Hello Everyone,
Here I would like to share something that 2 of my kaggle buddies @groverpr, @shik1470 and I were discussing thoroughly while doing Porto Seguro’s Insurance Challenge. We’ve managed to be at top ~10% with LB 0.285.
The methods we employed through this score were highly unorthodox in the way of modeling we had been doing before. Our final best prediction depends on this formula => max(average of 2 models, average 3 models) . Even though this gives us a really good result on LB and even though a lot of people have been applying similar techniques so far in Kaggle for this competition, this might be a way to overfitting to LB !!!
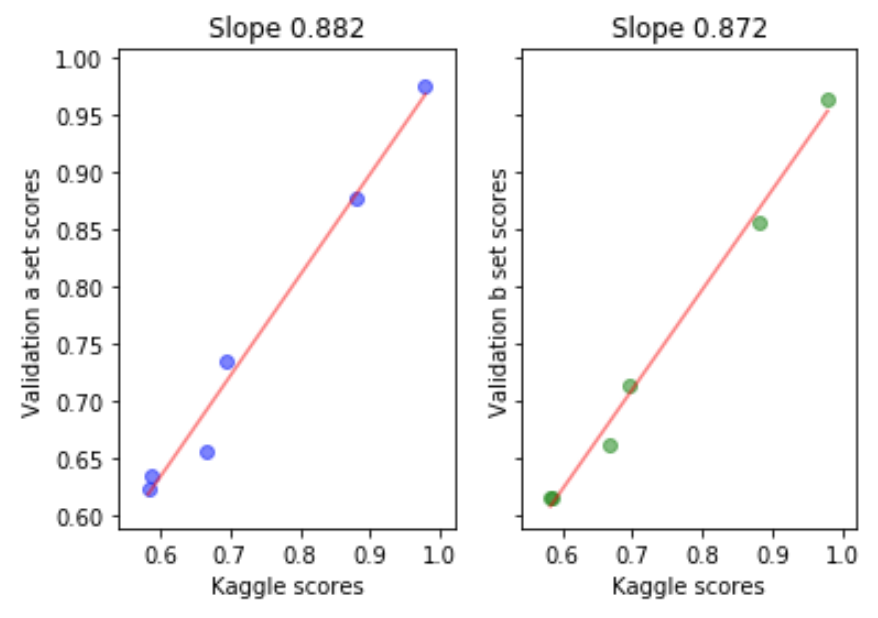
One of the best things to always check is how your CV and LB evolve together, whether indeed they have a linear relationship overtime (even if it is a low order polynomial). CV-LB graphs shown during last course were very good examples on how to keep track of this and how to truly trust your model.
The other side of the medallion is that, in fact your LB score only corresponds to a portion (30% if I am not mistaken) of the true test data, which makes it vulnerable to overfitting and holding a great danger of inability to generalize to the 100% of this test set.
In short, construct a good CV schema and trust it even though it sucks :D. You never know, don’t be discouraged, maybe most of the top runners are overfitting to LB by following other kernel combinations and LB performance! I have been reading about examples of this from past competition discussions, as well as the current one and you would be amazed on how much LB can change after once it’s evaluated on full test set.
Just wanted to share an interesting case and truth 
Note: I will probably choose one model that’s really good at CV as my submission at the end, even though it’s not very good at LB. Gotta keep experimenting…
Cheers