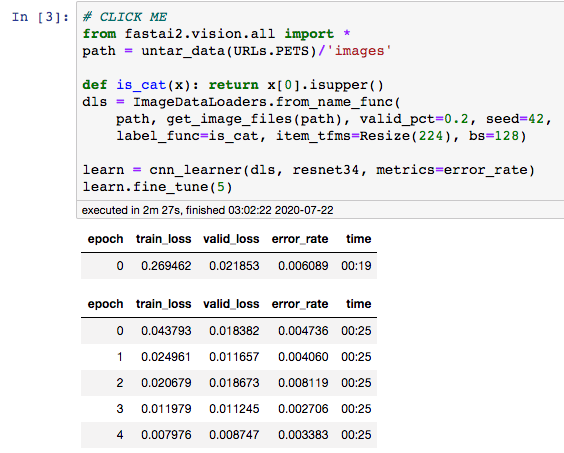
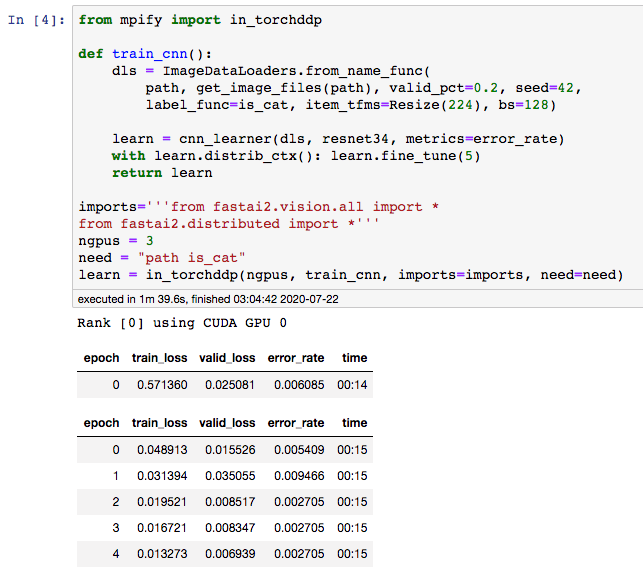
I’m happy to announce the release of mpify, a library that makes multiprocessing experiments, multi-GPUs, and Jupyter to play nice together on a single host.
The immediate application is, now it is possible to train fastai2’s course-v4 examples (most of them) in distributed-data-parallel mode, using multiple GPUs, within Jupyter itself. E.g.
In my previous attempt Ddip for fastai v1, I used a much bigger hammer of ipyparallel. It maintains a persistent pool — cumbersome + lot of state maintenance — and yet the Jupyter shell couldn’t get back the trained Learner object after a DDP training loop.
Second time around, thanks to the wonderful multiprocess package (a fork of the standard Python multiprocessing), I’ve designed mpify to be a general purpose, one-time, multiprocess function execution launcher, in which the Jupyter shell process can participate and get back the result (or results from all processes). No state maintenance, starts from a clean slate every time.
User can provide a custom context manager to set up the execution environment. Enabling distributed training of PyTorch/fastai2 in Jupyter is the first application of that.
What about fastai v1?
Unfortunately I don’t have immediate plan to back port this to support fastai v1, in light of the push to shift to v2. But for those who wanna try, I am happy to advise, it’s probably only needs a custom context manager.
Exciting stuff. However, this code will not work for me when trying to run within WSL2. It highly unlikely that it is your code, but rather a limitation of the whole GPU on WSL2 still being in its infancy. I can get your code to run with ngpus = 1, but I get an error which references NCCL when ngpus = 2.
RuntimeError: NCCL error in: /pytorch/torch/lib/c10d/ProcessGroupNCCL.cpp:514, unhandled system error, NCCL version 2.4.8
…
AttributeError: 'Sequential' object has no attribute 'module'
In the next iteration of the WSL2 kernel or when drivers are updated, I will try again. Until then, keep up the good work.
Sorry I should have mentioned the environment I developed this and tested it with is Linux/Ubuntu. I do not have a WSL2 environment to test this with.
The error you are getting doesn’t look like a GPU ot CUDA specific thing. It seems to be more related to python objects not being serialized over properly.
Either the “multiprocess” library just doesn’t work on wsl2 yet, or some modules or variable isn’t included in the imports=/need= list.
Which example did you run to trigger this? Or could u point me at the code ? Thanks!
Better yet, could you be so kind to raise this as a new issue on in the mpify repo ? If you do, please include pointer to the source code, and part of the Jupyter server log when this happened (if u can disclose)? Thank you very much for the input.