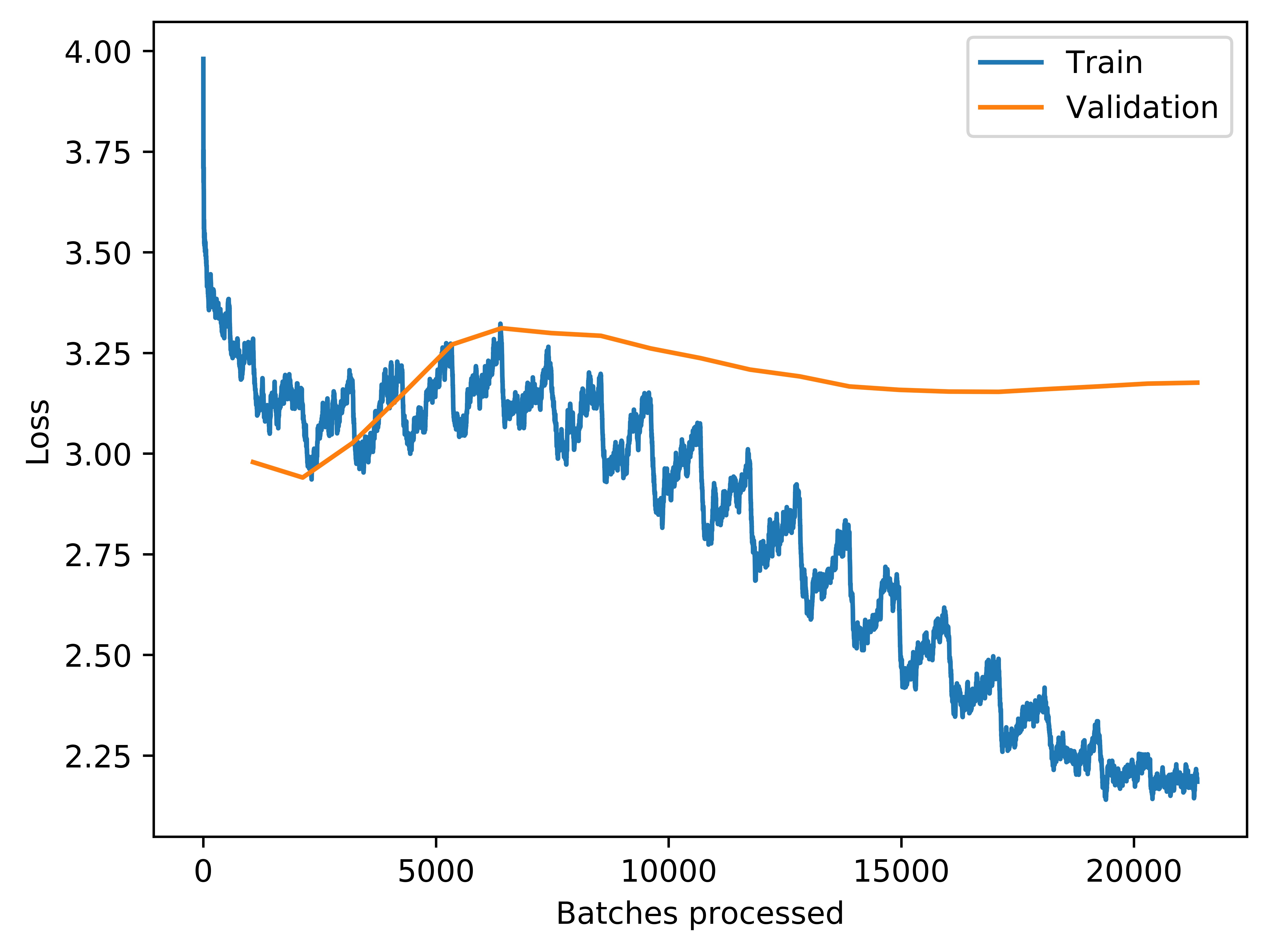
I’m training an ULMFiT language model on around 80K tweets using the following code
learn = language_model_learner(data_lm, arch=AWD_LSTM, drop_mult=0.8)
learn.freeze()
learn.fit_one_cycle(cyc_len=1, max_lr=1e-2, moms=(0.8, 0.7))
learn.unfreeze()
learn.fit_one_cycle(cyc_len=20, max_lr=1e-2, moms=(0.8, 0.7))
# plot losses
losses_lm_fig = learn.recorder.plot_losses(return_fig=True)
losses_lm_fig.savefig(path / 'losses_lm_fig.jpg', dpi=1000, bbox_inches='tight')
Should I increase the drop_mult or lower the number of epochs?
As you are clearly overfitting, you have several options:
- Increasing dropout is one, but be careful not to go too high or else your network will learn nothing
- You can add more weight decay (argument
wd in fit_one_cycle) as it will prevent your weights from being too big.
- You can use a smaller/simpler model.
- You can add more data
The latter option is clearly the best but the hardest as you can’t get infinite data. Just keep in mind that sometimes there is nothing more for your model to learn and your dataset is simply not good enough for the task you are trying to learn.
Finally, on the number of epochs: you can lower it, but it will not make you reach a better validation loss than the best one you get here. Just use a callback to store the weights when validation loss is at its best and it should be ok. Also you might want to do more epochs before unfreezing.
Yes, I will try using a callback to save the best version. Why do you recommend more epochs before unfreezing? In lesson 4 of the fastai course, the language model demonstrated for IMDb text classification only trains for 1 epoch before unfreezing.
When frozen the model is effectively smaller and will therefore not tend to overfit as much. I personally like to see how good a model can get when frozen before trying to unfreeze. And most of the time unfreezing doesn’t make it better, it just makes it overfit. So as long as your model learns, I suggest not unfreezing it. Once it is as good as it can be you can try to unfreeze it to see if you make any meaningful progress.
That makes sense. Do you also think that a similar approach should be used when training the classifier? Right now, I am doing
# gradual unfreezing
learn.fit_one_cycle(cyc_len=1, max_lr=1e-3, moms=(0.8, 0.7))
learn.freeze_to(-2)
learn.fit_one_cycle(1, slice(1e-2 / (2.6 ** 4), 1e-2), moms=(0.8, 0.7))
learn.freeze_to(-3)
learn.fit_one_cycle(1, slice(5e-3 / (2.6 ** 4), 5e-3), moms=(0.8, 0.7))
learn.unfreeze()
learn.fit_one_cycle(4, slice(1e-3 / (2.6 ** 4), 1e-3), moms=(0.8, 0.7), callbacks=[callbacks.SaveModelCallback(learn, monitor='f_beta', name='model')])
Would you recommend doing [1, 1, 4] instead of [1, 1, 1, 4]? Or maybe something even more extreme like [2, 2, 2]?
Well I honestly don’t know, you have to try and see what works best.