python -m fastai.launch train_cifar.py --gpu=3
It throws an Division by Zero since n_gpu is set to 0 by:
def num_distrib():
"Return the number of processes in distributed training (if applicable)."
return int(os.environ.get('WORLD_SIZE', 0))
Then I set inside main func of the script:
os.environ['WORLD_SIZE'] = '4'
os.environ['CUDA_VISIBLE_DEVICES']='3,4,5,6'
and run python -m fastai.launch train_cifar.py --gpu=3
This time getting
Traceback (most recent call last):
File "train_cifar.py", line 8, in <module>
def main( gpu:Param("GPU to run on", str)=None ):
File "/home/turgutluk/fastai/fastai/script.py", line 40, in call_parse
func(**args.__dict__)
File "train_cifar.py", line 23, in main
num_workers=workers).normalize(cifar_stats)
File "/home/turgutluk/fastai/fastai/vision/data.py", line 108, in from_folder
if valid_pct is None: src = il.split_by_folder(train=train, valid=valid)
File "/home/turgutluk/fastai/fastai/data_block.py", line 199, in split_by_folder
return self.split_by_idxs(self._get_by_folder(train), self._get_by_folder(valid))
File "/home/turgutluk/fastai/fastai/data_block.py", line 195, in _get_by_folder
return [i for i in range_of(self) if self.items[i].parts[self.num_parts]==name]
File "/home/turgutluk/fastai/fastai/data_block.py", line 195, in <listcomp>
return [i for i in range_of(self) if self.items[i].parts[self.num_parts]==name]
IndexError: index 0 is out of bounds for axis 0 with size 0
But when I set all these environment variables:
os.environ['WORLD_SIZE'] = '4'
os.environ['CUDA_VISIBLE_DEVICES']='3,4,5,6'
os.environ['RANK'] = '3'
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '1234'
then it hangs.
python fastai/fastai/launch.py --gpus=3,4,5,6 fastai/examples/train_cifar.py --gpu=3
Gives the same index out of range error.
[EDIT]
with:
python fastai/fastai/launch.py --gpus=3,4,5,6 fastai/examples/train_cifar.py --gpu=3
It works, I was missing the CIFAR data after all. I will use fastai/launch.py to spawn process for my own script and see if it works.
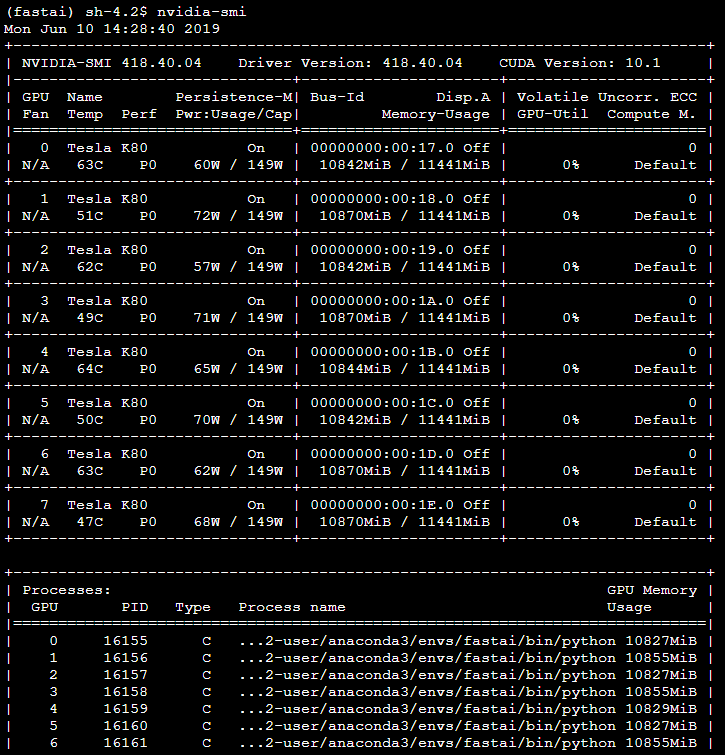
Another question I have is that I am only seeing utilization at gpu=3 looking at watch gpustat but I was expecting it to be distributed across gpus=3,4,5,6. Am I missing something? It looks like there are 4 processes on running on gpu=3.
[3] GeForce RTX 2080 Ti | 87’C, 99 % | 9084 / 10989 MB | turgutluk(2263M) turgutluk(2271M) turgutluk(2269M) turgutluk(2271M)
[4] GeForce RTX 2080 Ti | 33’C, 0 % | 10 / 10989 MB |
[5] GeForce RTX 2080 Ti | 35’C, 0 % | 10 / 10989 MB |
[6] GeForce RTX 2080 Ti | 29’C, 0 % | 10 / 10989 MB |
[SOLVED]
It should be like this since list(‘3456’) is the correct format:
python fastai/fastai/launch.py --gpus=3456 fastai/examples/train_cifar.py
It really scales linearly with constant batch size, wow 
Thanks!