Ah yes, MixedItemList doesn’t support export, that’s true. I need to change its default constructor and add a factory method to create it with item_lists. Will try today but might not have time.
2 Likes
If you get something working today let me know I will try to finish my notebook this week-end! I am getting a really good Kappa score on my validation set compared to the public leaderboard… But I want to test a submition on Kaggle before celebrating :).
Ok, that was way easier than I expected, just a matter of checking for an empty list. Can you double-check it works?
Thanks for the quick fix! Unfortunately it didnt work. I had an exception about something unrelated from something you changed in commit 05ef336ba7e621009ec0eee9b8d1e6d651d01ff9. I had to remove the archive=False argument from this function in the datasets.py file for my code to run:
modelpath4file(name, ext=ext, archive=False)
Then also you forgot a item_lists[0].path later in the MixedItemList constructor. When item_list is empty, it crashed there. So I removed that to test more. I am refering to this line:

Now if I simply call:
learn = load_learner(path, 'mixed.pkl')
it executed without any exception. But as soon as I add the test parameter, it crashed somewhere else.
So this code:
imgList = ImageList.from_df(petsTest, path=path, cols='PicturePath')
tabList = TabularList.from_df(petsTest, cat_names=cat_names, cont_names=cont_names, procs=procs, path=path)
textList = TextList.from_df(petsTest, cols='Description', path=path, vocab=vocab)
norm, denorm = normalize_custom_funcs(*imagenet_stats)
mixedTest = (MixedItemList([imgList, tabList, textList], path, inner_df=tabList.inner_df))
learn = load_learner(path, 'mixed.pkl', test=mixedTest)
Result in the following exception:
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
in
----> 1 learn = load_learner(path, ‘mixed.pkl’, test=mixedTest)
2 # mixed.add_test(mixedTest)
3 # data = mixed.databunch(bs=bs, collate_fn=collate_mixed)
4 # data.add_tfm(norm) # normalize images
c:\work\ml\fastai-dev\fastai\fastai\basic_train.py in load_learner(path, file, test, **db_kwargs)
596 model = state.pop('model')
597 src = LabelLists.load_state(path, state.pop('data'))
--> 598 if test is not None: src.add_test(test)
599 data = src.databunch(**db_kwargs)
600 cb_state = state.pop('cb_state')
c:\work\ml\fastai-dev\fastai\fastai\data_block.py in add_test(self, items, label)
548 if label is None: labels = EmptyLabelList([0] * len(items))
549 else: labels = self.valid.y.new([label] * len(items)).process()
--> 550 if isinstance(items, ItemList): items = self.valid.x.new(items.items, inner_df=items.inner_df).process()
551 else: items = self.valid.x.new(items).process()
552 self.test = self.valid.new(items, labels)
c:\work\ml\fastai-dev\fastai\fastai\data_block.py in new(self, item_lists, processor, **kwargs)
778 copy_d = {o:getattr(self,o) for o in self.copy_new}
779 kwargs = {**copy_d, **kwargs}
--> 780 return self.__class__(item_lists, processor=processor, **kwargs)
781
782 def get(self, i):
c:\work\ml\fastai-dev\fastai\fastai\data_block.py in __init__(self, item_lists, path, label_cls, inner_df, x, ignore_empty, processor)
766 x:'ItemList'=None, ignore_empty:bool=False, processor=None):
767 self.item_lists = item_lists
--> 768 default_procs = [[p(ds=il) for p in listify(il._processor)] for il in item_lists]
769 if processor is None:
770 processor = MixedProcessor([ifnone(il.processor, dp) for il,dp in zip(item_lists, default_procs)])
c:\work\ml\fastai-dev\fastai\fastai\data_block.py in <listcomp>(.0)
766 x:'ItemList'=None, ignore_empty:bool=False, processor=None):
767 self.item_lists = item_lists
--> 768 default_procs = [[p(ds=il) for p in listify(il._processor)] for il in item_lists]
769 if processor is None:
770 processor = MixedProcessor([ifnone(il.processor, dp) for il,dp in zip(item_lists, default_procs)])
AttributeError: 'int' object has no attribute '_processor'
Looking at the code in load_learner, we use the add_test function. In the add_test function we call
if isinstance(items, ItemList): items = self.valid.x.new(items.items, inner_df=items.inner_df).process()
Which basically try to construct a MixedItemList with a list of items instead of a list of item_list I think.
I hope this helps!
Thanks,
Pushed a fix for this too.
Hum now getting this exception:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-13-f0c43dff015f> in <module>
----> 1 learn = load_learner(path, 'mixed.pkl', test=mixedTest)
2 # mixed.add_test(mixedTest)
3 # data = mixed.databunch(bs=bs, collate_fn=collate_mixed)
4 # data.add_tfm(norm) # normalize images
c:\work\ml\fastai-dev\fastai\fastai\basic_train.py in load_learner(path, file, test, **db_kwargs)
596 model = state.pop('model')
597 src = LabelLists.load_state(path, state.pop('data'))
--> 598 if test is not None: src.add_test(test)
599 data = src.databunch(**db_kwargs)
600 cb_state = state.pop('cb_state')
c:\work\ml\fastai-dev\fastai\fastai\data_block.py in add_test(self, items, label)
548 if label is None: labels = EmptyLabelList([0] * len(items))
549 else: labels = self.valid.y.new([label] * len(items)).process()
--> 550 if isinstance(items, ItemList): items = self.valid.x.new(items.items, inner_df=items.inner_df).process()
551 else: items = self.valid.x.new(items).process()
552 self.test = self.valid.new(items, labels)
c:\work\ml\fastai-dev\fastai\fastai\data_block.py in new(self, item_lists, processor, **kwargs)
779 copy_d = {o:getattr(self,o) for o in self.copy_new}
780 kwargs = {**copy_d, **kwargs}
--> 781 return self.__class__(item_lists, processor=processor, **kwargs)
782
783 def get(self, i):
c:\work\ml\fastai-dev\fastai\fastai\data_block.py in __init__(self, item_lists, path, label_cls, inner_df, x, ignore_empty, processor)
769 default_procs = [[p(ds=il) for p in listify(il._processor)] for il in item_lists]
770 processor = MixedProcessor([ifnone(il.processor, dp) for il,dp in zip(item_lists, default_procs)])
--> 771 items = range_of(item_lists[0]) if len(item_lists) >= 1 else []
772 if path is None and len(item_lists) >= 1: path = item_lists[0].path
773 super().__init__(items, processor=processor, path=path,
c:\work\ml\fastai-dev\fastai\fastai\core.py in range_of(x)
203 def range_of(x):
204 "Create a range from 0 to `len(x)`."
--> 205 return list(range(len(x)))
206 def arange_of(x):
207 "Same as `range_of` but returns an array."
TypeError: object of type 'int' has no len()
Looking with the debugger, item_lists is a list of integers (probably items.items from my MixedItemList).
Ah yes, add_test won’t work with MixedItemLists since it’s not passing the separate itemlists. I think you will need to copy-paste the code of add_test and monkey-patch it for your use case.
Alright thanks for your help!
What would be the easiest way for me to test my model on data that don`t have any labels? Could I use something else in fastai? Maybe there’s something else like using the test data as the validation set or something like that?
Thanks! 
Just change the function to include item_lists=items.item_lists in the call to new and you should be good.
Glad to see someone else working on PetFinder comp by combining different data together! I participated on that competition as well but only combined text and tabular (and get cnn features from a different model) but the model is sensitive and hard to train so I end up just train tabular NN. Looking forward to your post on combining all three!
I started working a little bit too late on it… Did not submit anything on the real competition. And now I can’t test on the public leaderboard, submissions seems closed. This is my first competition so I would have liked testing it on the competition test set because the performance I am having seems too good to be true.
I am having 0.950 quadratic kappa score on a 10% validation set and the best team on the public leaderboard is 0.502 quadratic kappa score…
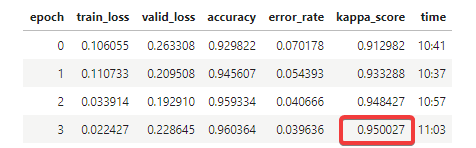
I haven’t done any cross-validation and this is my first competition so I am remaining cautious… I would really like to make a submission on the test set before releasing anything to see if the performance I am having generalize.
Yeah it seems too good to be true. The best kappa score using neural net I achieve on this dataset is 0.41 and I used 5 fold strategy based on RescuerID. What is your validation strategy? Do you pick random 10% from the set? Do you do any type of feature engineering?
Indeed this seems too good to be true… I don’t have enough experience in data science to be 100% sure. I thought maybe I was not using the KappaScore from fastai correctly.
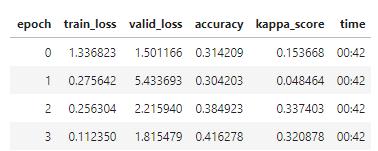
But then I tested this morning with a tabular_learner, with only loading the csv with tabular data from the train.csv file from the competition and got around 0.32 quadratic kappa (without even processing the sentiments files).
But then for my model using image, tabular and text, I created a dataframe where I have one row per image and I also parse the sentiment files for each PetID. Each row contains all the tabular information for the pet that this picture belongs to. So basically pets that have more than one photo have more rows in the training dataset basically giving more weight to the pets with more photos. The csv has 14993 rows, but joined with the pictures, the dataset now has 58311 rows (there’s 58311 pictures in train_images).
But now my validation set has potentially multiple prediction for a single PetID, so I just average the prediction per PetID and round them to the nearest AdoptionSpeed.
Using that even with just a tabular_learner, I get around 0.9329 kappa score.
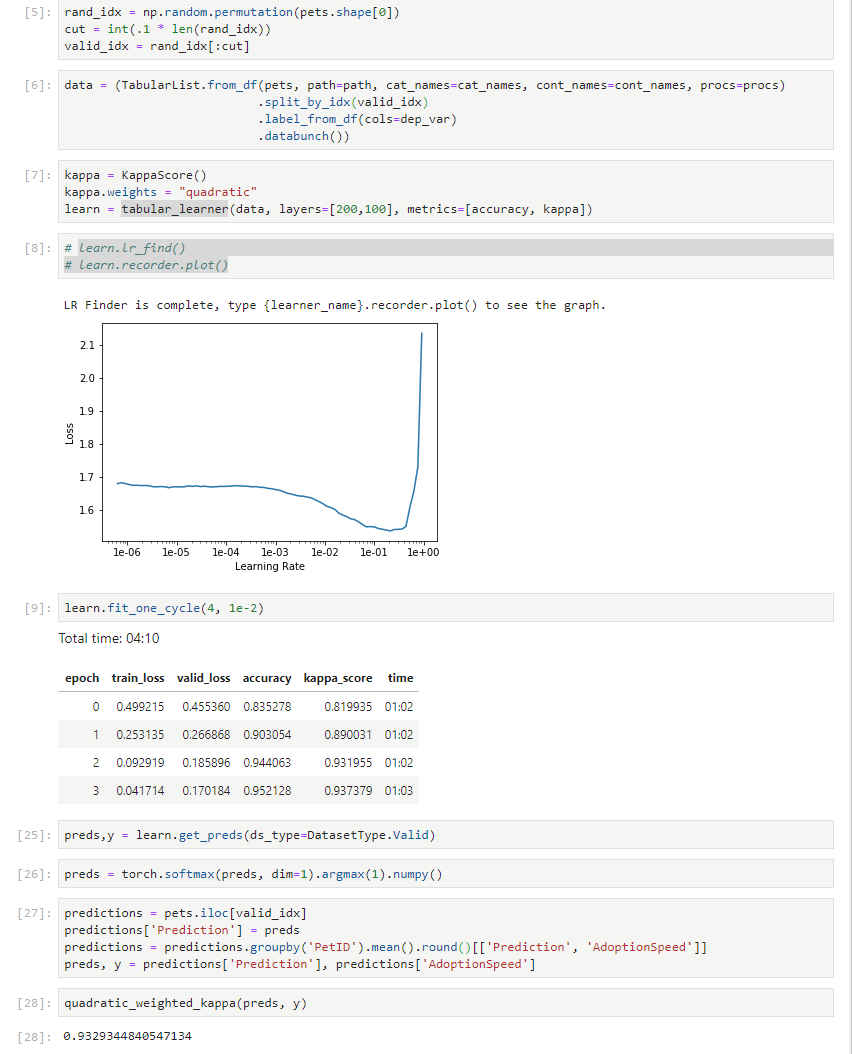
I used the method quadratic_weighted_kappa from this notebook to test something different than fastai KappaScore…
So I am not sure if what I am doing is correct or not.
I think I know what went wrong with your validation approach. Because you upsample the dataset by duplicating tabular data to pets with several images, and you pick 10% random from the upsampled data to be your validation set, there is a high chance that data related to one pet got shared between train and validation set (e.g.: pet A has 10 images so you create 10 rows for him, first 8 rows got into train set, last 2 are in valid set). This is known as ‘leaking information from training set into validation set’, and this could be worse since the only difference between 10 rows are the images (the tabular rows are copied).
You can pick a better validation set by making sure validation set has complete different pets from training set (or ideally, different rescuer IDs, as I remember the test set in that competition has a complete different set of rescuer IDs)
1 Like
Makes complete sense! I will fix my code tonight!
1 Like
For anyone interested, I published a notebook showing an example on how to use MixedItemList:
2 Likes
Etienne,
I am getting the same error on my toy dataset on windows before I upload (using a custom_itemlist (and as you say I did not get the error when not using that custom itemlist).
I am working in a jupyter notebook, and tried to put
if __name__ == '__main__':
Before calling
lr_find(learn)
learn.recorder.plot()
But, still get the same error
Could you explain the “…code doing the training loop…” (i.e. specifically where did you put "if name==‘main’: ?
Yeah I had to put some of my code in a separate file (that I import in the notebook) for the Python multi-process to be happy… If the code was in the notebook it was not happy and threw this error.
Thanks Etienne, much appreciated. I was able to put num_workers = 0 and accomplish as you describe. Thank you very much.
Yeah num_workers=0 fixes it, but then you lose multi-processing… Depending on your application this could be fine, but if you are processing images, this will be much much slower.