Hi everyone,
I am pretty new to the world of machine learning, I started fast.ai MOOCThis text will be hidden and for my “project” for lesson one I decided to differentiate lung problems from an X Ray. The dataset contains about 7000 images of normal lungs and bacterial or viral pneumonia infected ones, and the categories are: ‘normal’, ‘bacteria’, ‘virus’.
My biggest issue is the following:
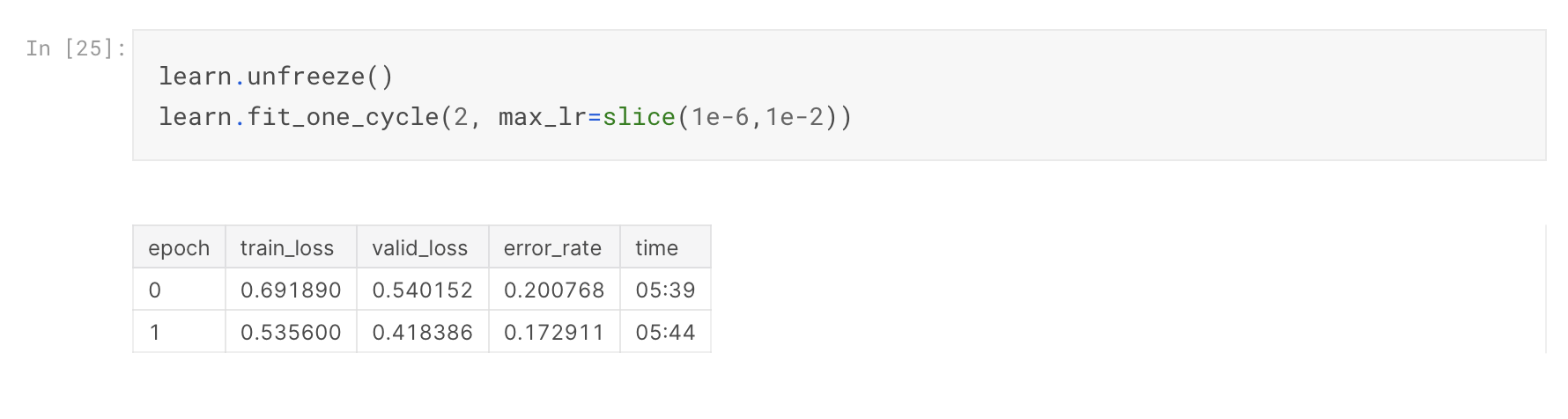
I see my train_loss and valid_loss are quite high but my error rate is around 17%, what does that mean? If I were to test the model out in the world would it behave according to the valid_loss or the error_rate? And what’s the difference between those two?
I tried searching the forums and google but couldn’t come to an answer, hence this post 
As a side note: The problem has been attempted before and a 90% accuracy was achieved (it isn’t an imposible problem to tackle)
Sorry if this isn’t in the right category, I’ll move it if it doesn’t belong here