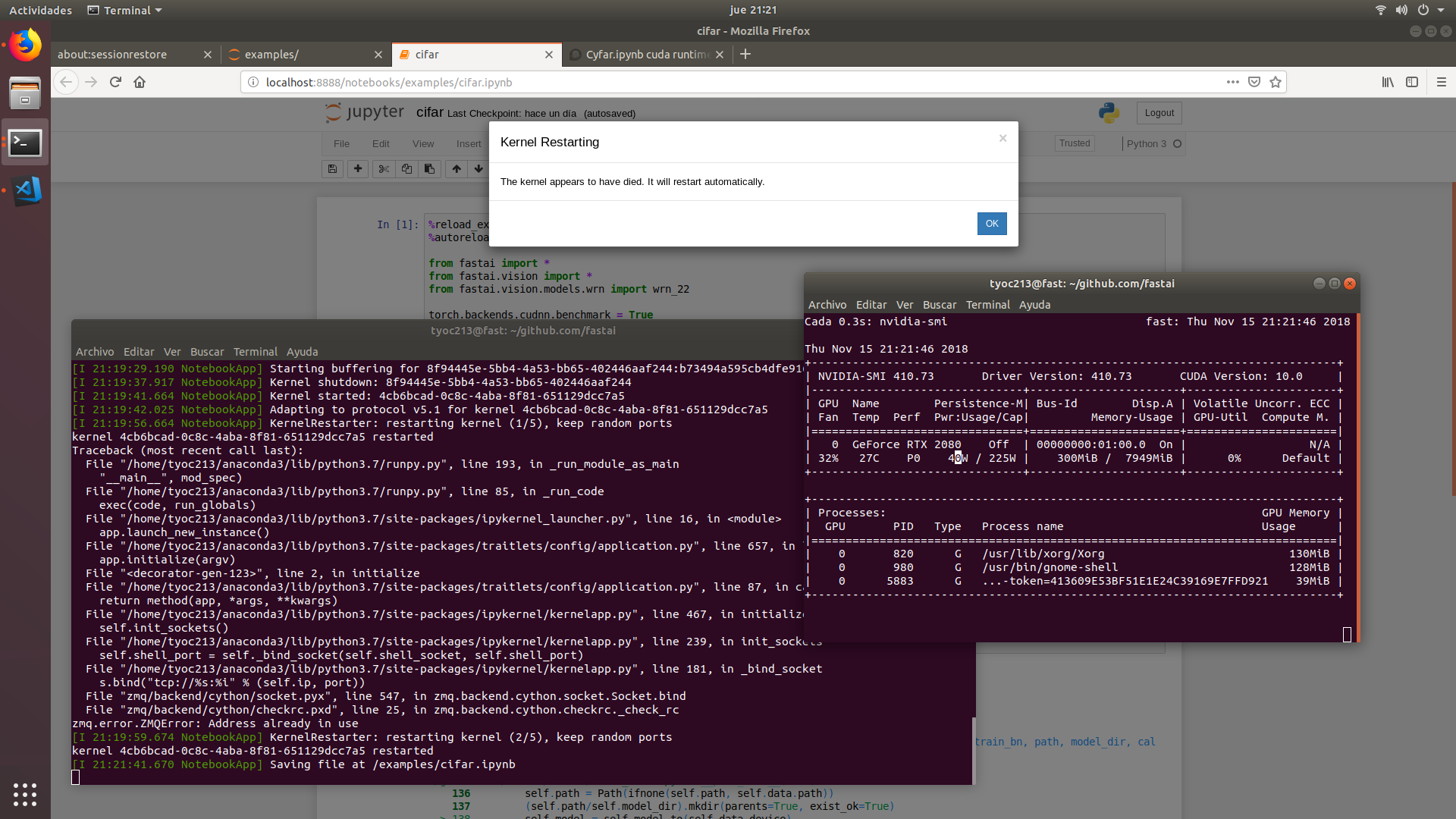
Hi there I just reainstalled my home PC to start all over again
Here is fastai.show_install()
=== Software ===
python version : 3.7.0
fastai version : 1.0.20.dev0
torch version : 1.0.0.dev20181105
nvidia driver : 410.73
torch cuda ver : 9.2.148
torch cuda is : available
torch cudnn ver : 7104
torch cudnn is : enabled
=== Hardware ===
nvidia gpus : 1
torch available : 1
- gpu0 : 7949MB | GeForce RTX 2080
=== Environment ===
platform : Linux-4.18.0-10-generic-x86_64-with-debian-buster-sid
distro : Ubuntu 18.10 Cosmic Cuttlefish
conda env : base
python : /home/tyoc213/anaconda3/bin/python
sys.path :
/home/tyoc213/fastai/examples
/home/tyoc213/anaconda3/lib/python37.zip
/home/tyoc213/anaconda3/lib/python3.7
/home/tyoc213/anaconda3/lib/python3.7/lib-dynload
/home/tyoc213/anaconda3/lib/python3.7/site-packages
/home/tyoc213/fastai
/home/tyoc213/anaconda3/lib/python3.7/site-packages/IPython/extensions
/home/tyoc213/.ipython
collab.ipynb works OK but stepping on cyfar on fastai/examples I an error executing this line
learn = Learner(data, wrn_22(), metrics=accuracy).to_fp16()
learn.fit_one_cycle(30, 3e-3, wd=0.4, div_factor=10, pct_start=0.5)
I get this output
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-14-72f1e2b0093b> in <module>()
----> 1 learn = Learner(data, wrn_22(), metrics=accuracy).to_fp16()
2 learn.fit_one_cycle(30, 3e-3, wd=0.4, div_factor=10, pct_start=0.5)
<string> in __init__(self, data, model, opt_func, loss_func, metrics, true_wd, bn_wd, wd, train_bn, path, model_dir, callback_fns, callbacks, layer_groups)
~/fastai/fastai/basic_train.py in __post_init__(self)
136 self.path = Path(ifnone(self.path, self.data.path))
137 (self.path/self.model_dir).mkdir(parents=True, exist_ok=True)
--> 138 self.model = self.model.to(self.data.device)
139 self.loss_func = ifnone(self.loss_func, self.data.loss_func)
140 self.metrics=listify(self.metrics)
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in to(self, *args, **kwargs)
377 return t.to(device, dtype if t.is_floating_point() else None, non_blocking)
378
--> 379 return self._apply(convert)
380
381 def register_backward_hook(self, hook):
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _apply(self, fn)
183 def _apply(self, fn):
184 for module in self.children():
--> 185 module._apply(fn)
186
187 for param in self._parameters.values():
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _apply(self, fn)
183 def _apply(self, fn):
184 for module in self.children():
--> 185 module._apply(fn)
186
187 for param in self._parameters.values():
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _apply(self, fn)
189 # Tensors stored in modules are graph leaves, and we don't
190 # want to create copy nodes, so we have to unpack the data.
--> 191 param.data = fn(param.data)
192 if param._grad is not None:
193 param._grad.data = fn(param._grad.data)
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in convert(t)
375
376 def convert(t):
--> 377 return t.to(device, dtype if t.is_floating_point() else None, non_blocking)
378
379 return self._apply(convert)
RuntimeError: cuda runtime error (77) : an illegal memory access was encountered at /opt/conda/conda-bld/pytorch-nightly_1541411195070/work/aten/src/THC/generic/THCTensorCopy.cpp:20
if running torch.cuda.is_available() return True.
Update extra tests
Im also running out of memory in dogs_cats.ipynb.
learn = create_cnn(data, models.resnet34, metrics=accuracy)
learn.fit_one_cycle(1)
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-9-6ec085df1eed> in <module>()
----> 1 learn = create_cnn(data, models.resnet34, metrics=accuracy)
2 learn.fit_one_cycle(1)
~/fastai/fastai/vision/learner.py in create_cnn(data, arch, cut, pretrained, lin_ftrs, ps, custom_head, split_on, classification, **kwargs)
67 learn.split(ifnone(split_on,meta['split']))
68 if pretrained: learn.freeze()
---> 69 apply_init(model[1], nn.init.kaiming_normal_)
70 return learn
71
~/fastai/fastai/torch_core.py in apply_init(m, init_func)
193 def apply_init(m, init_func:LayerFunc):
194 "Initialize all non-batchnorm layers of `m` with `init_func`."
--> 195 apply_leaf(m, partial(cond_init, init_func=init_func))
196
197 def in_channels(m:nn.Module) -> List[int]:
~/fastai/fastai/torch_core.py in apply_leaf(m, f)
189 c = children(m)
190 if isinstance(m, nn.Module): f(m)
--> 191 for l in c: apply_leaf(l,f)
192
193 def apply_init(m, init_func:LayerFunc):
~/fastai/fastai/torch_core.py in apply_leaf(m, f)
188 "Apply `f` to children of `m`."
189 c = children(m)
--> 190 if isinstance(m, nn.Module): f(m)
191 for l in c: apply_leaf(l,f)
192
~/fastai/fastai/torch_core.py in cond_init(m, init_func)
183 if (not isinstance(m, bn_types)) and requires_grad(m):
184 if hasattr(m, 'weight'): init_func(m.weight)
--> 185 if hasattr(m, 'bias') and hasattr(m.bias, 'data'): m.bias.data.fill_(0.)
186
187 def apply_leaf(m:nn.Module, f:LayerFunc):
RuntimeError: cuda runtime error (2) : out of memory at /opt/conda/conda-bld/pytorch-nightly_1541411195070/work/aten/src/THC/generic/THCTensorMath.cu:14
I get the cuda memory error also in tabular
learn = get_tabular_learner(data, layers=[200,100], metrics=accuracy)
learn.fit(1, 1e-2)
output
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-5-480eb9caae1a> in <module>()
----> 1 learn = get_tabular_learner(data, layers=[200,100], metrics=accuracy)
2 learn.fit(1, 1e-2)
~/fastai/fastai/tabular/data.py in get_tabular_learner(data, layers, emb_szs, metrics, ps, emb_drop, y_range, use_bn, **kwargs)
93 model = TabularModel(emb_szs, len(data.cont_names), out_sz=data.c, layers=layers, ps=ps, emb_drop=emb_drop,
94 y_range=y_range, use_bn=use_bn)
---> 95 return Learner(data, model, metrics=metrics, **kwargs)
96
<string> in __init__(self, data, model, opt_func, loss_func, metrics, true_wd, bn_wd, wd, train_bn, path, model_dir, callback_fns, callbacks, layer_groups)
~/fastai/fastai/basic_train.py in __post_init__(self)
136 self.path = Path(ifnone(self.path, self.data.path))
137 (self.path/self.model_dir).mkdir(parents=True, exist_ok=True)
--> 138 self.model = self.model.to(self.data.device)
139 self.loss_func = ifnone(self.loss_func, self.data.loss_func)
140 self.metrics=listify(self.metrics)
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in to(self, *args, **kwargs)
377 return t.to(device, dtype if t.is_floating_point() else None, non_blocking)
378
--> 379 return self._apply(convert)
380
381 def register_backward_hook(self, hook):
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _apply(self, fn)
183 def _apply(self, fn):
184 for module in self.children():
--> 185 module._apply(fn)
186
187 for param in self._parameters.values():
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _apply(self, fn)
183 def _apply(self, fn):
184 for module in self.children():
--> 185 module._apply(fn)
186
187 for param in self._parameters.values():
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _apply(self, fn)
189 # Tensors stored in modules are graph leaves, and we don't
190 # want to create copy nodes, so we have to unpack the data.
--> 191 param.data = fn(param.data)
192 if param._grad is not None:
193 param._grad.data = fn(param._grad.data)
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in convert(t)
375
376 def convert(t):
--> 377 return t.to(device, dtype if t.is_floating_point() else None, non_blocking)
378
379 return self._apply(convert)
RuntimeError: CUDA error: out of memory