Needing help with a search algorithm to find the shortest sequence of items that lead to a certain outcome (failed test in this case). Please see this post.
Also there was a bit of a mess up with 1.0.44 vs 1.0.45, which are really the same release. So I removed 1.0.45 from pypi/conda and there is 1.0.44 instead for those who want it. But, of course, 1.0.46 is out.
Looks like the keyboard shortcut to bring up the list of Discourse shortcuts has been changed to shift-/ instead of just /, at least on Chrome on Linux. If this is universal, could you please edit your initial post to reflect this? Thanks!
The API of the Callback has been slightly changed to be more flexible and (hopefully) less opaque. You now can return a dictionary that will update the state of the CallbackHandler so
instead of returning last_loss in on_backward_begin, you can return {"last_loss": my_value} in any event of any callback
you can change inner stats (for instance the number of the epoch displayed when resuming training)
in a custom metric written as a callback, instead of having to give last_metric=my_value in on_epoch_end, the new way of doing it is:
The CallbackHandler will throw an error in case of typo (so you can’t add attributes).
The old return True in some events to stop training or skip the step are now replaced by the following flags in the state:
skip_step: to skip the next optimizer step
skip_zero: to skip the next grad zeroing
stop_epoch: to stop the current epoch
stop_training: to stop the training at the end of the current epoch
For instance, in the old LR Finder Callback the part to stop after going too high in loss was:
def on_batch_end(self, iteration:int, smooth_loss:TensorOrNumber, **kwargs:Any)->None:
"Determine if loss has runaway and we should stop."
if iteration==0 or smooth_loss < self.best_loss: self.best_loss = smooth_loss
self.opt.lr = self.sched.step()
if self.sched.is_done or (self.stop_div and (smooth_loss > 4*self.best_loss or torch.isnan(smooth_loss))):
#We use the smoothed loss to decide on the stopping since it's less shaky.
self.stop=True
return True
def on_epoch_end(self, **kwargs:Any)->None:
"Tell Learner if we need to stop."
return self.stop
and the new one is
def on_batch_end(self, iteration:int, smooth_loss:TensorOrNumber, **kwargs:Any)->None:
"Determine if loss has runaway and we should stop."
if iteration==0 or smooth_loss < self.best_loss: self.best_loss = smooth_loss
self.opt.lr = self.sched.step()
if self.sched.is_done or (self.stop_div and (smooth_loss > 4*self.best_loss or torch.isnan(smooth_loss))):
#We use the smoothed loss to decide on the stopping since it's less shaky.
return {'stop_epoch': True, 'stop_training': True}
Under development but should work as long as you are on master for fastai and fastprogress, resume training from where it was automatically.
If AWS shuts down your spot instance, the marvelous fastec2 will wait for them to be available again and it would be nice to restart training from when you last where (at least the last completed epoch). This is now possible with two callbacks! Just pass:
in you call to fit, fit_one_cycle or with a custom scheduler and it should work. Interrupted trainings will start back from the last completed epoch!
Note that to force the training to go back from start, you need to remove the epoch file that will pops out in your model_dir because that’s where we keep track of the progress made.
Breaking change (this is all @radek fault, so don’t be mad at me ^^)
create_cnn won’t exist anymore in v1.0.47 and later on, it will be replaced by cnn_learner for consistency with all the other convenience functions that return a Learner. Updating the docs, will do the course and the deployment kits once the release is out.
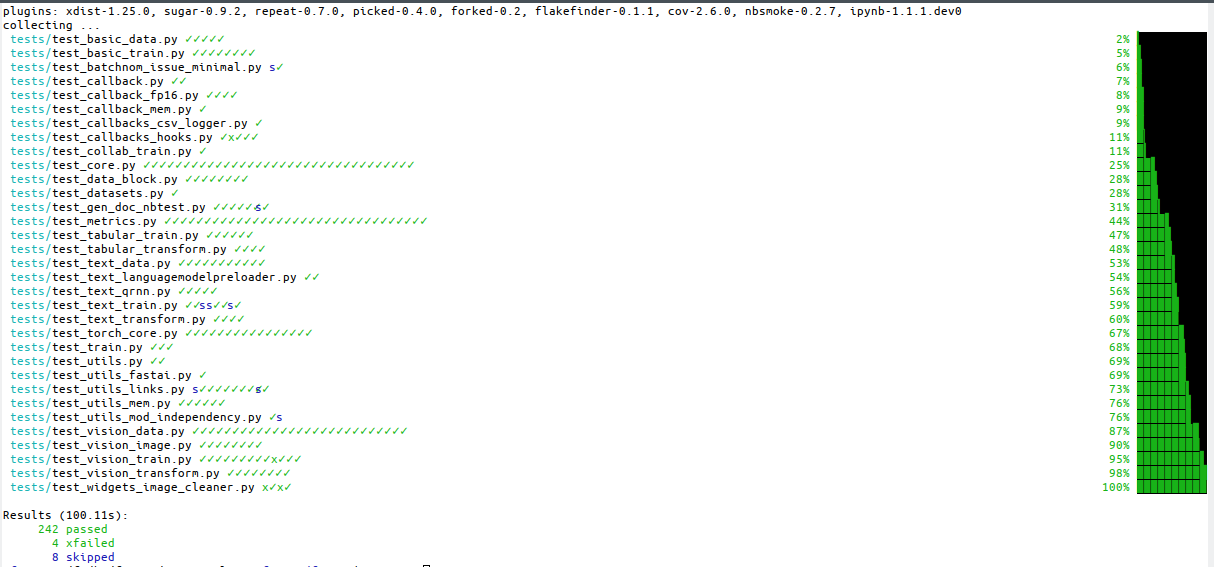
So in addition to tutorials and code snippets in the docs, you can now also look at how the API is tested, including expected results and expected failures.
Each API that isn’t yet tested invites you to do so:
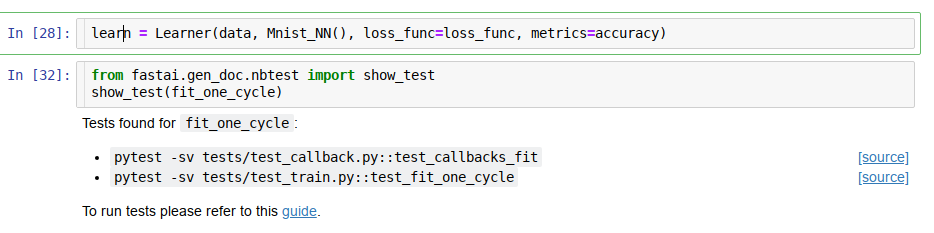
And similar to show_doc you can also do show_test from your notebook once you install the new fastai 1.0.47 when it’s released, or using git master now:
I hope this is the right place to post. I have a suggestion for improving the ClassificationInterpretation class. Right now there is a very useful feature, most_confused, that shows you the classes that your model is predicting incorrectly. There is also plot_top_losses, also very useful, to visualize the cases the model had the highest loss on. However, if you discover the model is mixing up two classes that it shouldn’t be, I don’t believe there is any way to visualize the data for just those classes.
For example if we have a fruit classifier, maybe most_confused shows something like this…
These are all reasonable except for watermelon/apple which should be very easy to distinguish so I’d think of this as a good place to take a closer look, but I don’t think there’s a way to do it easily.
Would this be useful enough to consider as a feature, or would it add bloat? Would it be best to add it’s own function? Or would it be better to add two additional parameters to plot_top_losses (pred_class=None, actual_class=None) to act as a filter. I’d be happy to do it and submit a PR if people would find it useful, but I’ve never submitted a PR so would probably need guidance on the implementation.
I would like to propose a context manager for progress_disabled(). When doing a quick search for batch size or image size it would help to not have a bunch of red-bars coming up.
class progress_diabled():
''' Context manager to disable the progress update bar and Recorder print'''
def __init__(self,learner:Learner):
self.learn = learner
self.orig_callback_fns = copy(learner.callback_fns)
def __enter__(self):
#silence progress bar
fastprogress.fastprogress.NO_BAR = True
fastai.basic_train.master_bar, fastai.basic_train.progress_bar = fastprogress.force_console_behavior()
self.learn.callback_fns[0] = partial(Recorder,add_time=True,silent=True) #silence recorder
return self.learn
def __exit__(self,type,value,traceback):
fastai.basic_train.master_bar, fastai.basic_train.progress_bar = master_bar,progress_bar
self.learn.callback_fns = self.orig_callback_fns
Used like this:
with progress_diabled(learn) as tmp_learn:
tmp_learn.fit(1)
Code is pretty simple (below) and happy to make a PR with this included. One change I would need is around Recorder. I wanted to ask if there is a reason that self.silent is not exposed in the __init__ for Recorder? See here.
Another question is where to put it into the library. Inside basic_train.py does not quite seem right, so open to suggestions.