I was wondering what is the best approach to dealing with uncertainty when giving predictions, specifically to combat the issue of out-of-class samples.
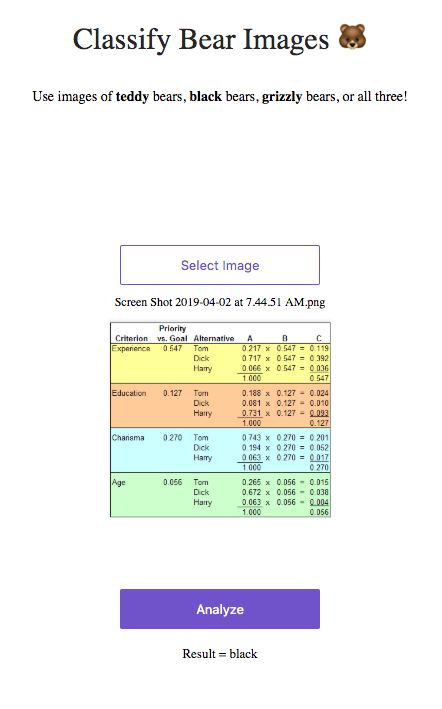
In the example of the bear classifier (https://fastai-v3.onrender.com/), if I give it a nonsensical sample image (like a desk), it will still predict that it’s a type of bear.
I was thinking you could add another class called ‘not bear’ or ‘unknown’ which is trained on a bunch of random images that don’t have bears in them. Or use the prediction output probability, where if none of the probabilities are above 95% then output ‘unknown’.
Are these valid approaches or are there better ones to consider?
I suspect the best approach would come from considering the specific needs of your application. Why do you want to classify out-of-class samples?
For example, if you’re just wanting an insurance policy so that your app doesn’t look silly (pizza classified as grizzly bear), I think a random sample of Imagenet-type photos could work. On the other hand, if you think your users will be likely to upload out-of-class samples that are more similar to your classes (say, another type of large animal that resembles a bear), then you might want to curate a set of more relevant examples for the “other” category.
I don’t think using the prediction probability will work. I think you’ll find that pizzas are often classified as some sort of bear with high confidence.
No, it is not just an insurance policy. For example, I am trying to do identification of bioacoustic calls in audio recordings, sort of an auditory scene analysis. The files (spectrogram images) are labeled "calls " and “nothing” (which basically means anything but calls). This task has proven to be super hard, because “nothing” files are super heterogenous, and so far I do not get very good results, even for validation, let alone when I use my best model and give it a spectrogram it has not seen before.
It is the same with bears, it seems to be easier to do teddy versus grizzly, compared to “bear” versus “not bear”, because the possibilities of “no bear” are nearly endless. I might be mistaken, but I hope it makes sense. Maybe someone can give an example where the model did very good on “not that” task?
I think there are two main reasons why you will observe this seemingly nonsensical behavior.
First, if you’re asking a bear-color-classifier to look at a pizza, you’re asking it to make a prediction about an input that is different from the type of data it was trained on. As a general rule, machine learning models can only be expected to give useful results if the data used for inference is similar to the data used in training/ validation. This is always an important consideration when deploying a model in production, especially since the nature of inference data can drift over time and become too dissimilar. (Think of a movie poster classifier where, over time, styles and genre conventions are changing. The model will need to be retrained on more relevant data periodically.)
The second reason is that your classifier has a final softmax activation layer. The softmax function smoothly approximates argmax: it outputs a set of numbers where (typically) one number is close to 1 and the other numbers are close to 0. So, inherent in the architecture is a tendency to produce high-confidence predictions.
I’ve been thinking about this a little and doing some reading. This problem (“is the image one of my classes or something else?”) is an instance of the one-class classification problem. That problem is central in tasks like anomaly detection, where (for example) we probably have lots of examples of normal transactions, but few or no examples of anomalous ones — and the space of possible anomalous transactions is vast!
There are different approaches to handling this. In casual searching, I found one paper specifically addressing a solution for convolutional neural networks and image classification. Maybe this will help: