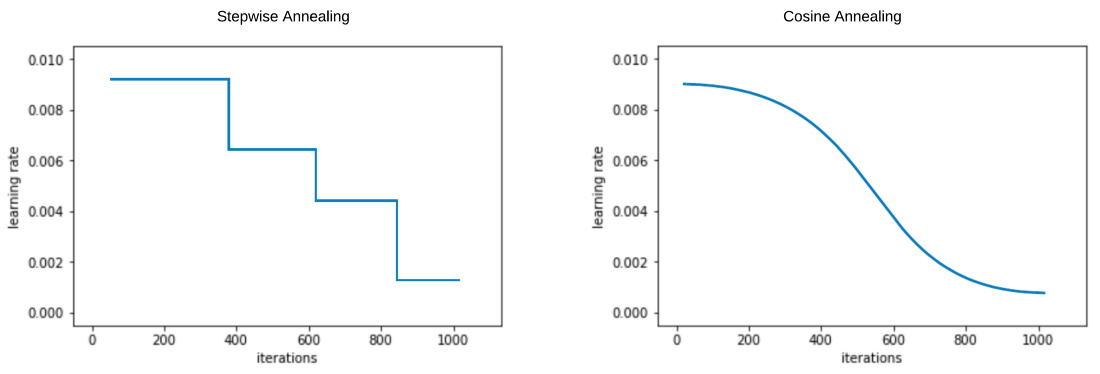
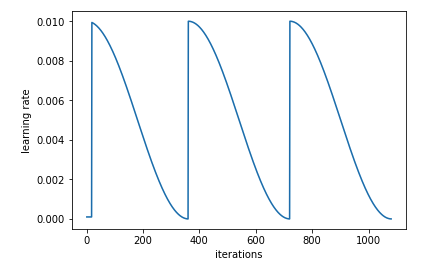
I am bit confused with both these approach as both seems to be aiming same problem. Cycling learning rate approach takes the initial learning rate and then increases/decreases within each epoch and then at last we plot the loss with epoch and learning rate. Learning rate annealing does same thing also and it reduces learning rate changes as we move towards minima value. Do we have any guidelines which one to following for optimal learning rate evaluation?
You can find these information in Lesson2 - part 1. It is summarized here lesson2_summary by Hiromi.
Learning rate (LR) annealing is you start learning at high LR and decrease it when you get closer to the local minimum. The reason is you don’t want to lose the location of the minimum by oscillate too much by using high LR.
Cyclic learning rate is after some time, you jump up your LR to get out of the actual local minimum position. The reason is there are several local minimums, some are “spiky” and it is not good for generalization. The final point should be in a “flat” area.
May I know why in lesson 2, we set learner.precompute to false only for the last layers.
Instead will it always be best to first unfreeze and then precompute all weights with augmentation for better results?