I put together a cyclical learning rate callback class for use with Keras models. You can use any of the three policies detailed in the original paper, as well as create your own amplitude scaling functions. Check it out, feedback welcome!
14 Likes
I was just about to start one implementation too. Thanks @bckenstler
1 Like
Awesome. If you could include in the readme at the top a graph showing the impact of this on some well-known dataset (even MNIST would be fine) I think it would get a lot more people to try this out; few people are familiar with this paper so few will understand why it’s a good idea.
You could even just copy the graph from the paper itself, I guess!.. Along with a couple of sentences telling people why they should use this.
1 Like
Sweet!!
@bckenstler, well done! Of course, I had to try it.
I followed your instructions on optimizing the parameters for clr using a triangular policy.
base_lr = 1e-5, max_lr=1e-3, step_size=500
I used only 50 samples and 5 epochs, but got a somewhat inconclusive output (apart from the fascination to look at acc and loss with this high resolution) - what am I missing?
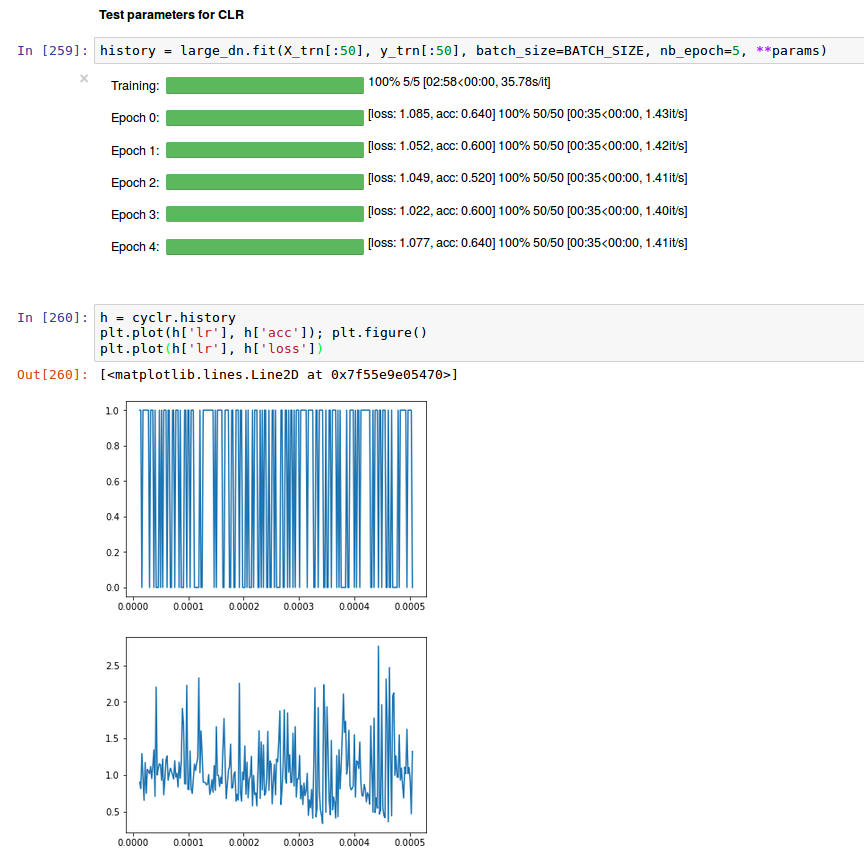
EDIT: I noticed that I didn’t cover the full range of lr’s because my step_size wasn’t ideal. But the range of acc itself puzzled me.
50 samples seems too few to get anything much useful out of this. Try it on a model that you already have a reasonably good learning rate schedule for, and see if CLR beats it (or at least gets close to it without manual tuning).
I tried 500 samples, too. The overall picture didn’t change. I think there is a more general problem that I need to solve first. When doing manual lr annealing I eventually get high accuracy, but abysmal val_acc, so lots of overfitting. There may also be too much heterogeneity in the data. So, I’ll go back and address those issues first.
Now we can save model weights during intermediate epochs when the learning rate is low (and the model is around local minima) and use the saved models later for ensembling for an additional percent or two. When the learning rate is high there’s a probability that the model will skip to a different local minimum. This way we can gather several models for ensembling during single train pass.
Author of original paper states that “LR range test” “… is enormously valuable whenever you are facing a new architecture or dataset” have you tried replicating their plot of LR vs ACC? I have tried on state farm dataset with VGG16 and I am getting pretty smooth graphs. There is no “ragged” period. 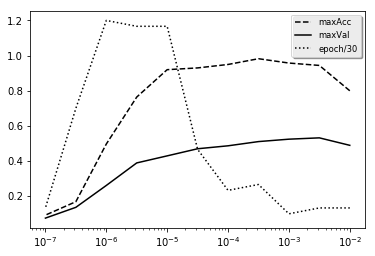
For the LR Range Test, simply plotting Learning Rate (x-axis) versus Accuracy (y-axis) gives the results per mini-batch, which tends to lead to quite difficult to interpret graphs:
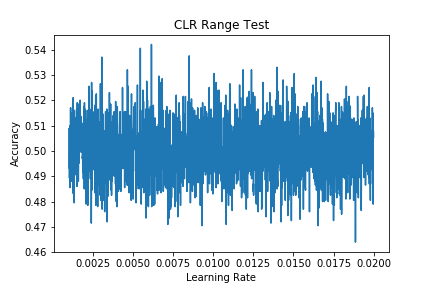
How are people dealing with this? E.g. would you average accuracy over each minibatch per epoch and plot that instead? If so, would you need to also average the learning rates?
Thanks.
What is the best strategy for k-fold training ? To reset the CLR after each fold or just continue learning? Are there better alternative ways to use CLR with k-folds?
Does your model learn with default optimizer settings? If yes, you can try increasing learning rate range (say 1-6 to 1e0 for Adam), number of epochs for the test and then use exponential smoothing or similar technique to detect train regime changes.
Your folds shouldn’t be that different from each other so that they need different learning rates.