Thanks for pointing this out. I was confused too because the very example below it was contradictory.
1 Like
And there is a new guide on the block: How to Make a Pull Request (PR) (specific to fastai needs).
Comments and improvement suggestions/PRs are welcome.
2 Likes
There was little feedback on my comment about bs presets: Developer chat, but the origin of the issue I raised wasn’t really about bs, it was beyond that - it’s related to any change in the user notebook, even if we magically figure out bs, so that users won’t need to change it, there will be other user changes that will have the same issue.
Therefore, I would like to generalize that same subject beyond the specifics of that comment. i.e. unrelated to setting bs.
There must be a good way for a user (me) to be able to git pull and not overwrite the local copy of the notebook, yet, being able to integrate the new changes. notebooks are very difficult to collaborate on even with our magical strip out filters, due to their json format. The two issues I encounter are:
-
git pullfailing because of the local changes.git stashwouldn’t work well, because there will be many conflicts ongit stash pop- guaranteed.I’m thinking perhaps to not ever change any course notebook under git and instead make a copy and change that. Now I can always
git pullwithout problems. -
how to actually merge the updated nb with my local changes. I guess nbmerge needs to be used to accomplish that in a less painful way, it can also be configured to be used on
git stash pop. So it could fix both issues at once.
Anybody has any other good strategies for having the cake and eating it too?
There is a new tool that helps you make PRs much easier to create. It will magically handle forking, syncing the forked master, and then making a branch. It will clone the repo or use an existing checkout.
See https://docs-dev.fast.ai/git.html#helper-program
Please give it a try and send me feedback if you encounter any problems or want more magic that I haven’t thought of yet:
curl -O https://raw.githubusercontent.com/fastai/fastai/master/tools/fastai-make-pr-branch
chmod a+x fastai-make-pr-branch
./fastai-make-pr-branch https your-github-username fastai new-feature
Most of you, developers, will probably want ssh instead of https:
./fastai-make-pr-branch ssh your-github-username fastai new-feature
It’s in the fastai repo’s tools/ dir, so you can just git pull and run it directly via tools/fastai-make-pr-branch instead.
run it w/o arguments for help:
./fastai-make-pr-branch
This program will checkout a forked version of the original repository, sync it with the original, create a new branch and set it up for a PR.
usage:
fastai-make-pr-branch auth user_name repo_name new_branch_name
parameters:
auth: ssh or https (use ssh if your github account is setup to use ssh)
user: your github username
repo: repository name to fork/use
branch: name of the branch to create
example:
fastai-make-pr-branch ssh myusername fastai new-feature-branch
notes:
- if the original repository has been already forked, it'll be done by the program (it will ask you for your github password)
- if the program is run from a directory that already contains a checked out git repository that matches the parameters, it will re-use it instead of making a new checkout.
- if the requested branch already exists it'll reuse it
- if the master is out of sync with the original master it'll sync it first
1 Like
Thanks. got it
Blockquote
class WrnLearner(Learner):
def init(self, data:DataBunch, arch:Callable, **kwargs:Any)->None:
torch.backends.cudnn.benchmark = True
model = arch()
super().init(data, model, **kwargs)
apply_init(model, nn.init.kaiming_normal_)
learn = WrnLearner(data, wrn_22, metrics=error_rate)
@Taka it’s implemented in the current release!
1 Like
Nice, did you send in a PR?
No, it was done by Jeremy
@sgugger I encouter a ZeroDivisionError: division by zero when I use the one_cycle with the conda 1.0.14 fastai.
Basically I have a big imageset,so I copy 100 images to a sample folder, you can see the file structure in the notebook. I keep getting this Zero divide error and struggle to resolve it. It’s surprise me when I do learn.fit() it runs smoothly without error.
=== Software ===
python version : 3.7.0
fastai version : 1.0.14
torch version : 1.0.0.dev20181022
nvidia driver : 396.44
torch cuda ver : 9.2.148
torch cuda is : available
torch cudnn ver : 7104
torch cudnn is : enabled
=== Hardware ===
nvidia gpus : 1
torch available : 1
- gpu0 : 11441MB | Tesla K80
=== Environment ===
platform : Linux-4.9.0-8-amd64-x86_64-with-debian-9.5
distro : #1 SMP Debian 4.9.110-3+deb9u6 (2018-10-08)
conda env : fastai
python : /home/mediumnok/.conda/envs/fastai/bin/python
sys.path :
/home/mediumnok/log/nbs
/home/mediumnok/.conda/envs/fastai/lib/python37.zip
/home/mediumnok/.conda/envs/fastai/lib/python3.7
/home/mediumnok/.conda/envs/fastai/lib/python3.7/lib-dynload
/home/mediumnok/.conda/envs/fastai/lib/python3.7/site-packages
/home/mediumnok/.conda/envs/fastai/lib/python3.7/site-packages/IPython/extensions
/home/mediumnok/.ipythonI’m thinking there is not enough iterations: is your dataset small? Maybe try more than 1 epoch.
Thanks for your always quick response. I guess you mean more than 1 batch here.
I slowly reduce the batch size until there are at least 4 batches in an epoch, the problem disappears. Last time I got this ZeroDivsionError due to the RandomLight transformation, I thought I was going back into this issue until I realize it was something else.
Maybe I could do a small PR to throw an error to prevent user doing it on a small dataset instead of throwing ZeroDivisionError?
Thanks!
You can find my attempt to reproduce this error for the examples/vision.ipynb, you can put this notebook in the examples/ directory and run it and reproduce the error. It create a subfolder “sample” in the original directory and copy 50 images in each class.
/home/mediumnok/.fastai/data/mnist_sample
├── models
├── sample
│ ├── models
│ ├── train
│ │ ├── 3
│ │ └── 7
│ └── valid
│ ├── 3
│ └── 7
├── train
│ ├── 3
│ └── 7
└── valid
├── 3
└── 7
Already fixed in master 
that was quick…
The model_sizes() function in hooks.py has error as below when I run model_sizes(learn.model)
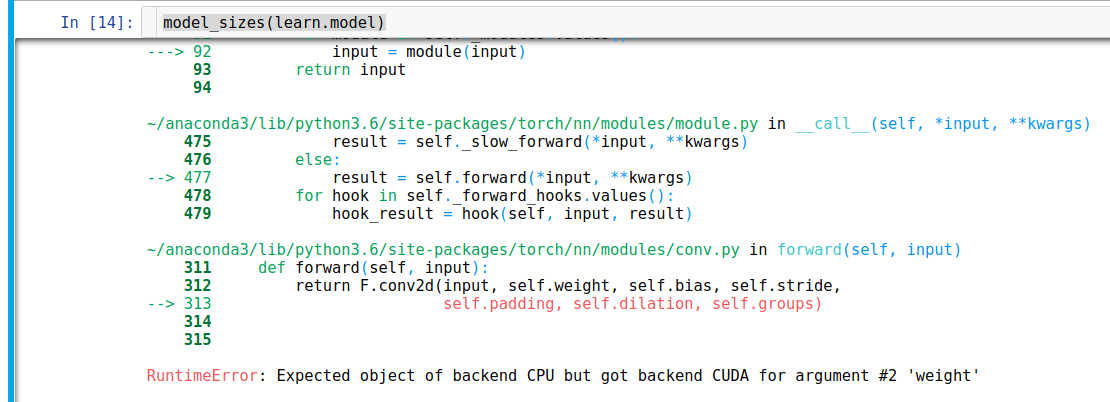
I found that it is because, as default, x = torch.zeros(1,ch_in,*size) saves x in cpu rather than cuda. So change this line to x = torch.zeros(1,ch_in,*size).cuda() will fix the problem.
I don’t know if just my case, that create a tensor will save in cpu as default. I remember didn’t config it 
p/s: Is it ok if I do a PR and also post it in the forum ? I think in the forum more people will see the post and do a PR in the case the admin miss this post
There’s no problem with doing a PR to try and fix things. In this case, your solution only works when the model is on the GPU, whereas it could be in the CPU (in which case old version works ). The good answer is to put x to the same device as the model.
1 Like
Merged a big change: Learner objects now determine from the loss function if there is something to add on top of the models to get the true predictions. As a result:
-
get_predsnow return the true probabilities -
TTAaverages the probabilities and not the last activations of the model -
ClassificationInterpretationhas been changed accordingly and thesigmoidargument has been deprecated
2 Likes
fastai.__version__ is still 1.0.15 as before… Is there an automated way to update the version number?
@stas This (maybe?) be an example of the use of date in .__version__ as is in torch.
When I try to define a ConvLearner after the most recent git pull I get the following error:
NameError: name 'ConvLearner' is not defined
Switching to the normal Learner class result in this error:
AttributeError: 'function' object has no attribute 'to'
Did something change under hood?
EDIT: Yes, something changed: http://docs.fast.ai/vision.learner.html
(I will write 100x: Better always check docs.fast.ai before asking a question. )
I don’t see any helper function for saving an Image class to a file. Maybe this could be useful for fastai/vision/image.py? I haven’t quite figure out the import yet. When I do from fastai.vision import *, I could do open_image() directly but for this new function I added I can only do image.save_image()
.
def save_image(fn:PathOrStr, img:Image):
x = image2np(img.data*255).astype(np.uint8)
PIL.Image.fromarray(x).save(fn)
p.s. Just notice that I need to add save_image to the all list, quite magical to me.
That only updates when there’s a release. If you want to use the bleeding edge version, use the ‘developer install’ approach in the readme.