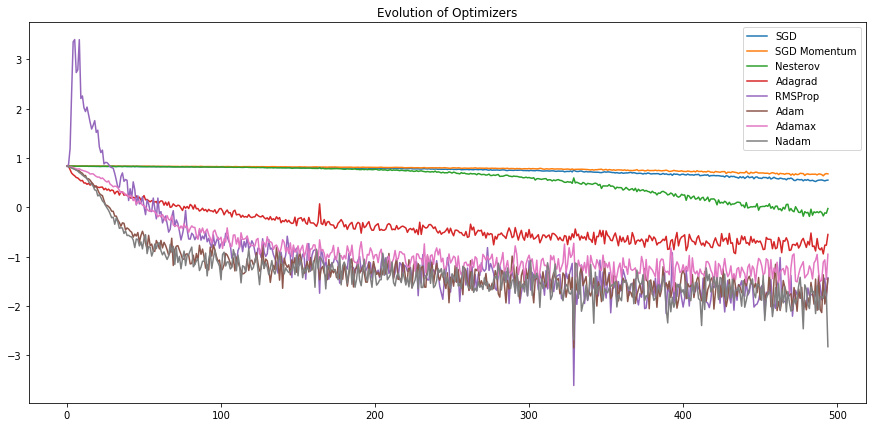
After reading this great blog post http://ruder.io/optimizing-gradient-descent/ and seeing fascinating new optimizer implementations in Fast.ai. I wanted to give it a chance and started implementing them with PyTorch from scratch. I used MNIST dataset to benchmark different optimizers. So far, I’ve finished SGD, SGD Momentum and Nesterov. But Nesterov doesn’t converge faster than SGD Momentum as expected. There might be an issue about my code but I couldn’t find anyhing. Hope that someone can help me out with this.
What a great idea - and thanks for sharing. I don’t particularly find nesterov faster, FYI; it depends on the dataset. One test of your code would be to try the pytorch optim implementation on your dataset with and without nesterov, and see if your performance is the same.
Also, I like your clear approach of showing a basic Dataset, and basic fully connected net. Really well done. Here’s a slight refactoring of your forward() BTW (untested):
def forward(self, x):
for lin in self.linears:
lin_x = lin(x)
x = F.relu(lin_x)
return F.log_softmax(lin_x)
(Also - I forgot to mention, in the code you showed me yesterday I think you forgot to include F.relu.)
Thanks for the feedback, I should definitely cross check my results with PyTorch. That way I can be sure, but I assumed a smarter ball to be always faster than a regular ball with momentum. Nevertheless, I shouldn’t be assuming as you’ve been telling us
For the second part, autoencoder project, I didn’t include any non-linearity since I read this in Kaggle discussion:
Question: Cool - thank you You mentioned you have used linear activation function - e.g. - just input and weight multiplication Did you use it for all (any specific reason?) or only for bottleneck layer?
And this layer activations - did you just concat them in one huge dataset as you mentioned of 1-10k dimension?
Michael: I recommend linear activation in the middle layer of bottleneck setup because relu truncate the values <0. Yes just concat to a long feature vector. Here for a deep stack DAE 221-1500-1500-1500-221 you get new dataset with 4500 features.
But definitely I can try both with and without activation as a step of ablation study. What would you say to that ?
It’s very interesting before normalizing data all Nesterov was behaving very awkward but after normalizing it seems to be right. It probably highly depends on the loss curve and what kind of function we are trying the optimize. I actually wouldn’t notice that I’ve forgotten to normalize my data if it wasn’t for Adagrad’s way of saying ‘Hey something is wrong with your setup’
Nevertheless, it’s also very cool to see how each optimizer has it’s own unique nature and how cumbersome it would have been to find good ways of optimizing our loss function if it wasn’t for the SOTA techniques we are readily using in Fast.ai. Again, appreciated
Note: I’ve updated the notebook in my github repo for those who would like to check out, recommend anyhing or just have a glimpse at it More will come after exams, need to study some TS and ML too…
Update: SGD, SGD Momentum, Nesterov, Adagrad, RMSProp, Adam, Adamax are all done and cross checked with PyTorch + Nadam (Currently not available in optim module). They seem solid, so you can check the implementations without any hesitation, thanks !
Hey Ravi that code is not intended to run but rather to show the algotihm. So you can ignore parts with ### Algorihtm header. NB raw was not visually good on github, so I left it as a code chunk.

 More will come after exams, need to study some TS and ML too…
More will come after exams, need to study some TS and ML too…