Hello, I was trying to understand whether the model returned by fine_tune is the one after the last epoch or the one leading to the best valid loss. Any clarification on that?
I’ve checked both the videos and the forum and I didn’t find a clear answer (but I might have missed it). I also tried to look at the source code, but I was only able to track down the chain of internal call has kind of Learner.fine_tune → Learner.fit_one_cycle → Learner.fit → Learner._do_fit but then I wasn’t able to figure out what happens…
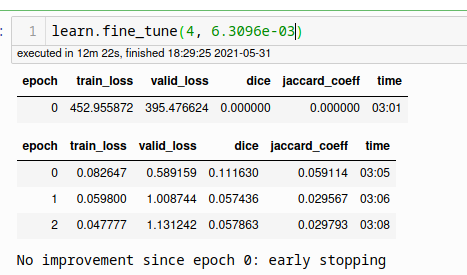
Indeed, it stops as expected because no improvements were made. So my guess would be that perhaps the learning rate is too high and I could have a better tuning with a lower one. However, when I try fine-tuning a bit more I get this output:
This might be due to multiple factors, but valid loss and dice coefficients in the second run are similar to the final values obtained in the first run.
So my doubt is: am I using the callback correctly?
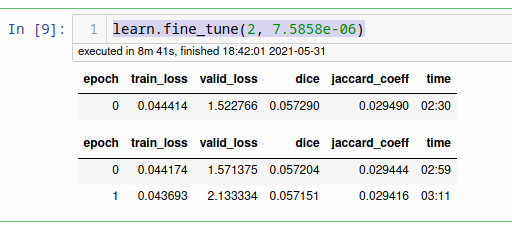
You are, your metric always improved in the second one. What it looks at is on each call to fit, not the overall callings (as fine_tune basically calls fit twice)
wait in the second run the dice coefficient is going down (…290, …204, …151) which means the model gets worse. Are you saying that it’s comparing the metrics in the “wrong direction”?
My understanding is that the comparison is done with np.greater since the metric doesn’t contain neither ‘error’ nor ‘loss’. So by looking at the two runs I would assume that the final model I get is the one coming from epoch 0 of the first run, which is dubious as results of the second run are more similar to epochs 1 and 2 than epoch 0.
Is there a way to get predictions and metrics on the whole training set so to compare with fine_tune results?