Hey guys,
Getting back to learning neural networks recently.
I am trying to make a neural network that has to take a decision. At any given hour, I want to predict if the blue number is going to be greater than the orange number:
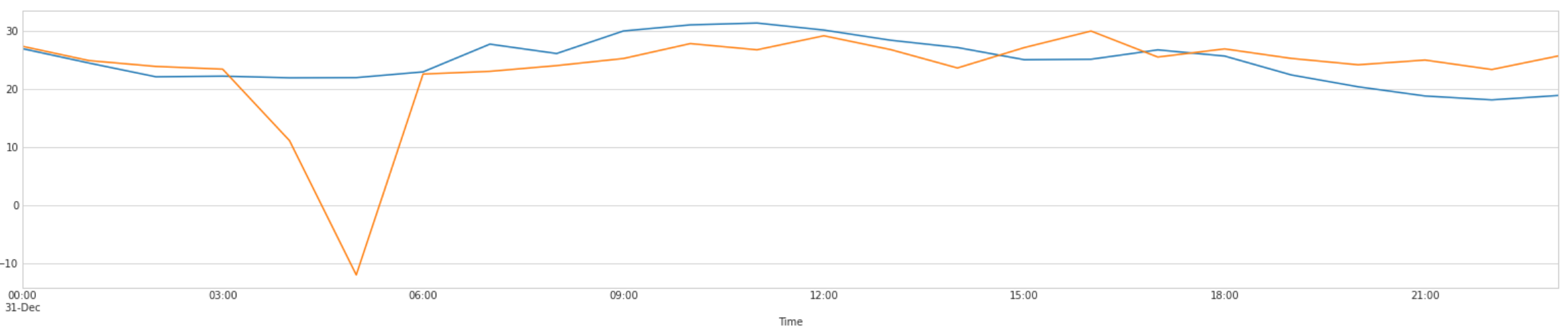
If the network predict correctly the sign of the difference, it reaps a reward equal to the difference. If it is wrong though, it would get punished by a penalty equal to the difference. For example if orange = 5 and blue = 10 and you predict Positive, you would get +5$ as a reward since blue - orange == 5. If you predicted Negative though you would get -5$. Plus there’s fixed costs for doing a prediction, 0.2$ for a positive prediction, 1.2$ for a negative prediction.
I would also like the network to be able to decide to do nothing if it is not certain enough. The cost of being wrong is pretty steep and also each time you do a prediction there’s a fixed cost. So ideally I would prefer not to do anything if the network is not sure enough.
The network must choose between three choices:
- Do nothing
- Bet negative
- Bet positive
I want to make a custom loss function that take this into account.
I have a tabular model that outputs 3 outputs. I pass that to softmax, which gives me a tensor of probabilities the model assign to each choice…
Here is my first crack at it:
class ProfitLoss(Module):
def forward(self, out, targs):
# out is a tensor [batch, 3] where [:,0] == do nothing, [:,1] == Bet negative, [:,2] == Bet Positive
# we do softmax on it, which returns probability for each choice that sums to 1
out = torch.softmax(out, dim=1)
# targs is the difference between orange and blue and it is the target in my dataloader
# we multiply it by [0,-1,1], so if target == 500, then targs becomes [0, -500, 500]
targs = targs * torch.tensor([0, -1, 1], device='cuda')
# we multiply it by the probabilities, let's say [0.2, 0.6, 0.2] * [0, -500, 500] = [0,-300, 100]
loss = out * targs
# We add our fixed cost per prediction, 1.2$ for negative, 0.2$ for positive and 0$ for doing nothing
loss += torch.tensor([0, -1.2, -0.2], device='cuda')
# I sum on the first axis, [0, -300, 100] = [-200] so I would lose 200$ here
loss = loss.sum(axis=1)
# We make this negative because we are calculating gains, but we want to minimize the loss
return -torch.mean(loss)
How could I make this better? My gut feeling is that multiplying it by the tensor [0, -1, 1] probably cause gradient problems in the first position because we are multiplying by zero…
Any pointers to literature that could be interesting to learn more or any tips would be appreciated!
Thanks a lot!