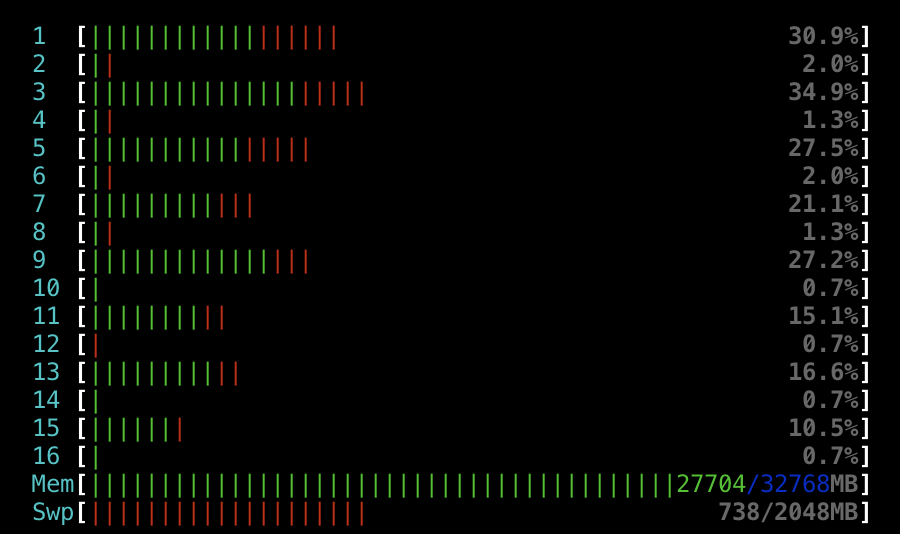
Problem: dataloader is not using all CPUs. Because of that training is very slow.
My environment:
MacOS
Python 3.6
Fastai==2.1.5
Torch==1.7.0
I am creating a dataloader like this:
textblock = TextBlock.from_df(
'_VALUE', # Which dataframe column to read
is_lm=True, # We only have X and no Y for the language model
tok=RulesTokenizer(),
rules=[] # Diable default fastai rules
)
datablock = DataBlock(
blocks=textblock, # That's how we read, tokenize and get X
get_x=ColReader('text'), # After going through TextBlock, tokens are in the column `text`
splitter=RandomSplitter(0.2) # Splitting to train/validation
)
dataloader = datablock.dataloaders(
subset, # Source of data
bs=256, # Batch size
num_workers=8,
pin_memory=True,
)
When I attempt to train, I get a bunch of duplicate errors:
[W ParallelNative.cpp:206] Warning: Cannot set number of intraop threads after parallel work has started or after set_num_threads call when using native parallel backend (function set_num_threads)
From this article, it appears that Pytorch has an error in 1.7 related to parallel processing.
Setting an environment variable to 1 removes the error: export OMP_NUM_THREADS=1
(Potentially) as a result of it CPU load is very low (no parallel computing?) and training is slow too. I am training on CPU-only Mac, so I expect all CPUs to run at 100% to reach good speeds. But seems like the dataloader is the bottleneck due to lack of parallel computing.
I was not able to solve it on CPU-only machine. I tried py3.6 and 3.8 - same result. The difference in 3.8 is that multiprocessing works differently, but it doesn’t seem to affect the problem.
The problem is not reproduced on GPU-machines. I am able to use multi-threaded data processing and there is no warning like this.