I’m having difficulty understanding what to take away from these results. I did a search for learning rate using different weight decays to determine what lr and what wd to use. I then train for n epochs.
With more epochs accuracy and validation error continue to improve… BUT training loss gets much smaller. This must be overfitting right?, but validation is still improving… What should I take away from this and how should I decide on number of epochs?
Thanks for any help!
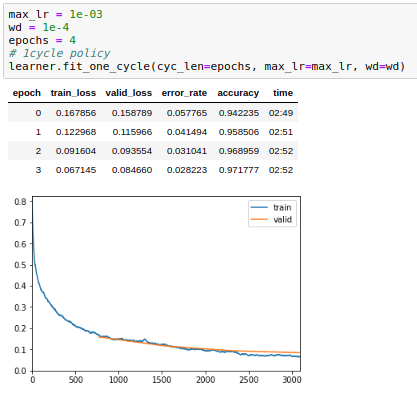
With 4 epochs i get:
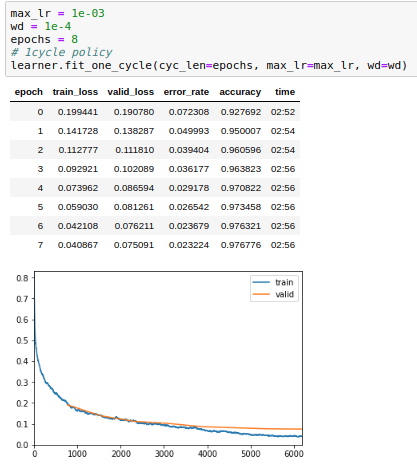
If I recreate the learner again and run for 8 epochs:
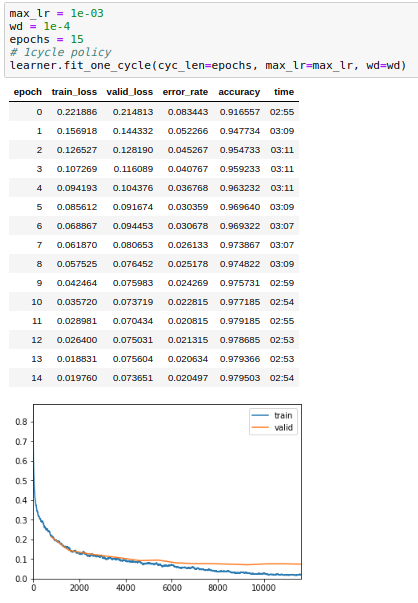
With 15 epochs:
We can see that training one cycle with a larger number of epochs produces better validation loss and accuracy but that training loss is diminishing toward zero. Validation loss is not trending up but training loss is clearly trending down
In my opinion, it doesn’t matter if the training loss is 0.00000 as long as your validation loss / metric is improving. I’d take 0.02/0.07 over 0.07/0.08 any day of the week.
It’s good! Take a look at @balnazzar post on overfitting and Jeremy’s top quote of course one
So the only thing that tells you that you’re overfitting is that the error rate improves for a while and then starts getting worse again. You will see a lot of people, even people that claim to understand machine learning, tell you that if your training loss is lower than your validation loss, then you are overfitting. As you will learn today in more detail and during the rest of course, that is absolutely not true .
Thanks all, particularly that I should not worry about training loss trending even to zero. So I will just focus on validation loss and train for as many epochs as I have time for.
So this begs another question. I train or fine-tune a model with different hyperparameters. Both lead to good and similar accuracy measures but one has much higher validation loss. I’m assuming that the one with the lower validation loss is better, but in what way? Should it be able to generalize better? Both models are just as good at classifying the validation set, just with different losses.
Also how to compare one model say built with resnet34 vs another resnet50. If the accuracies are about the same can we compare the models based on validation loss?
Ultimately, you measure success by whatever metric is appropriate to your need and seek the best measure against that metric. Doesn’t matter what validation loss is in that case. Having said that, its sometimes difficult to know if the lower val-loss or better-metric for a training set is a better indicator of real world performance. You can always try each of them to find out!
So I am still unsure how to interpret error rate (accuracy) vs. validation loss.
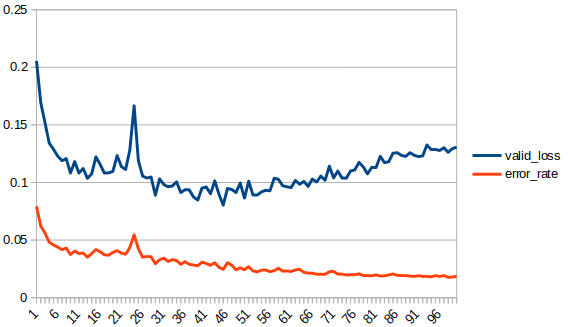
Here, over 100 epochs, error rate is continuing to decrease but validation loss returns to increasing. At lowest validation loss, around epoch 47 the error rate is .0242, by epoch 100 the error rate has steadily fallen to .0186 but validation error has clearly increased. The validation set is 44,000 images (80% of the data), by epoch 47 there are 1064 misclassifications and by epoch 100 only about 800.
Again this is using fit_one_cycle so I don’t really control when to stop, just the number of epochs. What is more relevant here, the validation loss or the accuracy(error rate)? i.e. should I be striving for the low point on the validation loss curve or is the better accuracy more relevant? If the validation loss is the more important metric what does it mean that accuracy is steadily improving and why should I ignore that in favor of validation loss?
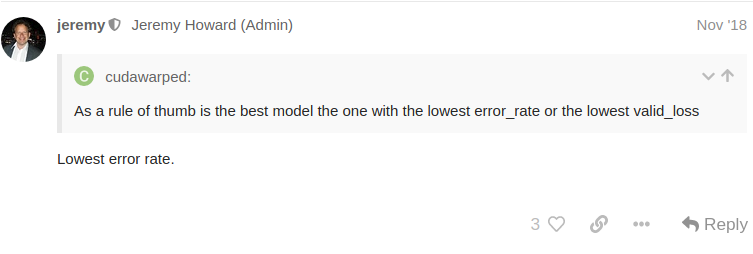
Since Jeremy’s comment favors error_rate over validation loss this implies my best model is around epoch 100. This flips the question around:
If error_rate is the more important metric what does it mean that validation loss is getting worse and why should I ignore that in favor of error rate?
@MarkD You’ve asked a really great question - something that I’m also not sure about as well. Did you ever get further clarification on this?
From visual observation of your error rate, it appears to be reaching an asymptote and isn’t improving very much. To me that indicates that additional training offers diminishing improvements in terms of error rate and thus you pay more CPU/GPU time for each incremental error rate improvement.
My take on Jeremy’s answer is that it is better to sacrifice confidence for prediction accuracy. Your validation loss might be increasing because your model is less confident in each prediction, but makes more correct predictions overall.
I can help clarify this… Great questions and a clear understanding of this is very fundamental.
Two points we can address from above questions, 1. validation loss vs error rate, 2. number of epochs to run.
You are absolutely right, usually the error rate would improve with a decreasing validation loss. However, it is possible that the validation loss would start to increase while the error rate is still decreasing! Here, let’s remember that the primary thing we care most about is our performance metric, which is our error rate. So as long as that’s getting better, we re on the right path. Nonetheless, training loss and validation loss can give us hints if our model is overfitting. How do we explain such behavior? I’d say when both (loss and performance metric) are improving, the model is getting more confident and accurate about the results. At some point, the model can become over-confident and that’s when the loss can increase even if the performance metric seem to get better because a false prediction would result in a much higher loss increase than the slight drop in our accuracy or error rate. That being said, there comes a time when the performance metric starts to fatten out and that’s where we want to stop. Some sometimes may use early stopping, others rather use regularization… whatever floats your boat. I think both are fine, i’d still prefer regularization.
so how many epochs to run? It’s important to relate that to the size of dataset you are working with. If it’s a large dataset, running a single epoch may even be too much, then the question becomes how many batches to run! I am assuming we are talking about smaller datasets. In that case, you can run as many epochs to get the best performance metric result, it will eventually flattens out or starts to make slight incremental improvements. For instance, in the plot @MarkD showed above, 50 epochs would be ideal. But is it really worth running all those epochs for a slight increase in error rate from 10 epochs to 50 epochs?! Personally, I’ll choose to go with 10 epochs.