Hi,
Yestererday evening I saved my intermediate model using learn.save(‘modelname’).
However, when today I load this and check the confusion matrix on my test set to see it is loaded correctly I suddenly have a very bad confusion matrix. Is it possible that the save only saves my model architecture but not the weights I had yestererday eve ? How do I have to save both my model architecture and weights ? Do I have to do both learn.save and learn.export ?
learn.save(‘25epochs_with_testdata’)
df_test.to_pickle(‘df_test’)
df_valid.to_pickle(‘df_valid’)
df_train.to_pickle(‘df_train’)df_test=pd.read_pickle(“df_test”)
df_valid=pd.read_pickle(“df_valid”)
df_train=pd.read_pickle(“df_train”)
learn = learn.load(‘25epochs_with_testdata’)
preds, pred_values = get_preds_as_nparray(DatasetType.Test)
predicted=pd.DataFrame(pred_values)
predicted.columns=[‘predicted’]
testcf=df_test.join(predicted)
pd.crosstab(testcf.ylabel, testcf.predicted, margins=True, margins_name=“Total”)
gives now:
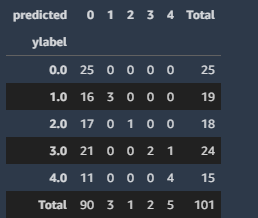
while I had:
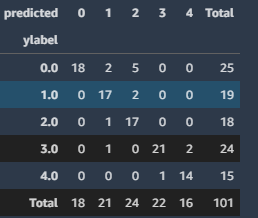
I’m using fastai v1.0.61 with the Roberta model for Dutch:
class FastAiRobertaTokenizer(BaseTokenizer):
def init(self, tokenizer: RobertaTokenizer, max_seq_len: int=128, **kwargs):
self._pretrained_tokenizer = tokenizer
self.max_seq_len = max_seq_len
def call(self, *args, **kwargs):
return self
def tokenizer(self, t:str) → List[str]:
return [“”] + self._pretrained_tokenizer.tokenize(t)[:self.max_seq_len - 2] + [“”]class RobertaTokenizeProcessor(TokenizeProcessor):
def init(self, tokenizer):
super().init(tokenizer=tokenizer, include_bos=False, include_eos=False)class RobertaNumericalizeProcessor(NumericalizeProcessor):
def init(self, *args, **kwargs):
super().init(*args, vocab=fastai_roberta_vocab, **kwargs)def get_roberta_processor(tokenizer:Tokenizer=None, vocab:Vocab=None):
return [RobertaTokenizeProcessor(tokenizer=tokenizer), NumericalizeProcessor(vocab=vocab)]
#return [RobertaTokenizeProcessor(tokenizer=tokenizer), RobertaNumericalizeProcessor(vocab=vocab)]#create a databunch for Roberta
class RobertaDataBunch(TextDataBunch):
@classmethod
def create(cls, train_ds, valid_ds, test_ds=None, path:PathOrStr=‘.’, bs:int=64, val_bs:int=None, pad_idx=1,
pad_first=True, device:torch.device=None, no_check:bool=False, backwards:bool=False,
dl_tfms:Optional[Collection[Callable]]=None, **dl_kwargs) → DataBunch:
“Function that transform thedatasetsin aDataBunchfor classification. Passes**dl_kwargson toDataLoader()”
datasets = cls._init_ds(train_ds, valid_ds, test_ds)
val_bs = ifnone(val_bs, bs)
collate_fn = partial(pad_collate, pad_idx=pad_idx, pad_first=pad_first, backwards=backwards)
train_sampler = SortishSampler(datasets[0].x, key=lambda t: len(datasets[0][t][0].data), bs=bs)
train_dl = DataLoader(datasets[0], batch_size=bs, sampler=train_sampler, drop_last=True, **dl_kwargs)
dataloaders = [train_dl]
for ds in datasets[1:]:
lengths = [len(t) for t in ds.x.items]
sampler = SortSampler(ds.x, key=lengths.getitem)
dataloaders.append(DataLoader(ds, batch_size=val_bs, sampler=sampler, **dl_kwargs))
return cls(*dataloaders, path=path, device=device, dl_tfms=dl_tfms, collate_fn=collate_fn, no_check=no_check)#create a Roberta specific textclass
class RobertaTextList(TextList):
_bunch = RobertaDataBunch
_label_cls = TextListfeat_cols = “t
ekst_cleaned”
label_cols = “result”
#initialize our Fastai tokenizer
fastai_tokenizer = Tokenizer(tok_func = FastAiRobertaTokenizer(dtokenizer, max_seq_len=512), pre_rules=, post_rules=)def set_seed(x=42): #must have dls, as it has an internal random.Random
random.seed(x)
np.random.seed(x)
torch.manual_seed(x)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
if torch.cuda.is_available(): torch.cuda.manual_seed_all(x)set_seed(125)
processor = get_roberta_processor(tokenizer=fastai_tokenizer, vocab=fastai_roberta_vocab)
data = RobertaTextList.from_df(df_train, “.”, cols=feat_cols, processor=processor)
.split_from_df(col=‘valid’)
.label_from_df(cols=label_cols,label_cls=CategoryList)
.add_test(RobertaTextList.from_df(df_test, “.”, cols=feat_cols, processor=processor))
.databunch(bs=32, pad_first=False, pad_idx=0) #pad till maximum sequence length and ignore padsimport torch
import torch.nn as nn
from transformers import RobertaModel
#from transformers import RobertaForSequenceClassificationclass CustomRobertatModel(nn.Module):
def init(self,num_labels=2):
super(CustomRobertatModel,self).init()
self.num_labels = num_labels
self.roberta = RobertaModel.from_pretrained(“pdelobelle/robbert-v2-dutch-base”)
#self.roberta= RobertaForSequenceClassification.from_pretrained(“pdelobelle/robbert-v2-dutch-base”)
self.dropout = nn.Dropout(.05)
self.classifier = nn.Linear(768, num_labels)def forward(self, input_ids, token_type_ids=None, attention_mask=None, labels=None): _ , pooled_output = self.roberta(input_ids, token_type_ids, attention_mask, return_dict=False) #return_dict toegevoegd. Cfhttps://stackoverflow.com/questions/66846030/typeerror-linear-argument-input-position-1-must-be-tensor-not-str logits = self.classifier(pooled_output) return logitsroberta_model = CustomRobertatModel(num_labels=5)
learn = Learner(data, roberta_model, metrics=[accuracy])
learn.model.roberta.train() # set roberta into train mode
learn.fit_one_cycle(1, max_lr=1e-5)
… trained a couple more epochs and saved the model
learn.save(‘25epochs_with_testdata’)
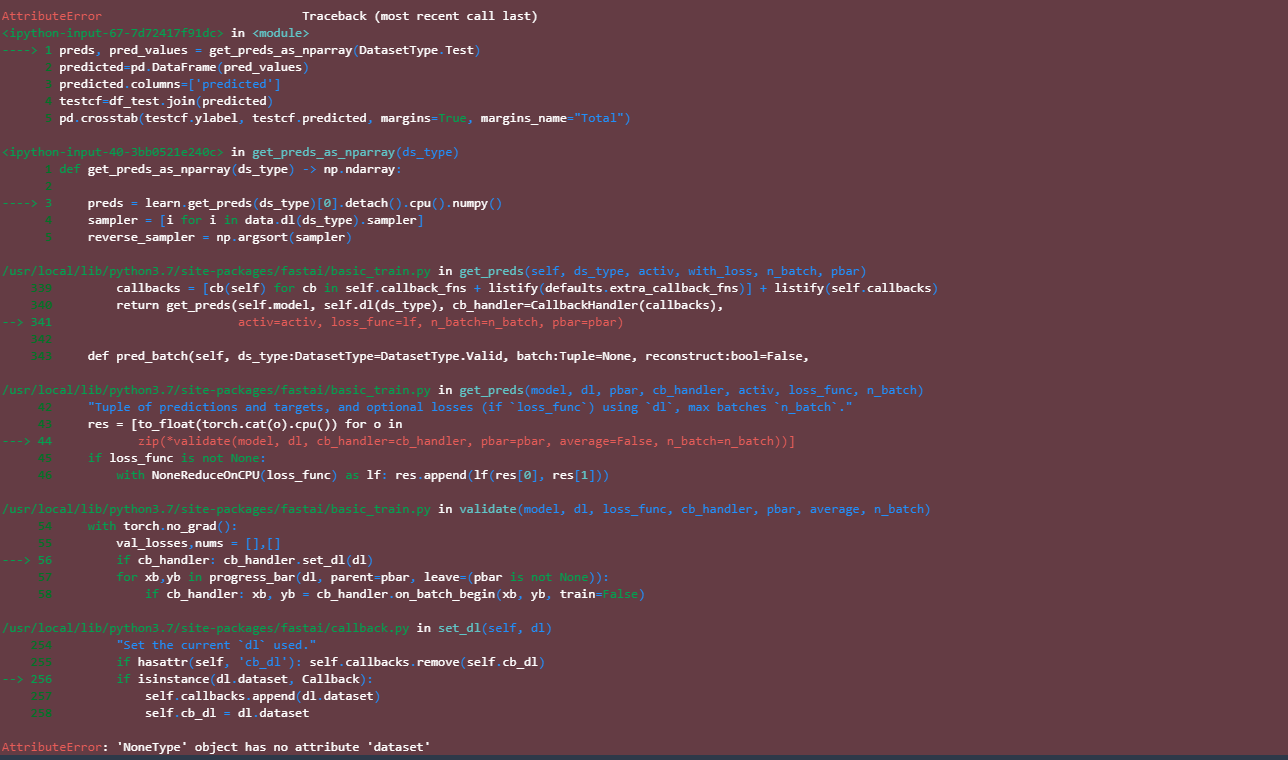
 Thanks for your help !
Thanks for your help !