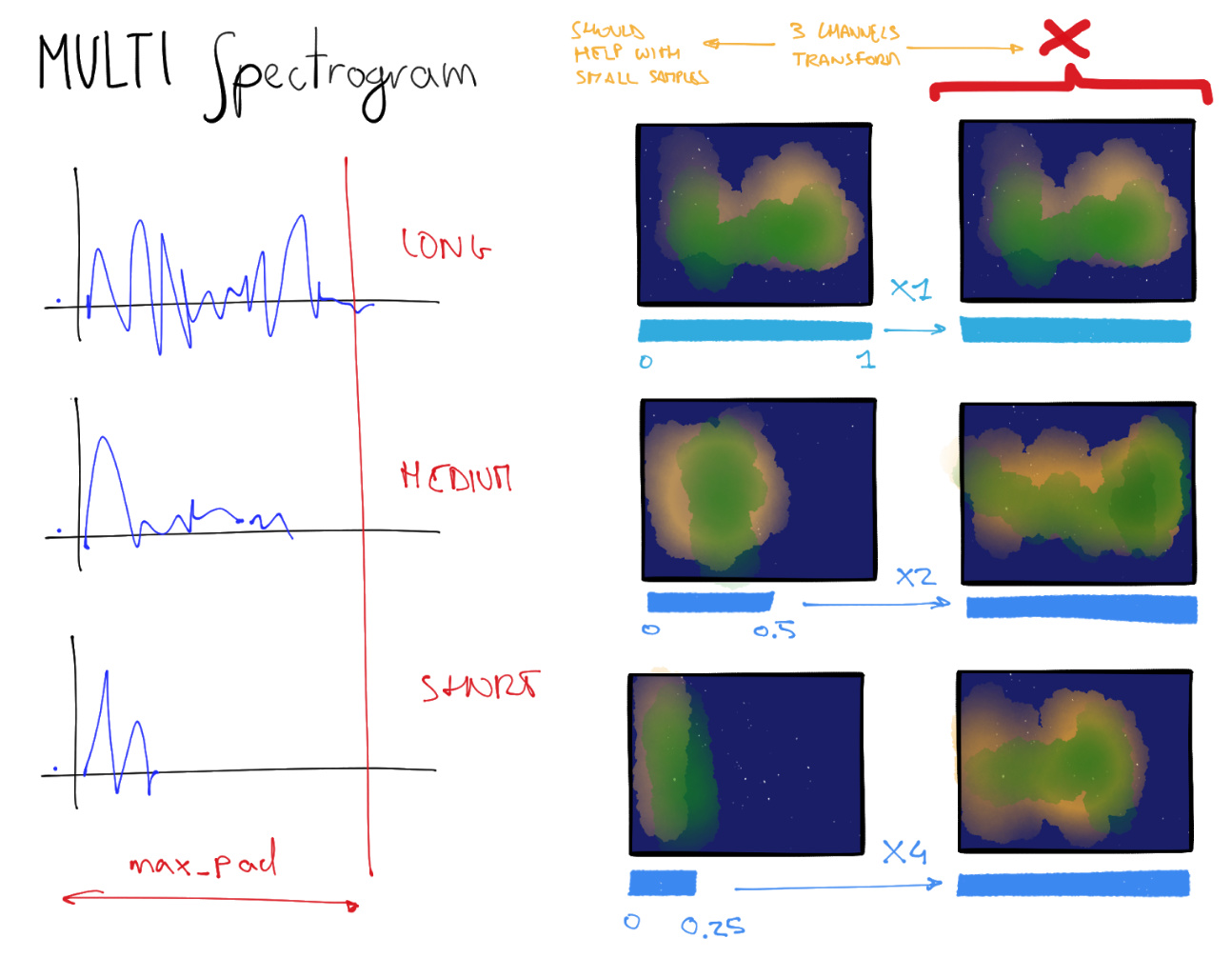
Maybe! Pretty much everything is in the “try it and see” bucket at the moment. @ste has been experimenting with “multi-spectrograms”, basically creating 2 or 3 spectrograms at progressively higher resolution before cat’ing them together to form the final “image” presented to the resnet (see here for his notebook). This would be a similar idea, I think. Try it out and let us know what you find!
1 Like
With the risk of irony in creating noise, might be looking into noise suppression in audio e.g.
https://devblogs.nvidia.com/nvidia-real-time-noise-suppression-deep-learning/ (which references http://staff.ustc.edu.cn/~jundu/The%20team/yongxu/demo/pdfs/YongXU_Taslp_2015.pdf)
Potentially interesting to explore for example whether an approach where training takes place on noisy images only (https://arxiv.org/abs/1803.04189), can be experimented with using a dataset such as https://voice.mozilla.org/en/datasets. Feel free to point out any fundamental flaws.
1 Like
TfmsManager: visually tune your transforms
I’ve published a tool to quick visualize and tune a complex chain of data transforms (Audio & Image).
https://forums.fast.ai/t/tfmsmanager-tune-your-transforms/43741

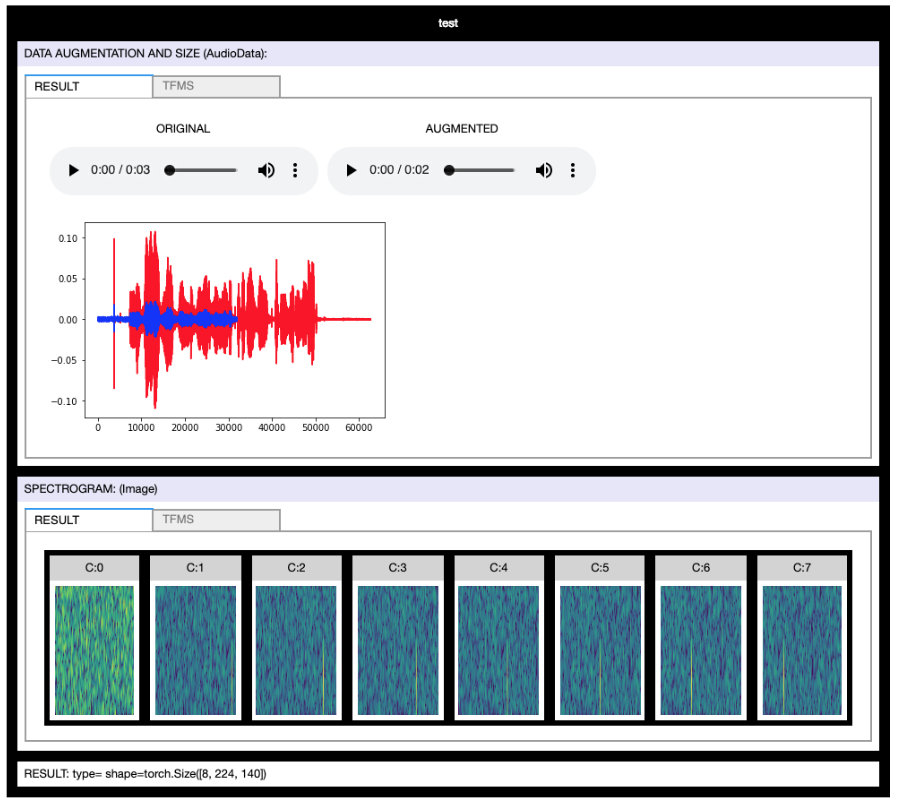

@zanza21 Here you can find two complete examples of using muti spectrogram
- Incremental zooming the image: https://github.com/zcaceres/fastai-audio/blob/master/example_multi_spectrogram_classificaiton_phoneme_multi_resolution.ipynb
- With a “3 sliding window” where each slide is a channel: https://github.com/zcaceres/fastai-audio/blob/master/example_multi_spectrogram_classificaiton_phoneme-sliding.ipynb
NB: this is the idea behind the “Incremental zooming”:
9 Likes
@zachcaceres Need to look at the loss function. We are using CrossEntropyLoss to predict the next audio, but CrossEntrpyLoss is only for predicting classes(pick 1), not for generating the next.
Also found something even more interesting. If you run:
ys=learn.data.train_ds.y
ys.items.sum()
All of the targets seem to be 0, (and is only a 16-length tensor)
1 Like
Culprit for what the targets are all zero is here:
class AudioSequenceDataBunch(DataBunch):
@classmethod
def from_df(cls,
path:PathOrStr,
train_df:DataFrame,
valid_df:DataFrame,
audio_cols=[],
**kwargs) -> DataBunch:
src = ItemLists(path, AudioSequenceList.from_df(train_df, path), AudioSequenceList.from_df(valid_df, path))
# TODO: toggle classifier or LM here (toggle labels)
labeled = src.label_const(0)
Here we are just setting all the labels to 0 for testing purposes. We never completed the code to generate labels/targets. Tried to do something about it myself, but am stumbling around a bit with trying to understand how everything is setup so far.
Transfer learning is at the core of fast ai so I was wondering are there any plans to add a model specifically trained on the task of audio classification.
Google have created an amazing dataset with a variety of sounds (including silence and ambience) called the AudioSet. They have also provided some models which we could export and torchify?
Here is their paper on the experiments they conducted on AudioSet. They have used the spectogram approach and experiment using the ResNet50, InceptionV3, Full Connected, AlexNet, VGG architectures.
1 Like
@MadeUpMasters Maybe link this video at the top of the thread it gave incredible insight into Fourier Transformations
4 Likes
It would be interesting to do this at the audio level too (i.e. downsample to 8KHz first).
- Resample to arb bitrate: “AudioResampler”
This is a great idea! I’ve done some experiments on re sampling down to 8Khz and the results are awful as you bring the sample rate down to 8KHz. I’ve created a transformation to do the re-sampling however it really eats into training time significantly and would probably be best done as a pre-process as you have suggested.
When re-sampling the reduction in accuracy is huge. Have a look here at the results when trying to classify the English Speaker dataset.
I’ve shown a few epochs at various re sampling rates. Here is a summary:
|Resampling|Accuracy|Train_loss|Valid_loss|2 Epochs|
|—|—|—|—|—|—|
|None|0.783854| 0.853869|0.657515|00:23
|15500|0.769531|0.860154| 0.632849|00:40
|10000|0.261719|0.840956|3.497732|00:32
|8000|0.122396 | 0.806397| 6.229582 |00:30
I’m suspicious I’ve done something wrong here. Perhaps the parameters for spectogram generation need to be adjusted?
1 Like
I had some bad results with spectrograms with 44.1KHz samples last week; visually it looked like the conversion process wasn’t using the full potential range of the spectrogram, ie using 128 mels, only ~80 of them were ever used. My “solution” was to resample to 16KHz (in a different pipeline/notebook), but that’s not really a good solution; maybe we (or librosa) are doing something wrong in the code, or maybe there’s a reason melspectrograms are expected to work differently at different rates. Needs more digging.
As for preprocessing, @marii has been working on a scipy/PyTorch-level resampler which is much faster than the librosa method, which looks promising.
1 Like
I’ve got even better results after adding a tranformation to shift the audio to the left or right.
I’ve made a PR and here is the notebook to see full results.
99.5%
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 8 | 0.053877 | 0.029832 | 0.983073 | 00:23 |
| 9 | 0.037804 | 0.020874 | 0.994792 | 00:23 |
5 Likes
Results from that audio shift transform look great @baz! I haven’t checked your PR yet but I’ll get to it soon. In your notebook, it looks like you’re not setting to_db=True in your transforms; is that intentional? We usually get better looking (literally!) spectros with that flag, but I’m not convinced that means they’ll train any better. Might be worth a try to see if you can get >99.5!
While we’re spitballing, there are 2 other obvious areas where we can probably improve our baseline:
- We’re not doing any normalisation. This probably means we’re not making it as easy as possible for our model to train well. Should be very easy to do - will be interesting to see how much difference it makes. I presume it should be done on the spectros if the intent is to get the values between
0,1. - We’re probably not specifying our validation set properly. We have a pretty small dataset and only 10 classes, so maybe just splitting randomly by 20% isn’t ideal; I’d be happier if we used a function to split the data so we had ~20% of each class in the validation set. This might turn out to be wasted effort but, it feels more hygienic.
I’ll try both of these today, hopefully. But if I haven’t got to it and someone else wants to experiment + PR, please do!
I have found with the large amount of data that shows up in a single cell loading times on notebooks have crawled to a halt. If you are on linux you can strip out notebook cells using:
pip install nbstripout;
find . -regex ‘.*ipynb’ | xargs -I {} nbstripout {}
@zachcaceres https://github.com/marii-moe/petfinder/blob/master/petfinder-fastai.ipynb
petfinder github with how i loaded data into a databunch
1 Like
I’ve been working on audio classification, leveraging the excellent work from @zachcaceres
From this base, I have added the following:
- Management of stereo files. It can be either converted to mono or one spectogram is created by channel and then both channels are fed into CNN. The latter seems to increase the accuracy of models.
- Adapting Fastai method “show batch” to show the original sound, the processed sound, all spectograms. This is useful to see the impact of data augmentation methods (especially for noise addition).
- Creation of a new method plot_audio_top_losses, inspired by plot_top_losses, to give an interpretation on the focus of the model during predictions
Finally, I’ve also compare the performances in different dataset (AudioMNIST, SLR45, UrbanSound8k).
On UrbanSound8k, the performance is really close to the benchmark published last year in the KDD conference last year (96.8% without cross-validation vs 97.5% with cross-validation)
I hope this would be useful.
You can check out this work in this link https://github.com/cccwam/fastai_audio
6 Likes
It would be great if we can add cutout/occlusion type of augmentation, it could be super useful for things like auditory scene analysis or classification of multiple categories of sound present in a sound file, etc.
@kodzaks Any chance you know http://www.ece.neu.edu/fac-ece/purnima/ ? I know her group has done some fun work around counting whales using deep learning.
2 Likes
Great! We’re creating a new folder with the conversion of all’ main notebooks to Part 2/2019 - we’ll release it soon 
1 Like
BTW: try to run AudioTransformManager notebook in fast-ai audio root.
https://forums.fast.ai/t/tfmsmanager-tune-your-transforms/43741/4
1 Like
hey. Is the group still a thing? How can I participate. Thanks in advance
1 Like
Hey Andrei, the telegram group is still a thing but it’s not super active as we are defaulting to posting most things here to keep solutions searchable for all. You’re welcome to join us, there’s still some chat and people to ask questions/share with when you don’t want to clog the thread. You can also just post here, as there are lots of active contributors. If you want to join the telegram group just send me a PM here and I’ll add you. Cheers.
1 Like