i’m having a go at implementing u-net on a custom dataset. I wanted to sense check a couple of things i have done.
My directory structure is basically:
-master
-original images
masks (binary pixelwise anotations)
I have not made a codes.txt file as i felt like i can pass the codes in an array and as i only basically have two classes i thought it would be easier?
Also i’m not 100% convinced im handling the “void” category in the right way
Finally - as i dont have a list of images for validation for the valid.txt file like camvid did, instead i thought i could handle this by calling .split_subsets(train_size=0.8, valid_size=0.2)
If your masks are binary, there is no need for 3 classes. You either use object of interest + background or you set only object of interest, which saves up a bit of redundancy memory wise but breaks methods such as show batch.
ok thats fine and it seems to be running, although now i keep hitting a cuda out of memory error which seems unusal because i wasnt before this? I tried downsizing the batch size to 2:1 and still no joy?
hmm yeah so definitely seems to be consitently happening.
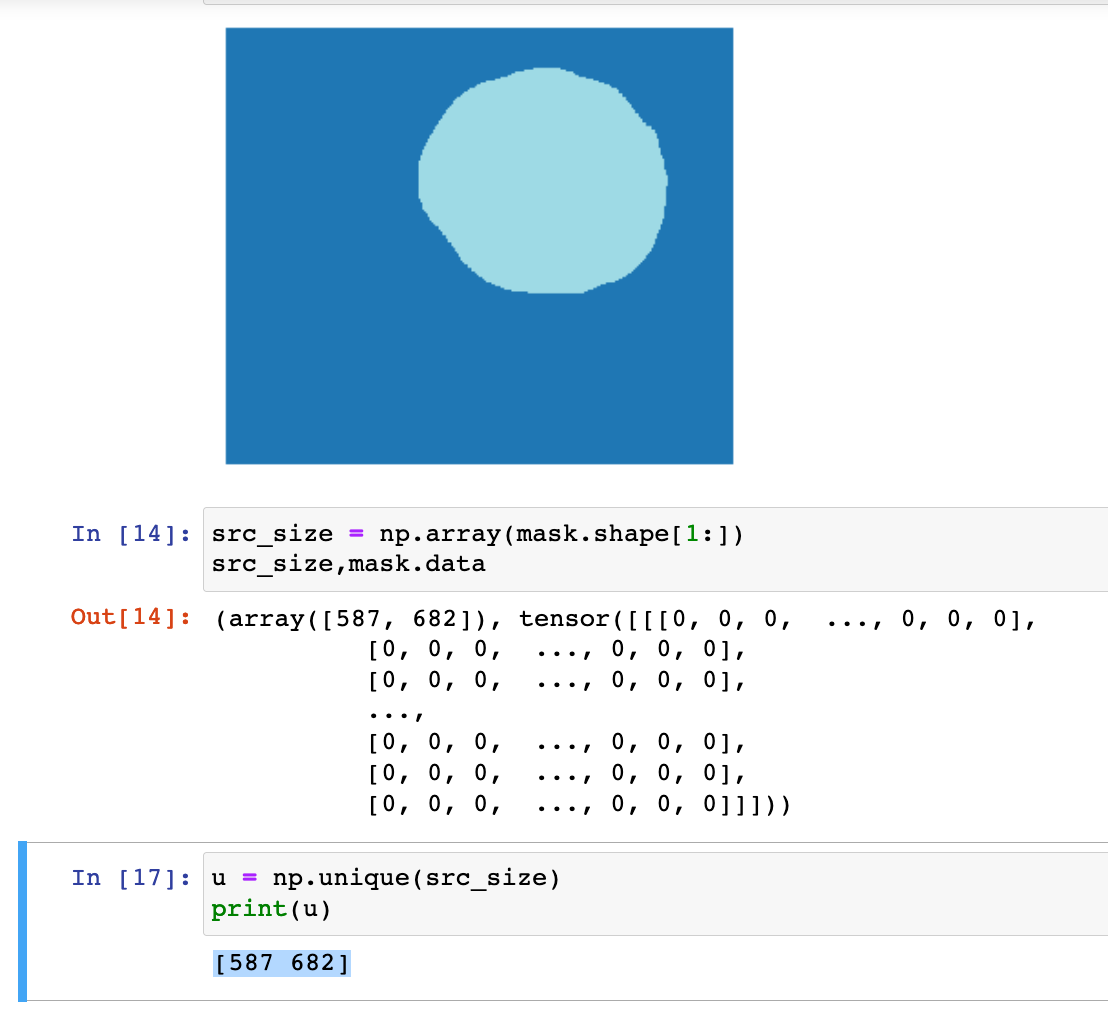
the image size quoted here is 587 682, however there is variety in the size of the image dimensions within the dataset. I think i probably need to control for that as a good habit too?
It looks to me like U net can accept images that vary in size…
Although im not sure on this implementation. Also, i remember reading that u-net images must be divisable by 2 so i wonder if thats complicating things somewhere, although i would have expected it to through at issue when i resized them earlier in the code.
Does the out of memory error happen at the same time every time you train/run? For example 4th batch? - Because if it does I would try to set a trace before it occurs and check out the shape of the batch and such.
yeah, its happening pretty consistently. I havent actually ever done that before - normally i just try and debug based around the error code. Is there a function to do it in pytortch? I will look it up now and thanks for the suggestion too!
Well if your images have variety in size you won’t see any errors till it tries a big image that would cause you not have enough memory as input. Find largest image (width * height) and input that to the model, it should give you the out of memory exception. Then try resizing it until you are fine, then add that size as either a random crop or resize
Ok @juvian so yeah there is a whole variety of sizes in the original dataset, for instance 841 × 696 however looking at the shape of the data there is another issue. The nature of the way the images are presented is not uniform so some are square, some are rectangles. Of the rectangles some have a longer edge horizontally, others vertically. I will see if i can figure out a solution, i might be able to just rescale everything down keeping the same dimensions.
Solved it! It was actually a problem with my directory structure - i had used a linux command which hadnt shuffled a couple of files around properly. Schoolboy error ! Thanks @juvian and @Hadus - i learned some new things about GPU memory management in the process.
Have a question for you guys - once you get the segmented object, how would you go about measuring the dimensions, if that was the goal? I have tried open CV, but that didn’t work and I couldn’t figure out a way to get the images flowing through the code (had to do segmentation, then move to open cv). Any elegant solutions you guys can think of?

 ?
?