Ahh Pandas! Thanks! 
Tune is the same as train in this context
Thanks @sermakarevich! I’ve got the 8th place just by getting the mean of some good models. =D
2 Likes
Congrats @thiago and @rikiya ! @jeremy 8-11 places are fastai students. I assume first 6-7 are cheaters, so…  good start
good start
6 Likes
Thank YOU @sermakarevich !
Congrats @thiago !
2 Likes
I am trying to Predict Submission Array using sample above:
import cv2
from tqdm import tqdm
df_test=pd.read_csv(‘data/dogbreeds/sample_submission.csv’)
x_test = []
for f in tqdm(df_test[‘id’].values):
img = cv2.imread(‘data/dogbreeds/test/{}.jpg’.format(f))
x_test.append(cv2.resize(img,(sz,sz)))
x_test = np.array(x_test, np.float32) / 255.
print(x_test.shape)
(10357, 224, 224, 3)
preds = learn.predict_array(x_test)
Question: Looks like channel position should be (10357, 3, 224, 224)
Please let me know if I am missing something here.
1 Like
While waiting for the models to run their epochs, I made a random_puppy_generator() function. This is a good way to understand training data (cough cough). Actually, this is super therapeutic. I can’t seem myself to stop doing this. It is fun to benchmark your own human accuracy this way.
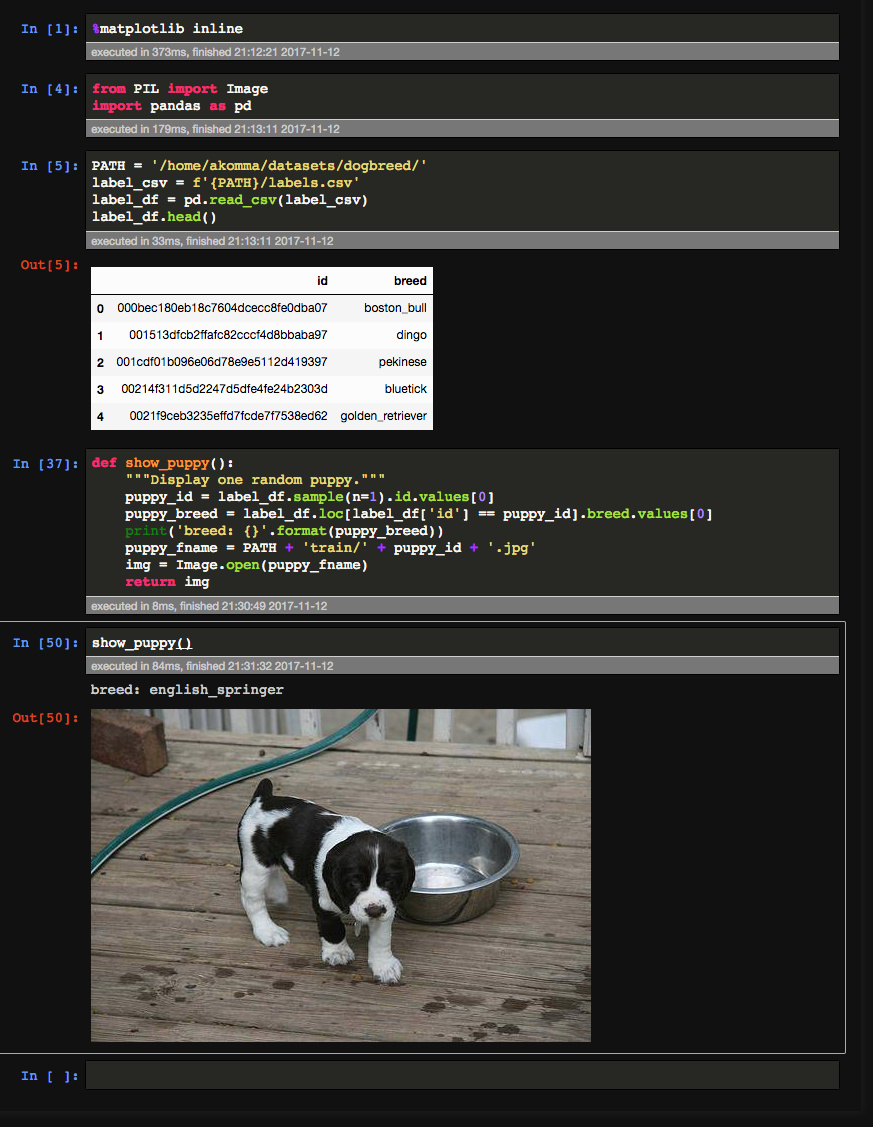
6 Likes
@rsrivastava Are there reasons why you are not using default learn.predict or learn. TTA functionality?
First solution might be to look at how images get loaded in fastai code. Second one is to look here how to do proper slicing.
@abi nice. I was playing with varying predictions from different models. Models typically mix up very similar breeds. I don’t think I can distinguish them as well
@sermakarevich I know, it is impossible for my eye to tell apart the various spaniels and terriers!
I have a few questions regarding ensembling:
- Are you using different architectures or different image size across various models?
- How are you currently ensembling models in a multinomial class problem like this?
- simple averaging the probabilities? because they have to sum up to 1 eventually…
- are you clipping the probabilities to help with the log-loss?
- Do you normally check the correlation of the predictions across classifiers before ensembling (ideally you would want less correlated predictions to get a good ensemble and it looks like that is the case for you?).
- inceptionresnet and inception_v4 so far with 4 image sizes: 300, 350, 400, 450
- simple averaging so far but I suspect there should be better ways. They should not sum up to one, log loss score can do this behind the scene. Anyway if you do average of values that one their own sum up to 1 your result also be 1.
- no I do not but I am not sure if this right. I tried some naive ways but they did not work well.
- I can do this in a better way as I have predictions on a train set.
2 Likes
Got a submission in! - (log loss: 0.282) Thanks everyone for all the tips on this thread. Very helpful.
Qn: Why were the predictions sorted by columns alphabetically – as output of learn.TTA(is_test=True). i.e.: columns were affenpinscher, afghan_hound… Is that standard when reading in labels from csv? And not just for the fastai library?
2 Likes
from_csv >> csv_source >> parse_csv_labels >> nhot_labels creates all_labels object of sorted categories. I think thats just a good practice on Kaggle, so Jeremy did it same way in fastai code.
1 Like
We don’t use cv2 to read images, so I doubt your code will be compatible. As suggested by @sermakarevich, just use learn.predict, rather than writing your own custom code.
I’m getting this error when trying to pass resized images to model
AssertionError Traceback (most recent call last)
in ()
1 data = get_data(299, bs)
2 learn.precompute = False
----> 3 learn.set_data(data)~/fastai/fastai/conv_learner.py in set_data(self, data)
104 def set_data(self, data):
105 super().set_data(data)
→ 106 self.save_fc1()
107 self.freeze()
108~/fastai/fastai/conv_learner.py in save_fc1(self)
132 self.fc_data = ImageClassifierData.from_arrays(self.data.path,
133 (act, self.data.trn_y), (val_act, self.data.val_y), self.data.bs, classes=self.data.classes,
→ 134 test = test_act if self.data.test_dl else None, num_workers=8)
135
136 def freeze(self): self.freeze_to(-1)~/fastai/fastai/dataset.py in from_arrays(cls, path, trn, val, bs, tfms, classes, num_workers, test)
305 ImageClassifierData
306 “”"
→ 307 datasets = cls.get_ds(ArraysIndexDataset, trn, val, tfms, test=test)
308 return cls(path, datasets, bs, num_workers, classes=classes)
309~/fastai/fastai/dataset.py in get_ds(fn, trn, val, tfms, test, **kwargs)
273 def get_ds(fn, trn, val, tfms, test=None, **kwargs):
274 res = [
→ 275 fn(trn[0], trn[1], tfms[0], **kwargs), # train
276 fn(val[0], val[1], tfms[1], **kwargs), # val
277 fn(trn[0], trn[1], tfms[1], **kwargs), # fix~/fastai/fastai/dataset.py in init(self, x, y, transform)
165 def init(self, x, y, transform):
166 self.x,self.y=x,y
→ 167 assert(len(x)==len(y))
168 super().init(transform)
169 def get_x(self, i):AssertionError:
here’s the code
data = get_data(299, bs)
learn.precompute = False
learn.set_data(data)
weirdly it was working couple days ago. Some changes to fastai or I’m doing something stupid ?
try to delete tmp/ folder and do it once again
Is anyone else getting this error on Crestle when downloading this competition’s data?
It’s kinda weird that I get this. I have already accepted the rules and submitted thrice before (using AWS though).
[EDIT]: I found this particular data under /datasets/kaggle/ on Crestle, but the download issue still remains.
Something with credentials ? Looks like Kaggle does not know you have accepted competition rules which is a prior requirement before you can load a dataset.
I thought so too, but I verified my credentials and tried again but it didn’t work. The same works on AWS but not on Crestle.
@sermakarevich Thanks for all the help on this thread on how to be a part of the completion. While I did not attempt a 5 fold CV, I did train the set using from_csv method. I then did the precompute = False and the three tier learning rate based training as well. I then proceeded to do learn.predict(is_test=True) and then did a np.exp on it. I then made a submission. I am getting a log loss of 13. I am confused as to why my log loss is so high. Am I doing something wrong like training less or missing any step in between. Any suggestions would be helpful.
You did not mention about test indexes, so I assume the cause might be in this:
test.index = [i.split('.jpg')[0].split('/')[-1] for i in data.test_dl.dataset.fnames]
You need to control the order of your predictions - it is not the same as in sample_submission file. Order of categories is the same because its in alphabetical order.
3 Likes