i got an error rate of 0.00 and a perfect confusion matrix.Is it possible due to a small validation set? Are there any other reasons for this result…
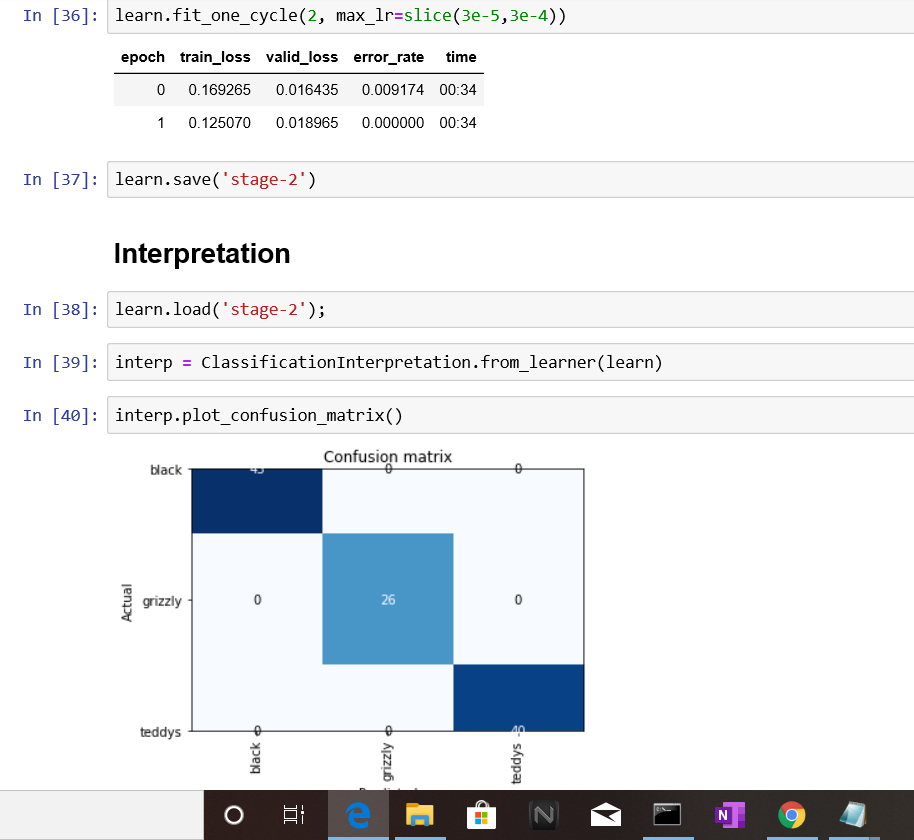
How big are your training and validation sets? And what were the training stats from stage 1? You may just have a well trained model in this case, basis default settings and given dataset!! But here is some more to think about:
Accuracy (1-error rate) is calculated on successful classifications in the validation set. Where “success” is determined based on a preconfigured threshold. It is possible that in this run the model did not misclassify anything basis that threshold, and hence the error_rate is zero. However, you still have a non zero train_loss and valid_loss which means the actual predictions are not identical to the ground truth in all the cases. So depending on what your goal is, you may either want to train some more or get more data and see if the model generalises well to those.
This thread helped me: Validation Loss VS Accuracy
Especially @radek’s answer in there. I hope he can correct me if I’ve misunderstood!
Hope this helps!
4 Likes
It looks like your data size is 26+43+40, which is probably too small for DL to be useful. If you wanted to see how well your model generalizes, you can use a test set that your model has never seen before and you’ll probably find that you won’t get 0 error rate anymore.
Typically if your training loss is larger than validation loss, it would mean you are underfitting. The usual ways to get around underfitting are: train the last layer(s) at a lower learning rate, train longer, decrease regularization. But since you have small sample size, this probably won’t work that well.
Also echo Nalini’s above suggestions to get more data.
3 Likes
the initial training stats was 0.009174 error rate for stage-1.
train_ds size = 545
val_ds size = 109
i think the validation set is an easy one to classify as you mentioned.I’ll try out to test set,get more data and see how it pans out.Thanks! @nbharatula & @newvick