notion that we choose the range where the loss is the lowest
Now, I do understand that slicing range around 1e-01 is a very high range and the exploding validation losses is something that is accepted…but then how do i use this curve(loss vs. lr)?Is it that we choose a range that has a more or less stable loss(in spite of being high)? if so then why?
When you say slicing range around 1e-01 are you actually passing in a range or just one value of LR, ie 1e-01? Single LR is applied to all layers, and having a very high value in such cases can spin you out in the wrong direction (not minimise the loss).
I think of LR as how much or how often do you want to adjust weights in the direction specified by the gradient. Providing a range of LRs enables you to give different amounts for different layers of training. Since fastai provides a pretrained model, the initial layers do not need their weights to change much - so a smaller learning rate works better for them. For later layers, you want to change by more (or more often) so a higher LR works well for updating weights.
Some thumb rules for picking LR (from the lectures):
In general always pick LR values well before loss starts to get worse (ie well before the lowest point before loss increases again). LR of 1e-03 works well for initial training.
For initial stages (before unfreeze) use an LR range that represents the sharpest downward slope (so in your plot, 1e-04 to 1e-02 perhaps).
For later stages pick 10x below the lowest point on the slope for the starting LR and 10x below previous stage LR for the ending LR (assuming there is a 10x gap between the two LRs of a slice).
‘slicing range around 1e-01’ as in I was using a range (1e-03,1e-01),which is the steepest downward slope…validation loss exploded in this case
But the results were fine for the range (1e-06,1e-04), where the loss is constant,this is the point where i did not understand.
I’m not sure I understand your question. Are you questioning why 1e-1 led to insanely large validation loss? Or why a lower range did not? What did you mean by “results were fine”?
In your plot 1e-1 almost seems like the point where loss is already increasing again. Training the last few layers at this rate implies you’re updating weights in the wrong direction each time an update is performed, and likely causing large valid-loss values.
Can you try training with slice(1e-4, 1e-2) and see what you get?
I vaguely recall there was some way to visualise the loss landscape but sorry I don’t recall the details. Perhaps explore the forum more for understanding how LR affects loss. Do share a tldr here later!