When trainkng a deep learning model from scratch would it be useful to still use discriminative learning rates?
I wouldn’t think so as the idea behind discriminative learning rates was that earlier layers have basic common features that do not need to be adjusted much and can use a lower learning rate, but here we have a new model which hasn’t learned anything yet so if anything discrimimative learning rates would slow down training of the earlier layers?
Bumping this up because I think this question should get an answer, or at least some discussion regarding best practices for using discriminative learning rates.
My intuition is that discriminitive learning rates would only really work if you have sensible weights for your early layers. When you start with an uninitialized network this is not the case.
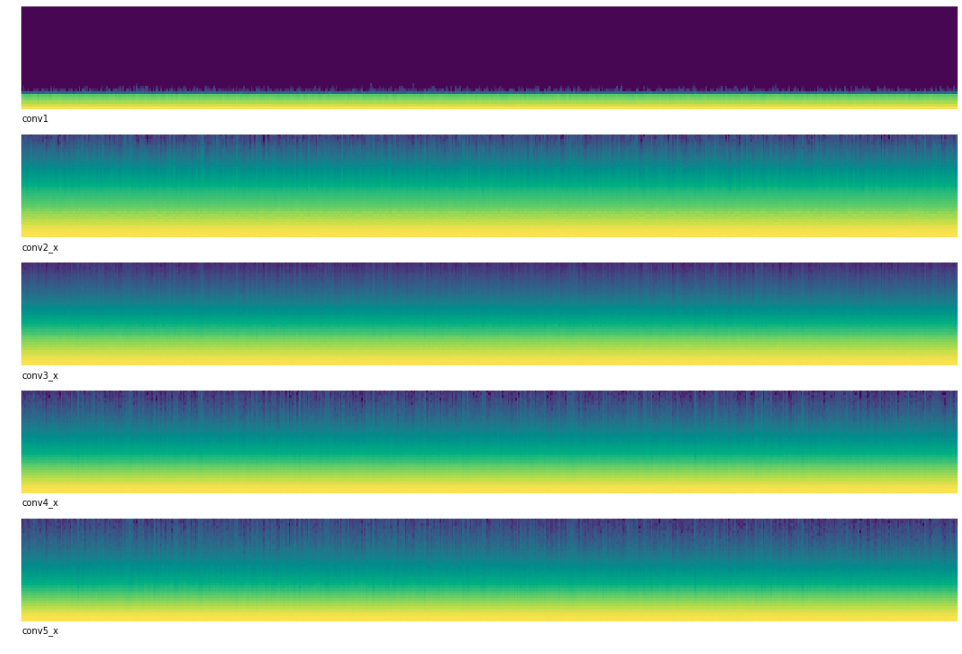
This looks much better! It seems like it will improve things as my f1score improved from 0.238104 to 0.468753 with a corresponding improvement in loss.
Thanks for the interesting visualizations. This is what I thought, but I see so many people (especially on Kaggle) using discriminative learning rates for models that are not pretrained and got good results. I need to try to get even better results without discriminative learning rates!
Yeah I saw that too. I think they (like myself) are using them out of habit. Most Kaggle competitions don’t forbid you from using pretrained networks so it’s easy to get into the habit of always using discriminitive learning rates.
My intuition could be completely wrong, but it is that the effect of weight changes is related to the depth of layer in which they are made. Butterfly wings may cause a storm 10,000km away but not 10m away. I’d like a more reasoned answer as well.