Hello everyone,
I’m experimenting with the deepweeds dataset ( a multi-class dataset of 9 classes of weeds, also available as part of tensorflow-datasets), i’m using keras.
when i run
model.evaluate i get a different accuracy than if i run model.predict on each image (in a for loop)
also, the creator of the dataset published their model (.hdf5 file) (they did transfer learning on resnet50).
When i run model.evaluate on his model i get a very low accuracy and a very high loss (same with model.predict on the test_generator), but when i calculate the accuracy by running model.predict on each image i get a very good result:
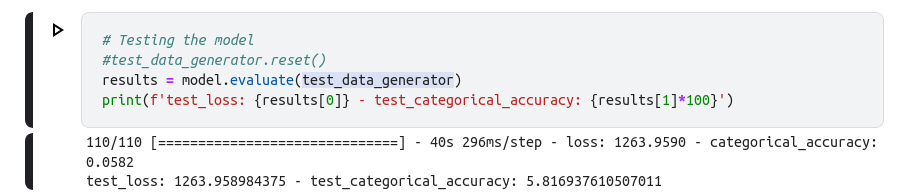
![]()
here is his code:
here is my code (the last cell is the prediction done image by image):
i have several questions:
1/why are the results of model.evaluate/model.predict so different than running model.predict image by image? (i tried training my models, and i get a different reading too but the exact opposite, high for model.evaluate, and lower for model.predict run on each image)
2/why does his code work? he used sigmoid for activation instead of softmax, and he used binary_crossentropy as the loss function instead of categorical_corssentropy, and used accuracy as a metric instead of categorical_accuracy
3/why did he augment the validation dataset? shouldn’t only the training dataset be augment in case of a small dataset to introduce variations
Thank you very much
Edit: the dataset is divided into test/validation/training by the creator, there are csv files for each in the labels directory in the git repo