Hi @anamariapopescug
Thanks for replying! I have the entire Reddit submissions data set from 2006 until August 2015, which I have imported into a SQL database so that its easier to manage getting data from. I have then extracted data that mentions vaccinations by using a wild card search - and of course this data is not at all clean.
Additionally I have twitter converstations around the same subject.
I don’t want to manually clean it if I can avoid it, I would rather do that programmatically, but before embarking on any processing I thought I would ask if there was anything built in to the fast.ai library that allows us to deal with words that are obvioulsy a URL, hashtag, or twitter id.
Any help with cleaning is very welcome, but at this stage I want to know if I even need to worry about doing that - perhaps there is a fast.ai inbuilt mechansim, or flag to tell it to ignore these, or perhaps the nature of the algorithms mean that I need not worry aobut these?
If not in fast.ai, and I need to clean them out, then maybe there is something available in Python or even in Linux that allows me to put these words aside. Ideally I would want to submit my text to a mechanism that strips these out, maybe replacing them with UNK, and that does a word count per submission after that to determine if there is anything useful left 
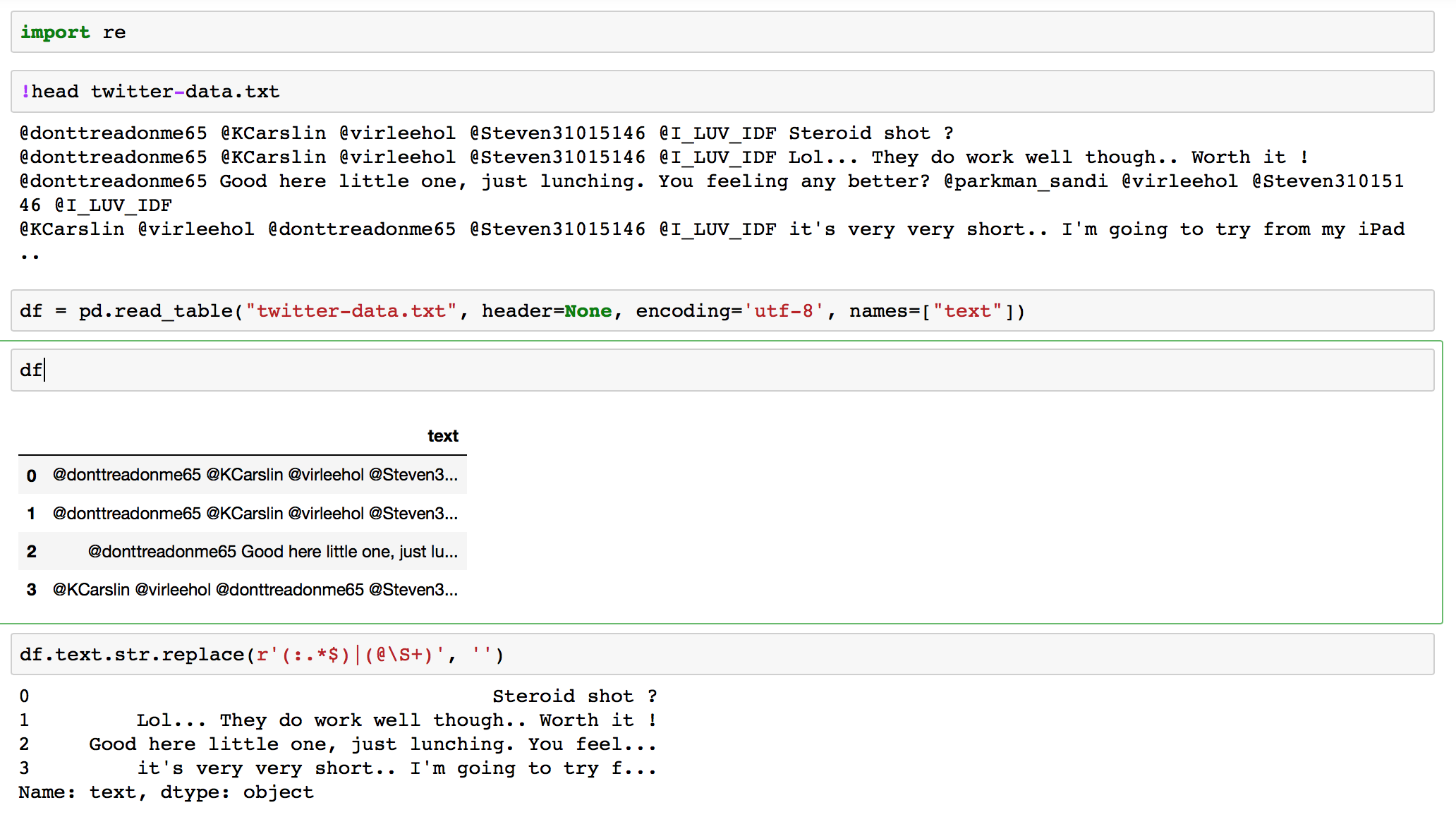
To give an example of the scope of the issue look at the following twitter conversation - even if I said to drop words with a frequency of less than 10 it would not eliminate these, and also the useful information in the text is almost non-existent once the twitter ids have been eliminated.
@donttreadonme65 @KCarslin @virleehol @Steven31015146 @I_LUV_IDF Steroid shot ?
@donttreadonme65 @KCarslin @virleehol @Steven31015146 @I_LUV_IDF Lol... They do work well though.. Worth it !
@donttreadonme65 Good here little one, just lunching. You feeling any better? @parkman_sandi @virleehol @Steven31015146 @I_LUV_IDF
@KCarslin @virleehol @donttreadonme65 @Steven31015146 @I_LUV_IDF it's very very short.. I'm going to try from my iPad..
@I_LUV_IDF @Steven31015146 @KCarslin @parkman_sandi @virleehol Awe a sweetie pie:-)pic.twitter.com/41TUYqC4sI
@donttreadonme65 @KCarslin @virleehol @Steven31015146 @I_LUV_IDF in the bumm too.. No doubt ! Those will light your behind up !! Ouch !
@donttreadonme65 @KCarslin @parkman_sandi @virleehol @I_LUV_IDF sorry I'm late, but I pray for your healing
@parkman_sandi @KCarslin @virleehol @Steven31015146 @I_LUV_IDF True whole hip and ass sore lol
@parkman_sandi Done, no laughing. Got it? ;-) @virleehol @donttreadonme65 @Steven31015146 @I_LUV_IDF
@parkman_sandi @KCarslin @virleehol @Steven31015146 @I_LUV_IDF Shot that hurt like Hell but feeling better today TY #tweetiepie #besties
@KCarslin @virleehol @donttreadonme65 @Steven31015146 @I_LUV_IDF yes born in May
@donttreadonme65 Dispatch, K9 needs backup!!! @I_LUV_IDF @Steven31015146 @parkman_sandi @virleehol
@KCarslin @virleehol @donttreadonme65 @Steven31015146 @I_LUV_IDF @KCarslin DM me your email address and I can..
@KCarslin @donttreadonme65 @parkman_sandi @virleehol @I_LUV_IDFpic.twitter.com/ZXJgAfyVBf
@parkman_sandi @KCarslin @virleehol @Steven31015146 @I_LUV_IDF OMG yes:(
@parkman_sandi Still no luck? @virleehol @donttreadonme65 @Steven31015146 @I_LUV_IDF
@parkman_sandi You'd mentioned getting in October, wasn't sure if a kitten at time. @virleehol @donttreadonme65 @Steven31015146 @I_LUV_IDF
@KCarslin @virleehol @donttreadonme65 @Steven31015146 @I_LUV_IDF @KCarslin too late.. Already laughed. Saw the DM before seeing this !
@KCarslin @I_LUV_IDF @Steven31015146 @parkman_sandi @virleehol Lol yea he could you some
@donttreadonme65 @KCarslin @virleehol @Steven31015146 @I_LUV_IDF Sorry to hear that. Sending hugs & positive energy your way ! xoxo
@Steven31015146 With you on that Doc. Get well soon little one. :'( @donttreadonme65 @parkman_sandi @virleehol @I_LUV_IDF
@parkman_sandi Yep, seen yours first also. ;-) Kitteh is still pretty young.?. @virleehol @donttreadonme65 @Steven31015146 @I_LUV_IDF
@KCarslin @parkman_sandi @virleehol @Steven31015146 @I_LUV_IDF Thanks Sandy my grandson had the flu so now I have it:( I have COPD so worse