Hi everyone!
I’ve seen that with vision learner there are a lot of models to try. I’m currently studying for my thesis and I was wondering if there is an equivalent way of trying new models for the tabular learner too. I managed to get pretty good results with the “default” tabular learner but just for research purposes I wanted to try different things. Is creating a new model from scratch the only way to do that or there are models that can be tried?
My understanding, which is discussed in this forum post, is that the reason there aren’t pretrained models for tabular data is because the inputs (columns) vary depending on the use case. However, that post is 3 years old and there may be advances in that area.
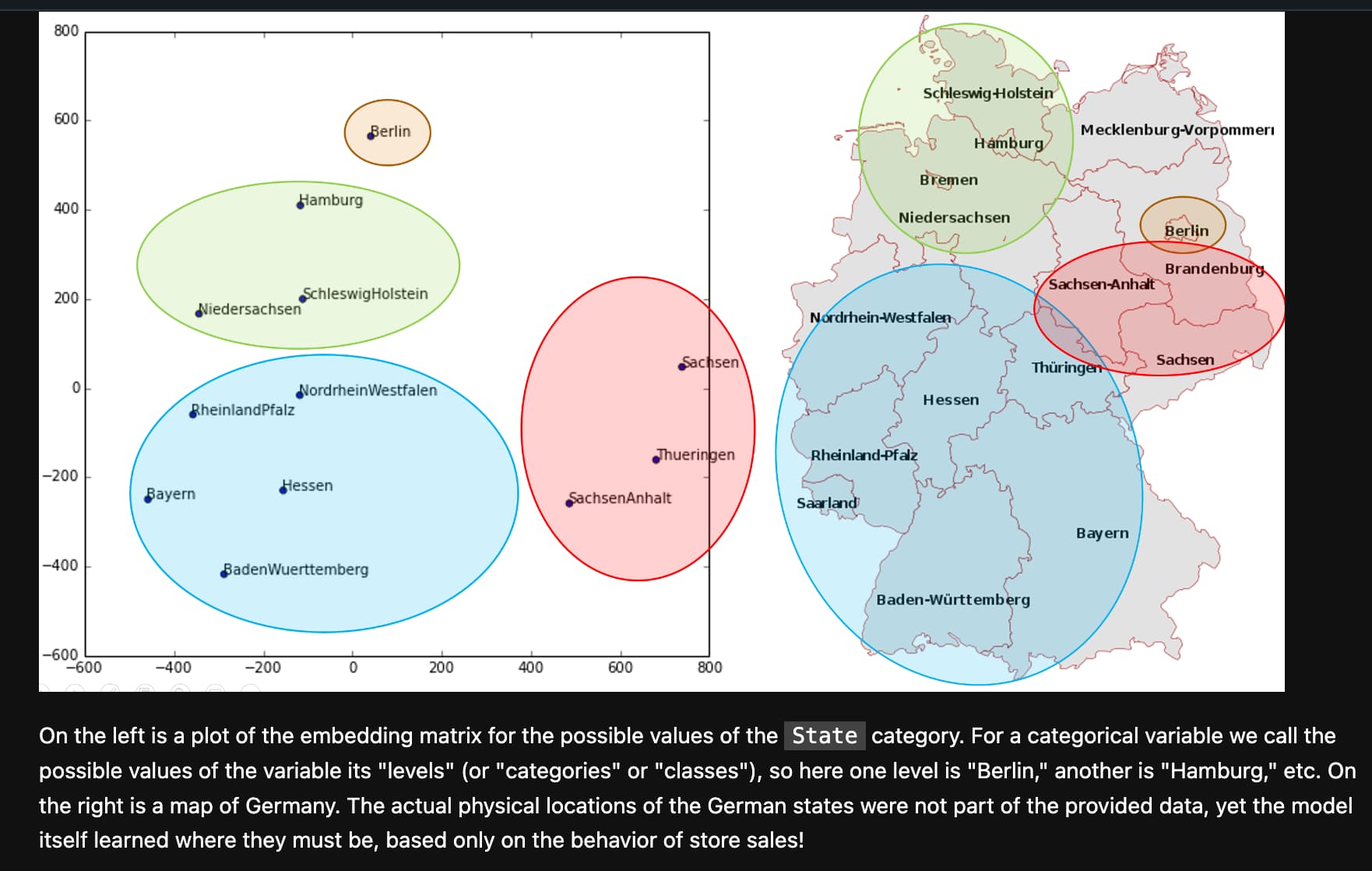
Perhaps one angle you could explore is if there is any similarity between the embeddings of different tabular models, and if that can lead to transferability between pretrained and new models. For example in chapter 9 they show how the embeddings from a tabular model trained on sales data also learned something about the geographic location of the stores:
Thank you for the idea and the sources, I’ll give them a look.
So do you think that the only way for me to try new models is to build them from scratch, like jeremy did in the second part of the course? (I’m referring to this and this in particular)
That is mostly beyond my current understanding unfortunately (I’m on Part 1 Lesson 7). When you say “new models” do you mean new architectures? Are you looking to build new architectures for tabular data?
I think yes: I saw that with vision_learner, when you create the actual learner you can pass a model (or architecture) in the function parameters and with TIMM library you can select even not pre trained models. I wanted some way to do kinda the same thing but with tabular data
Ah gotcha. Maybe someone else with more experience can chime in with more ideas. You may already have considered this I think the main challenge you will face is figuring out how to use the embeddings trained on one dataset for a brand new dataset (with different columns and values).
In TabularLearner it creates a TabularModel which takes as one of its inputs the embeddings. The embedding size is determined by get_emb_sz which is dependent on the specific categorical columns of the data as well as the number of classes in the dependent variable:
[_one_emb_sz(to.classes, n, sz_dict) for n in to.cat_names]
So to work around this, I wonder if there is a way to map or project one set of embeddings (made from one set of categorical variables and classes) to another----and I imagine it would not always makes sense. For example, a model predicting insurance prices may have categorical columns like income and gender, whereas a model classifying car types may have categorical columns like type of engine and material of construction. It wouldn’t make sense in this case to use one model for another. But I imagine there are other scenarios (like store sales and geography) that are transferable.
Those are some initial thoughts.