Not if you do git pull. I have experienced this problem several times.
I think the best solution is to assert for a specific fasprogress version in the fastai code (and not just package dependencies). That way regardless of how people get their fastai updates, they will know right away that they need a newer version of fastprogress.
It doesn’t look this is common in python to perform that at the code level. Or at least I couldn’t find almost any references on how to do it, or even people asking about how to do it.
fastai/environment.yml and environment-cpu.yml belong to the old fastai (0.7). conda env update is no longer the way to update your fastai-1.x environment. This is unfortunate, but we can’t remove these because the course-v2 video instructions rely on this setup. Eventually, once course-v3 p1 and p2 will be completed, they will probably be moved to where they belong - under old/.
instead do a normal install (even if you’re updating a previous install): conda install -c fastai fastai or pip install fastai and everything that needs to be updated will be updated.
It’s documented now here. Thank you for bringing up this issue, @ABertl.
Thanks for the help, I’ll try this out in the next few days.
To give some detail about what brought me to this point, I followed the recommendations of the MOOC and got a paperspace machine with fast.ai preinstalled, and have been git pulling since with monthly-ish conda env update. (I eventually ran into the problem with nbextensions but really didn’t want to give it up!)
Somewhere in the middle of working my way through the MOOC I realized the lessons were being done with an old version of fast.ai, and every time I was git pulling, none of the updates were hitting what I was using. Eventually I decided to try out 1.0.
I’m figuring it out, but it wasn’t real clear to me at first how to make the transition.
It can be very confusing indeed, especially given that fastai-0.7 files aren’t all in the same place, due to historic reasons I explained above. If you’re following the course-v2 MOOC you better stick to fastai-0.7, since the API has dramatically changed and it’ll be very difficult to make sense of the course-v2 videos using fastai-1.x. And if you do then, yes, you still need to use conda env update exactly as in the past. But you won’t need fastprogress then.
It wasn’t clear from your original post that you were referring to the fastai-0.7 version, but we do know that now. And if you do have installation issues with fastai-0.7 - please post those here.
I was curious to see if i could get to generate a train_ds w/ labels using the new API, but it appears to be very rough at the edges and failing in many ways if the prescribed way of train/valid split is not followed to the point, e.g.:
train_ds = ImageItemList.from_folder(path).random_split_by_pct(0)
...
IndexError: index 0 is out of bounds for axis 0 with size 0
and it also has an edge problem of generating 1 item in valid ds, which shouldn’t be there, since train ds, already has the full number of available items.
and this fails too:
train_ds = ImageItemList.from_folder(path)
train_ds
train_ds = train_ds.label_from_folder()
train_ds
...
TypeError: 'NoneType' object is not subscriptable
Is this a work-in-progress, or is the new API set to not allow any non-fastai-way of creating _ds objects (i.e. w/o valid set together with train_ds)?
I was experimenting with fashion mnist, but mnist will do too if you’d like to try it (i.e. path = /path/to/mnist)
I was planning to feed train_ds to ImageDataBunch.create(train_ds...) as in nbs/dl1/lesson7-wgan.ipynb, but the example there has no labels and w/o labels it works.
Thank you.
p.s. the 2 ways of using the test dataset w/ labels to validate against are now documented here.
On this, added a no_split method that will create a training set with everything and a validation set with nothing. Note that the empty validation set will still have a length of 1 otherwise the pytorch dataloader will complain (you have to test len(valid_ds.items) to check if it’s 0 or not.
Will change random_split_by_pct so that a 0 falls back to no_split, but this should be the method used.
Maybe-a-bit-breaking change: now that our transforms can pickle, DataBunch.export saves everything. That includes transforms and normalization, which means that you only have to type:
data = DataBunch.load_empty(path)
to get your empty data object ready for inference. Inference tutorial has been updated accordingly.
“Now that our data has been properly set up, we can train a model. Once the time comes to deploy it for inference, we’ll need to save the information this DataBunch contains (classes for instance), to do this, we call data.export() . This will create an export.pkl file that you’ll need to copy with your model file if you want to deploy it on another device.”
Probably the best to show that in code, like the rest. That is it is explaining the instruction, but the instruction is not there.
empty_data = ImageDataBunch.load_empty(mnist)
I find the naming unintutive, how can it be empty if you called load on it?
To try to clarify the error messages that are encountered in fit/lr_find/show_batch because of a problem in the data, I’ve added an automatic sanity check of DataBunch after initialization. It can be disabled with no_check=True and will throw a warning if there is a problem to
New: support for one-hot encoded labels in multi-classification. The most basic way is to use MultiCategoryList with one_hot=True but if you label from a dataframe with multiple columns, the data block API will guess it’s a multiclass problem and put that flag for you.
Hey all ! It may be a very basic issue but I’ve looked on the forum, didn’t find anything and I’m really stuck.
I’m trying to get to get the fastai dev environment working in order to start to contribute to fastai (beginning by the documentation Sylvain asked for) but I’m having trouble setting it up. I followed the tutorial of the documentation and I’m at step 4 “write the code” (so I forked the repo, cloned it on my local computer, did pip install -e . and then tools/run-after-git-clone).
However when I try to run the first import cell of any notebook I get the following error :
File “/Users/bocra/anaconda3/lib/python3.5/site-packages/fastai/init.py”, line 1, in
from .basic_train import *
File “/Users/bocra/anaconda3/lib/python3.5/site-packages/fastai/basic_train.py”, line 97
data:DataBunch
^
SyntaxError: invalid syntax
I think (but I’m not sure) it’s because fastai requires python >= 3.6 (pip install -e . told me so when I ran it). On the other hand, I installed fastai with the classic conda install and pytorch locked python at version 3.5 :
pytorch → python[version=‘>=3.5,<3.6.0a0’]
What am I missing ?
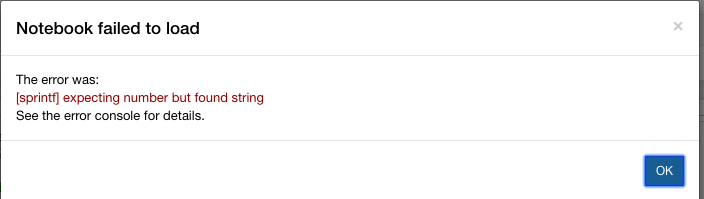
EDIT : And when I try to open an example notebook I get the following error :
Hi seeing that the error refers to the conda enviroment i think you forgot to uninstall fastai.
First, follow the instructions above for either PyPi or Conda . Then uninstall the fastai package using the same package manager you used to install it, i.e. pip uninstall fastai or conda uninstall fastai , and then, replace it with a pip editable install.
Oops that’s right, a bad case of RTFM I guess, sorry about that.
Though to be fair I was following the instructions here and I think there’s an omission as there should be the uninstall step. I guess that’s going to be my first PR
I’m doing fp16 training. After training completes I call
learn.show_results(figsize=(12,15), rows = 10)
and I got and error
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-21-cc1e87ad044f> in <module>()
----> 1 learn.show_results(figsize=(12,15), rows = 10)
~/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in show_results(self, ds_type, rows, **kwargs)
278 ds = self.dl(ds_type).dataset
279 self.callbacks.append(RecordOnCPU())
--> 280 preds = self.pred_batch(ds_type)
281 *self.callbacks,rec_cpu = self.callbacks
282 x,y = rec_cpu.input,rec_cpu.target
~/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in pred_batch(self, ds_type, batch)
236 cb_handler = CallbackHandler(self.callbacks)
237 cb_handler.on_batch_begin(xb,yb, train=False)
--> 238 preds = loss_batch(self.model.eval(), xb, yb, cb_handler=cb_handler)
239 return _loss_func2activ(self.loss_func)(preds[0])
240
~/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in loss_batch(model, xb, yb, loss_func, opt, cb_handler)
16 if not is_listy(xb): xb = [xb]
17 if not is_listy(yb): yb = [yb]
---> 18 out = model(*xb)
19 out = cb_handler.on_loss_begin(out)
20
RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.cuda.HalfTensor) should be the same
from my understanding class MixedPrecision(Callback) sets the transformation on the start of training and then removes the transformation at the training end
class MixedPrecision(Callback):
...
def on_train_begin(self, **kwargs:Any)->None:
"Ensure everything is in half precision mode."
self.learn.data.train_dl.add_tfm(to_half)
if hasattr(self.learn.data, 'valid_dl') and self.learn.data.valid_dl is not None:
self.learn.data.valid_dl.add_tfm(to_half)
if hasattr(self.learn.data, 'test_dl') and self.learn.data.test_dl is not None:
self.learn.data.test_dl.add_tfm(to_half)
def on_train_end(self, **kwargs:Any)->None:
"Remove half precision transforms added at `on_train_begin`."
self.learn.data.train_dl.remove_tfm(to_half)
if hasattr(self.learn.data, 'valid_dl') and self.learn.data.valid_dl is not None:
self.learn.data.valid_dl.remove_tfm(to_half)
So after the training there is no default transformation to fp16. I’d like to fix that if somebody will point towards where is the best place to put a fix.