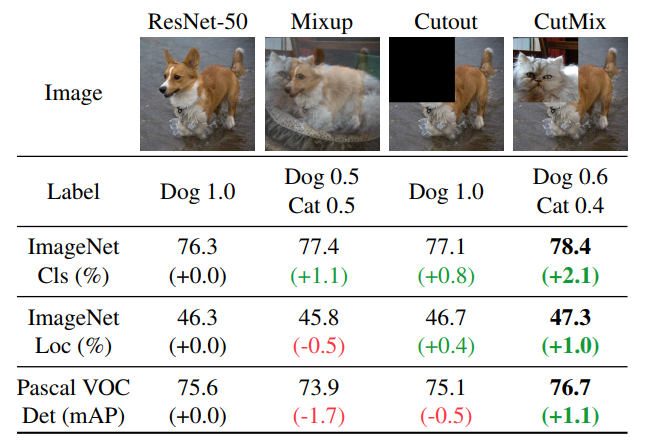
A paper from last month introduces CutMix, which they show superior performance vs Mixup and Cutout on a variety of datasets including Imagenet.
Cutmix = combininig two images but instead of overlaying based on opacity (mixup), they simply create a photo from two rectangles that are subsets of the original photos.
github repo:
From the paper at least, CutMix outperforms Mixup across the board.
Thoughts?
Very interesting. I wonder how / if it works for tabular data. I’ve been meaning to explore Mixup there, but I’m already using batchwise swap noise and all I’d need to change there are my targets.
I’ve used it quite effectively in a denoising autoencoder, but in terms of the fastai tabular model it wasn’t as effective as I’d hoped. It does seem to improve things somewhat, but it adds another hyperparameter to tune, so its not a clear win.
I’d love to hear about what other methods you’ve used or heard about in the past. My main role right now is developing preprocessing and models for tabular data and working to improve their performance on the GPU side.
Cool. Yeah, I’ve had some success with DAEs and swap noise for categorical variables + random noise for continuous variables. Still nothing ground-breaking. I haven’t had time to put code to interpreters yet, but I’ve been ruminating a bit over augmenting training records with GANs. I think the same idea applies in CV but maybe it’s not worth the trouble because creating a good GAN by itself is so much trouble.
Thanks for posting your results!
Question - how are you controlling the % split between images? I read in another paper that makes a big difference.
I only quickly looked at your github and you have a probability input coming in but it’s not used?
I’m thus wondering if the cutmix could end up frequently being so little of one image vs another (say 10% and 90%) that the 10% is not useful to learn from…
Anyway, I’m planning to setup and use it for a project shortly and will see what results I get and will post.
wow, good call - CutMix is basically identical except Cutmix uses 2 images, Ricap uses 4…that’s about the only difference I see from a quick read of RICAP.
Guess that means I can write a new paper on my brand new, highly innovative “Trimix” where I use 3 images
I’ve created a repo with callback implementations of ricap and cutmix.
They can be used in the same way as mixup.
I have tested the image transformations and seem to be ok.
I have only used them in a proprietary image dataset, but have not tested them on any other dataset.
If you want to use it, please feel free to do so.
Potential original cutmix issue:
When coding cutmix, I’ve realized there’s a potential issue with the calculation of λ (% of the image and label mixed).
The calculated area to mix falls partially outside the image sometimes, and it’s clipped out, but the λ value is not corrected. This means that the % of image modified and the % of label don’t match. I’ve added a parameter true_λ that fixes the issue (by default it’s now set to true, which means that the modified cutmix version is used. If you want to use the original cutmix version just use: cutmix(true_λ=False)
@oguiza - this looks fantastic! thanks for coding this up and sharing.
(You just saved me half a day as I had cutmix on my todo list, plus nice bonus of adding ricap which I had no plans to do lol.)
re: potential original cutmix issue - that’s a great catch, thanks for fixing.
I’ll be using both of these shortly for a project I’m working on.
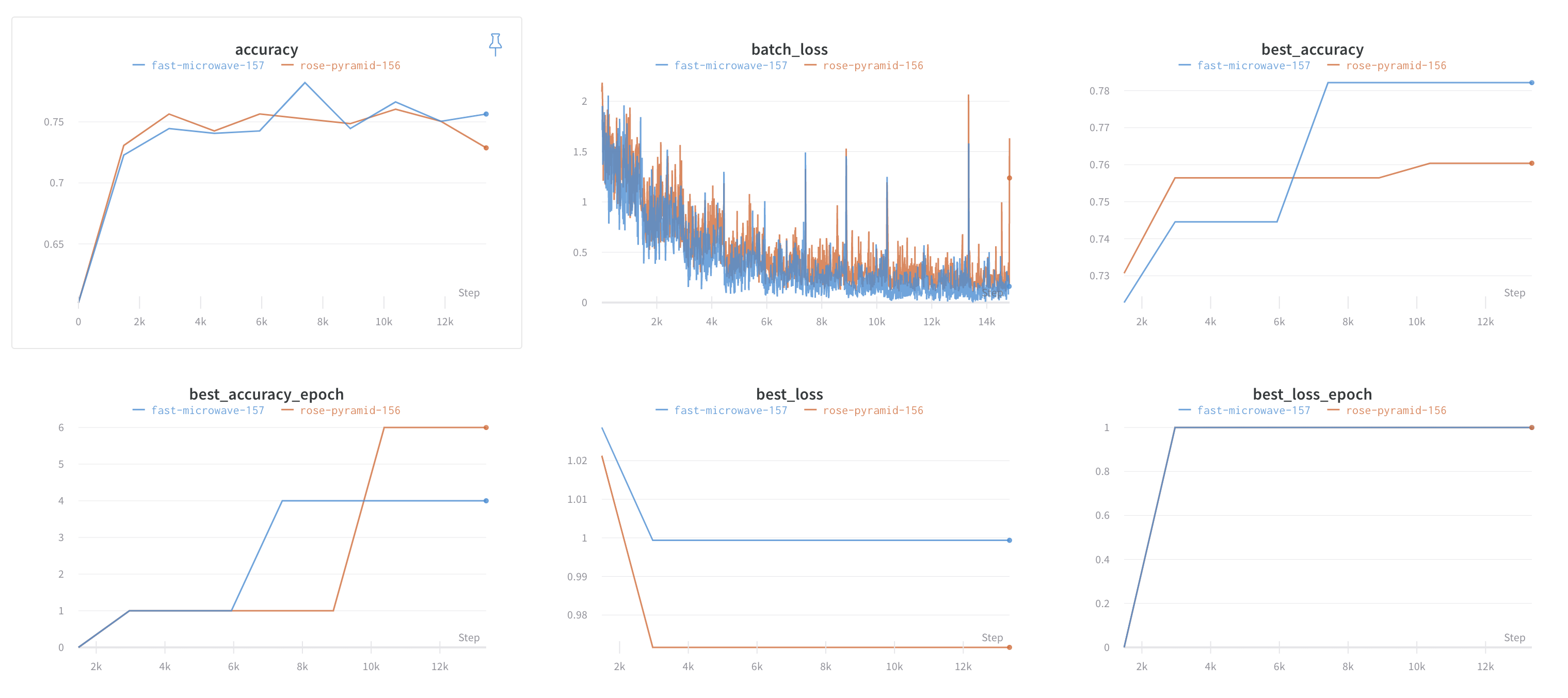
Will be interesting to see if ricap does better/worse/same - I will try to run on imagenette for 10 epochs each to see if any diff can be spotted as a controlled test.
That’d be interesting, although I doubt you’ll find any improvement with so few epochs. Jeremy seems to have found an improvement using mixup for 80 epochs.
Ah sorry I assumed you already had one, since there’s a “do not edit” comment at the top saying it’s from a notebook. I guess it must just be carried over from another file.