i am trying to do image classification with full Mnist data set.
i created a data block: mnist = DataBlock(blocks = (ImageBlock(cls=PILImageBW), CategoryBlock), get_items = get_image_files, splitter = GrandparentSplitter(), get_y = parent_label)
when i try and make a data loader: dls = mnist.dataloaders(path)
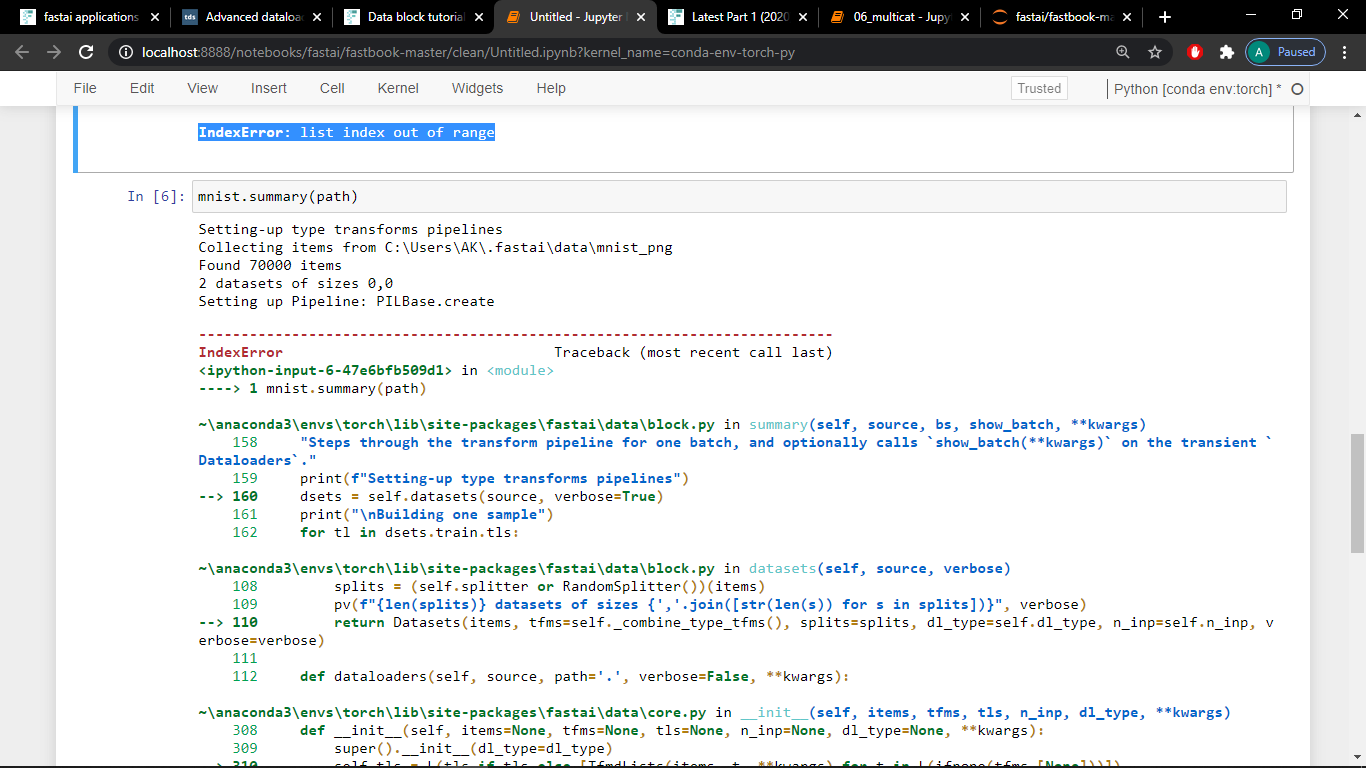
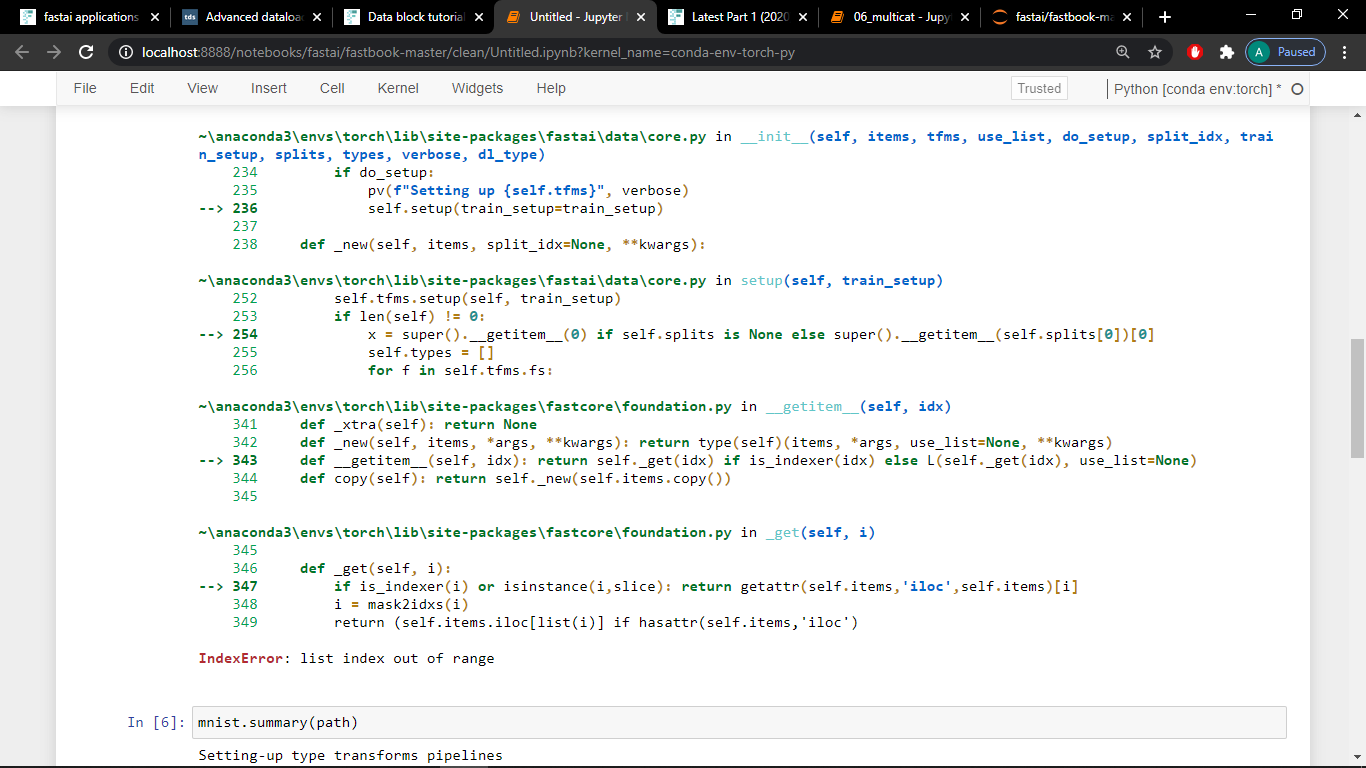
i get a IndexError: list index out of range
then i checked mnist.summary(path) to check the what went wrong! There are 70000 items but the size of the two datasets are shown as zero
What am i doing wrong because it works for the mnist_sample only containing 3s & 7s .
Hi @Ark52 I haven’t fully found a solution, but I was able to generate the DataLoaders object once I removed the GrandparentSplitter() so I assume another function for the splitter is needed. Here’s a colab with my code:
Does this mean the MNIST dataset in fastai bucket is not compatible with default behavior of GrandparentSplitter and the code in train_mnist.ipynb doesn’t work as-is?
The default name for train_name is train but tje folder name given in the data set is training same for the valid set.
Give arguments to GrandparentSplitter(train_name=“training”, valid_name= “testing”)
Having the same problem while following this example.
At the part where I create a DataBlock and dataloaders and I get that list index out of range error.
Like @vbakshi getting rid of the splitter=GrandparentSplitter arg allows me to create the dataloaders, but not sure what I should replace that with - is it needed?
In the summary I see that it has found my 2 datasets, ‘train’ (248 items) and valid (62 items) :
Setting-up type transforms pipelines
Collecting items from /home/paperspace/deid/data
Found 310 items
2 datasets of sizes 248,62
...