There are several useful methods to create a databunch from a folder, csv labels, etc.
However, I have (grayscale) images data that is already within an array - i.e.
X.shape: (n_samples, 100, 100)
y.shape: (n_samples)
Is there a way to create a databunch straight from these (numpy) arrays?
I saw another post asking the same here (currently unanswered):
You would need to create your custom dataset for this, but it’s not too complicated: jsut subclass DatasetBaset and define __len__, __getitem__ and c (number of classes).
Once you have your custom Dataset class you can just create a DataBunch from it via DataBunch.create.
There are several issues with reading and viewing grayscal in the current version. I am however working on several PRs to fastai to make it easier to include conversion of grayscale
That may explain the errors I was getting. I implemented a dataset as suggested above (thank you sgugger!):
class NumpyDataset(DatasetBase):
def __init__(self, X, y=None):
super().__init__(np.unique(y))
self.classes = np.unique(y)
self.c = len(np.unique(y))
self.X = X
if y is not None: self.y = y
def __getitem__(self, i):
if self.y is not None: return (Tensor(self.X[i]).to(torch.float), Tensor(self.y[i]).to(torch.float))
return Tensor(X[i]).to(float)
def __len__(self): return len(self.X)
and got the following error, which I couldn’t yet find its source:
RuntimeError: Traceback (most recent call last):
File "/opt/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 138, in _worker_loop
samples = collate_fn([dataset[i] for i in batch_indices])
File "/opt/anaconda3/lib/python3.6/site-packages/fastai/torch_core.py", line 91, in data_collate
return torch.utils.data.dataloader.default_collate(to_data(batch))
File "/opt/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 232, in default_collate
return [default_collate(samples) for samples in transposed]
File "/opt/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 232, in <listcomp>
return [default_collate(samples) for samples in transposed]
File "/opt/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 209, in default_collate
return torch.stack(batch, 0, out=out)
RuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 0. Got 1 and 8 in dimension 1 at /opt/conda/conda-bld/pytorch-nightly_1540121100527/work/aten/src/TH/generic/THTensorMoreMath.cpp:1317
but in light of what you describe above, maybe a quick (and inefficient) fix for me would be to duplicate the grayscale data to 3 channels, as in a color image, or just add 2 more 0 channels.
I’m not sure I can use your code as is because my data is already in a numpy array format, not an image file, and I don’t want to take the extra step of converting it to many image files and back to a tensor. I’ll keep trying and update… and will be gratefull with more ideas.
Converting 16bit to rgb will lead to a loss in precision. that may os may not be important to you
The PR i am working on also takes a numpy (see below).
Better keep you data in numpy and convert them to tensor as below. Also remember to convert to float an divide by the appropriate scaling factor
def pil2tensor(image])
“Convert PIL.Image or numpy.ndarray to torch tensor.”
a = np.asarray(image)
if a.ndim==2 : a = np.expand_dims(a,2)
a = np.transpose(a, (1,0,2)) #transpose width, height to height,width
a = np.transpose(a, (2, 1, 0)) #move channels to the first position
if a.dtype == bool : a = a.astype(np.uint8)
elif a.dtype in [np.dtype(">u2"), np.uint16] : a = a.astype(np.int32)
return torch.from_numpy(a)
After creating a custom dataset from DatasetBase, I passed it to DataBunch.create() that’s when I got the error: invalid argument 0: Sizes of tensors must match except in dimension 0
In order to handle sizing easily, I thought I’d try to pass the Dataset to ImageDataBunch.create() instead, and call it with the size option, this produced a different error: ‘Tensor’ object has no attribute ‘set_sample’
I gave up for today , but thought to see if you have any updates about this
if the issue is about 16 bit grayscale images then the following can help ?
you can now create your own open_image like in the following:
def open_image_16bit2rgb( fn ):
# step 1 : open 16 bit grayscale and convert to int32 and create a view on the image a np.asarray
a = np.asarray(PIL.Image.open( fn ).convert(“I”)) #step 2: add an 1 dimension so we have height, width, 1 channel
a = np.expand_dims(a,axis=2) #create two extra channels to make it an rgb image
a = np.repeat(a, 3, axis=2)
return Image( pil2tensor(a, np.float32 ).div(65535) )
or if you already have a np.array like width * height *1 channel then start at step2
By the way you should set the image_opener in the dataset. This can be done using the datablock design and through the ImageDatabunch
Thanks for your continuous interest and help!
for me at least (don’t know about Zeina) the case is that my data is synthetic and represented as a numpy array. It was never an image in the first place.
It seems that this is the simpler case - ultimately all the image become numpy (or pytorch) tensors anyhow. But somehow I get errors when I try to change the pipeline to work with this data.
To be explicit, lets say I create a tensor of the following shape:
data = np.random.randn(100,50,50)
which in my case represents 100 samples of 50x50 grayscale “images”.
I don’t know exactly how to connect with your function Pil2Tensor. Ultimately, it would be nice to have the following command: data = ImageDataBunch.from_numpy(data, train_idxs, valid_idxs, n_channels)
or something similar that will get a numpy array, and use it for the next modeling stages as image data given the number of channels (which ideally can be anything >=1).
I started building it, but got into some trouble and didn’t yet find the time to solve it… I will probably do it but it will take some more time for me.
If you know the flow of actions required to fit a pre-trained model such as resnet with data of this kind, without the errors, and can make it public here, it will be very helpful for me (and probably others…)
fastai basically need a list of references to input data vs output data. This does not have to be images on a disk although that would be the most straight forward case. The list should be split into a training and a validation set by you or fastai.
I have not implemented your case but would go about it approximately as follows. @sgugger would certainly be able to propose a muc more elegant approach
class MyMemoryData
validIDs
validInput
validOutput
trainIDs
trainInput
trainOutput
def memorydata2tensor( id ):
a = MyMemoryData.validInput[id]
#step 2: add an 1 dimension so we have height, width, 1 channel
a = np.expand_dims(a,axis=2)
#create two extra channels to make it an rgb image
a = np.repeat(a, 3, axis=2)
return Image( pil2tensor(a, np.float32 ).div(65535) )
MyMemoryData.validInput = your input data
MyMemoryData.validOutput = your ouput data validation . ie classes
MyMemoryData.validIDs = np.arange( MyMemoryData.ValidInput )
MyMemoryData.trainInput = your input data
MyMemoryData.trainOutput = your ouput data for training . ie classes
MyMemoryData.trainIDs = np.arange( MyMemoryData.trainInput )
data = ImageDataBunch.create(
dsTrainTfm,
dsValidTfm,
bs=8,
size=224
)
data.normalize(imagenet_stats) # i guess you are not usng pretrained net so you would need your own means and stds to normalize
If it might be helpful, I’ve created a custom dataset for a Kaggle competition that takes drawings encoded as a sequence, converts them to greyscal images and feeds the images to the network - and it is compatible with fastai tools. The notebook is below:
While giving up and saving all arrays into image files would save me the trouble, I think getting images from arrays is very useful in general so I’m trying to persevere.
Tried the channels trick (took a serious amount of time )
I think I have everything right but it still doesn’t work.
I’m pretty sure it’s a problem with getting the batches in Pytorch’s DataLoader.
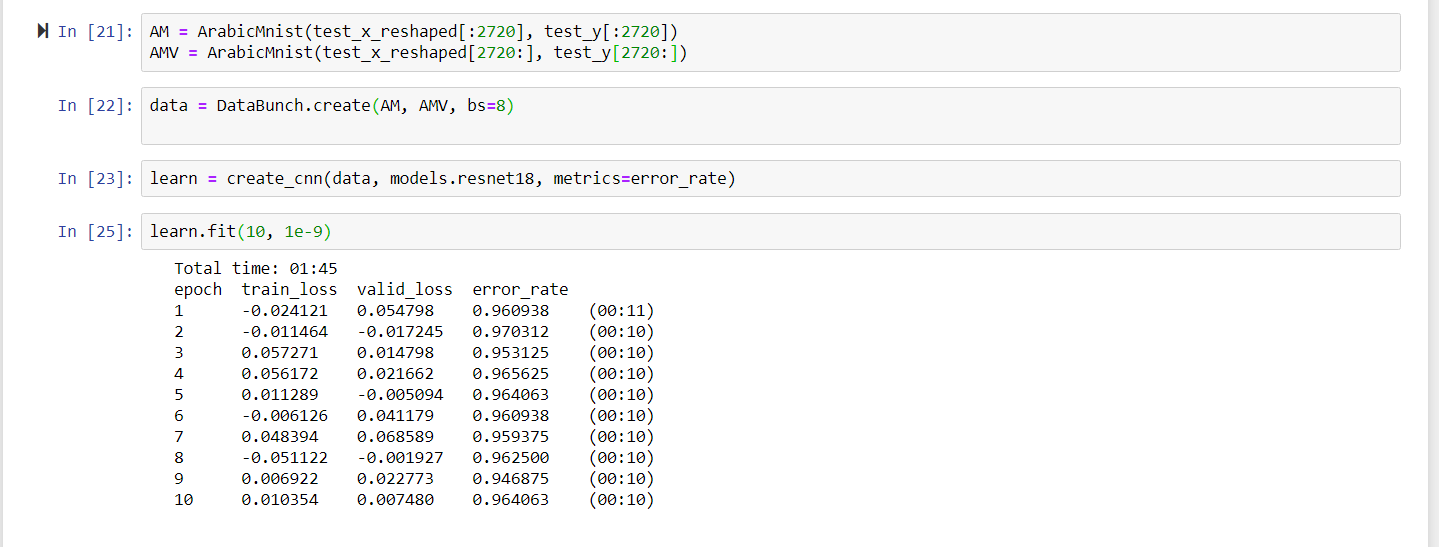
@sgugger Why my train and validation loss is going negative? Loss function here is nll_loss and I have not used any data transformations. Loss is negative with resnet18 and lr as low as 1e-9
I’ve had good success saving numpy arrays as png using this general flow:
numpy array named arr filled with integers(though I think this would work for floats also).
arr = (arr-arr.mean()) / arr.std() #normalizes between -1 and +1
arr = (arr + 1) / 2 * 255 # moves it between 0 and 255
arr = np.clip(arr, 0, 255).astype(np.uint8), clips it between 0 and 255 and converts to 8 bit int.
imageio.imwrite(output_filename, arr)
Using these I have created a databunch through the data block api or the higher level api.
My interpretation is that, we are feeding torch’s nll_loss the output of model and true lables. And as per my understanding (and running manually) I find below observations.
Model output of one batch is fed to nll_loss 's input.
Target lables (0 indexed) are fed to nll_loss as target.
nll_loss is simply returning the -sum(target * input) or -sum(input[target]). Which I believe should not be the case as negative log likelihood is defined as sum(y*logp)
Here in run number 67 nll_loss simply took negative of index 27 value from input and run number 69 took nll_loss as negative of index 11 from input.
Why is that the case? Why it is not taking the log? Also, this is why I believe I was getting the negative loss as well. Both of the inputs in the above image are taken while debugging and running my above notebook.
Have you checked if the problem is with the order of the array? It is common to have a numpy array where channels is the last dimension, something like X.shape will return (5000, 120,120,3) 5000 samples of 120hx120wx3c`. But pytorch expects 3, 120, 120, 5000.
I am looking forward a solution myself, if I manage to solve, I will post here.
I’d love to see some example custom data classes from this problem or anything really. please post if you have done it successfully(or not successfully).
 , but thought to see if you have any updates about this
, but thought to see if you have any updates about this 

 )
)