A product of hard work of @ashaw, @Benudek and yours humbly is now ready for your enjoyment (project thread).
-
Each API that’s tested in the fastai test suite now has a test entry in the documentation (about 200+ of those):
e.g. go here https://docs.fast.ai/basic_train.html#Learner.save and click on
[test], and you will get:

So in addition to tutorials and code snippets in the docs, you can now also look at how the API is tested, including expected results and expected failures.
-
Each API that isn’t yet tested invites you to do so:
e.g. go here https://docs.fast.ai/basic_train.html#Recorder.plot_metrics and click on
[test], and you will get:

- And similar to
show_docyou can also doshow_testfrom your notebook once you install the new fastai 1.0.47 when it’s released, or using git master now:
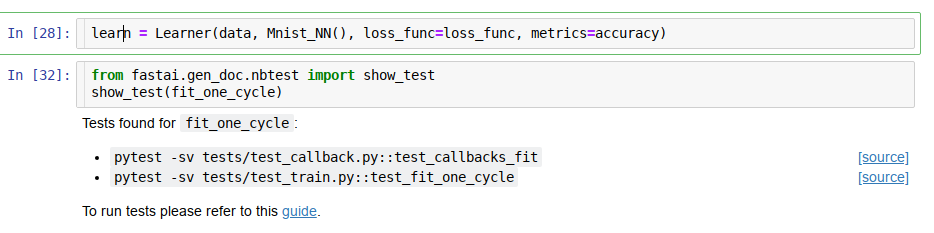
Same as show_doc arguments, except it’s show_test.
What makes it all possible is a special this_tests call in every test. https://docs.fast.ai/dev/test.html#test-registry
Bottom line, if you click on [test] or you run show_test and you get ‘No tests found’ - please contribute some!